サポートマネージャーオンコールのやり方
はじめに
サポートマネージャーオンコールは、GitLab 顧客に質の高い体験を提供する上で発生する緊急かつ重要な状況に対応するためのコーディネーションを支援します。
サポートマネージャーオンコールは、GitLab Support オンコール を構成するローテーションの1つです。
サポートマネージャーオンコールへの期待
GitLab Support オンコール の一環として、サポートマネージャーはローテーションで担当します。サポートマネージャーオンコールは、一般的に以下の責任を負います。
- 顧客の緊急事態が SLA に従って 迅速かつ正確に処理されること を保証する
- グローバルサポート時間 中の Support Ticket Attention Requests の処理
- セキュリティインシデントの通知ポイント として活動する
- Account Escalation の Support Manager DRI を見つける
- SLA 違反の回避を支援する。詳細は チケット対応 を参照。
注: あなた(または CMOC/CEOC)が、別の GitLab チーム(SIRT チームなど)を代行して GitLab ユーザーに連絡を取らなければならない場合があります。これらのリクエストに対応するには 通知送信ワークフロー に従ってください。
顧客の緊急事態とインシデントの処理
サポートエンジニアオンコール は、顧客の緊急事態に最初に対応する役割です。マネージャーは次のようにこの作業をサポートします。
- 見逃された緊急ページの次の階層のエスカレーション先として行動する(PagerDuty から自動的に通知されます)。
- 新しい緊急リクエストには、オンコールエンジニアが 緊急リクエストのトリアージ を行うのを助けることで対応する。
- リクエストが緊急として認められないと顧客に伝える などの困難な顧客コミュニケーションでオンコールエンジニアを支援する。
- 進行中の緊急事態を把握し、必要に応じて初期対応を支援またはリードする。
- 緊急事態の最中: 専門知識を持つ追加スタッフを見つける、必要に応じてオンコールエンジニアを交代する、必要に応じて Zoom 通話をリードする、次のオンコールマネージャーに緊急事態を引き継ぐ。
- 複数の緊急事態 があるときに追加のスタッフを見つける。
- 必要に応じて 顧客緊急事態を Account Escalation に変換 する。
- インシデントが Support による非標準のワークフローやコミュニケーションを必要とする場合、CMOC は Support Response を調整すべきです。Support または他チームの関連する意思決定者との明確さとコミュニケーションを確保することで CMOC をサポートしてください。まだ作成されていない場合は、Support Response Issue を作成することもできます。
緊急事態かもしれない、または緊急事態ではないかもしれない状況
時々、まだ完全には緊急事態ではないものの、すぐにそうなりうる状況に対して緊急ページが届くことがあります。このような状況では、私たちは状況が緊急事態にならないよう、顧客を支援したいと考えています。この状況が業務時間中に発生した場合、サポートエンジニアオンコールが支援を求めることがあります。オンコールマネージャーは、即時対応を要する high 優先度のチケットとしてリクエストを処理する追加スタッフを見つけて対応すべきです。週末にこの状況が発生し、サポートエンジニアオンコールが別の緊急事態を処理している場合、オンコールマネージャーに連絡します。その場合、オンコールマネージャーは支援するか、支援する追加スタッフを見つけようとすべきです。
緊急事態かもしれない状況の例 と 緊急事態ではない状況 を参照してください。
APAC 週末のバックアップエンジニアの呼び出し
APAC 地域には バックアップエンジニア のプールがあり、週末オンコール時間帯に同時に緊急事態が発生した場合に連絡できます。
あなたがサポートマネージャーオンコールで、同時に緊急事態が発生した場合、PagerDuty 経由でエスカレーションされたサポートエンジニアオンコールからページがかかります。あなたはその後、現状を確認して バックアップエンジニア にページを送る必要があるか判断する責任があります。必要な場合、サポートマネージャーは バックアップエンジニア に 手動でページを送ります。この時点で、すべてのバックアップエンジニアに通知が送られます。バックアップエンジニアの1人だけがページを認識して支援を貸せばよく、バックアップエンジニア がページに応答する義務はありません。
バックアッププールにページを送るには、以下の方法があります。
- 任意の Slack チャンネルで
/pd triggerコマンドを使い、現在のサポートエンジニアリストに通知する新しいインシデントを作成する。または、 - PagerDuty で直接
+ New Incidentを作成する。
プロンプトが表示されたら、以下を更新します。
- Impacted Service: Customer Emergencies - APAC Backup Pool
- Title: Duplicate emergency - ZD#123456
- Description: 緊急事態の簡単な要約を提供する。
- Assign To: と Priority: は空欄のままにします。
詳細は STM#4583 を参照してください。
業務時間中の Support Ticket Attention Requests の処理
STAR (Support Ticket Attention Requests) はサポートマネージャーオンコールが処理します。
あなたの責任は次のとおりです。
#support_ticket-attention-requestsSlack チャンネルでアナウンスされた顧客チケットおよび内部リクエストをトリアージし調査する。- スター付きチケットのオーナーシップとアサインを確立する。
Support Team Skills by Subject を使って、適切なエンジニアを見つけてアサインできます。
スター付きチケットの非常に高い割合がライセンスと更新に関わるものです。これらの処理に関するガイダンスは Plan/License Ticket Attention Requests のワークフロー を参照してください。
注: GitLab チームメンバーは、通常のサポート Slack チャンネル(#support_self-managed、#support_gitlab-com、#support_leadership)でチケットへの注意を引こうとすることがあります。チームメンバーには、その投稿に :escalate: 絵文字のみで 返信することでリダイレクトしてください。これにより、正しいプロセスを説明する自動かつ匿名の返信が送信されます。
注: このページでは扱っていない別の状況が2つあります。
スター付きチケット処理の仕組み
STAR 対応の一部のステップはボットと自動応答機能で処理されます。以下では、これらのステップを示すために **BOT** という記述を使用します。
- 誰かが STAR フォーム を使って STAR を起票したとき:
- BOT: STAR Issue トラッカー に新しい Issue を作成する。
- BOT:
#support_ticket-attention-requestsに Slack アナウンスが投稿される。現在のオンコールサポートマネージャー名を@mentionで付ける。 - 多くの場合、BOT が Zendesk チケットと STAR Issue に内部ノートを追加する。
- STAR を確認していることを示すため、Slack スレッドに
:eyes:絵文字を追加する。 - Zendesk チケットでは、
Support::Managers::STAR Escalated Ticketマクロを使用して STAR Issue とディスカッションスレッドを相互リンクし、チケットにタグを付ける。 - チケットと、リクエストを正当化するビジネスケースを評価する(トリアージ)。
- 起票者への質問は Slack(同期)または STAR Issue(非同期)に置けます。
- Slack の履歴は消えるため、最終的な処置は STAR Issue に文書化すべきです。
- エンジニアからの入力や助けが必要な場合、
#support_gitlab-com、#support_self-managed、または#support_licensing-subscriptionで新しいスレッドを開始する。- その日に作業しているなら、アサインされたエンジニアと、以前にチケットに返信した任意のエンジニアを @mention する。
- その後、
#support_ticket-attention-requestsのスレッドに戻り、すべての 技術的 ディスカッションがチケット(または新しいスレッド)で行われていることをコメントする。これによりすべての技術的ディスカッションが1つのチャンネル/スレッドに留まることが保証されます。 - DRI として行動する、またはチケットを前進させるエンジニアを探す際は、オンコールでなく、すでにスター付きチケットに取り組んでいないサポートエンジニアを特定するのがベストです。これにより、新しいスター付きチケットを支援するエンジニアが、それを優先するための十分な余力を持つことが保証されます。
- STAR スレッドを解決する。
チケットのスター解除 - 追加の注意リクエストの拒否
STAR が追加の注意の閾値を満たさない場合があります。詳細は STAR メインページ を参照してください。そうした状況では、#support_ticket-attention-requests のスレッドに戻り、起票者に通知してください。
STAR の解決
STAR は、正しい次のステップが特定され進行中になった時点で解決済みとみなされます。Zendesk チケットが Solved または Closed である必要はありません。
STAR が解決されたとき:
#support_ticket-attention-requestsの通知に:green-check-mark:絵文字を付ける。- 関連する STAR Issue を適切なコメントで更新し、Close する。
- 傾向の分類と追跡に役立てるため、以下のスコープラベルの例のような適切なラベルの適用を検討する。
~Escalation::License-Issue: 中心的な問題がライセンス/サブスクリプションに関わるものであることを示す~Escalation::Response-Time: リクエストの目的が問題やケースへの応答を急がせることである場合に有用
Account Escalation の Support Manager DRI を見つける
サポートの関与が必要な Account Escalation が発生した場合、サポートマネージャーオンコールには Lead Support Manager を見つける責任があります。これが ASE アカウントの場合(org notes で確認可能)、Lissa Roberts (AMER)、Ilia Kosenko (EMEA)、または Wei Meng Lee (APAC) に連絡してください。
業務時間中のチケット中間フィードバックでマネージャーへの連絡を求められた場合の処理
チケット中間フィードバックリンク – GitLab Support エンジニアまたはマネージャーからのすべての公開コメントには、チケットがオープン中に顧客がフィードバックを提供したり、マネージャーからの連絡を要求できるフォームへのリンクがあります(Issue 2913 で導入)。 このフィードバックフォームは customer feedback プロジェクトに Positive/Negative/Neutral feedback for ticket nnnnnn という件名形式の Issue を作成し、チケットにアサインされたエンジニアのマネージャーに、またはアサインがいない場合は Support Director の Val Parsons に自動的にアサインされます。Issue に加え、Slack 通知が #support_ticket-attention-requests チャンネルに送信されます。 サポートマネージャーオンコールは速やかに次のアクションを取るべきです。
フィードバックが既存のチケットに関連している場合:
- フィードバックとチケット情報を確認し、応答にどれだけの緊急性が必要かを検討する。できるだけ早く返信することで、さらなる顧客の不満や STAR、緊急事態を防ぐことができます。
- 緊急性を念頭に置いて、アサインされたエンジニアのマネージャーがアクションを取るべきか、オンコールマネージャーが取るべきかを決める。
- フィードバックが即座の対応を要する場合、適切に応じてチケットまたはメールで返信し、次のステップを共有し、ビデオ通話をスケジュールするための Calendly リンクを提供する。
- チケットが軌道に戻るまで DRI として留まる。
- Feedback Issue を以下のように更新する:
- やり取りの内容を Feedback Issue にコメントとして追加する。
- ~ssat-manager-contacted-customer ラベルを適用する。
- Feedback Issue を /close する。フォローアップは以前に選んだコミュニケーション手段で続けます。
- Issue を Close した後、顧客とのやり取りから追加のアクションが生じた場合、Feedback Issue に戻ってメモする。
チケットリンクがなく、一般的なサポートフィードバックの場合:
- Issue は自動的に Val Parsons にアサインされます。DRI として自分にリアサインしてください。
- フィードバックを確認し、次の最善のアクションを検討する。
- 顧客が通話を希望する場合、ビデオ通話をスケジュールするための Calendly リンクを提供する。
- フィードバックが Product や他のチーム向けである場合、適切なチャンネルで共有する。
- 顧客とのやり取りから追加のアクションが生じた場合、Feedback Issue に戻ってメモする。
セキュリティインシデントの通知ポイントとして行動する
GitLab で セキュリティインシデント が発生した場合、サポートマネージャーオンコールはセキュリティインシデントから生じる顧客コミュニケーションのトリアージと対応に責任を負います。これには CMOC の関与が含まれる場合があります。
アップグレード支援リクエスト は、現在 チケット対応 の一環としてエンジニアによってトリアージされていますが、場合によってはトリアージするエージェントが Support 管理者の支援を必要とする場合があります。
状況の例と潜在的な解決策
- GitLab Support 時間 外でのアップグレード支援を求めるユーザー
- 部下に、要求された日時に対応するために勤務時間をシフトする意思があるか確認する
- エンドユーザーと協力して、サポートスタッフのスケジュールに沿った別の日時に再スケジュールする
- 担当エンジニアの直前のキャンセル
- 利用可能なチームメンバーと協力して、アップグレード支援を新しいエンジニアに引き継げるか判断し、認識合わせのためエンドユーザーに変更を伝える
オンコールシフトの再アサインまたはスワップ
平日に顧客通話などで数時間オンコールに対応できない場合、別のマネージャーに一時的にオンコール責任を引き受けてもらうよう手配します。
- 特定のマネージャーにカバーを依頼する。それがうまくいかない場合は、
#support_leadershipでカバーを引き受けてくれるマネージャーを募集する投稿をする。
オンコール業務を誰かとスワップするには、オンコール業務のスワップ のステップに従います。
手動での PagerDuty 通知のトリガー
時には、顧客が私たちの サポートインパクトの定義 で緊急サポートに該当する状況を報告するエスカレーションを受け取ることがあります。そのような場合、新しい緊急チケットを開くよう顧客に求めるのではなく、緊急事態を直接トリガーすることを選択できます。
Zendesk で Support::Managers::Trigger manual emergency マクロを使用して PagerDuty 通知をトリガーできます。
または、PagerDuty 自体を通じて手動で PagerDuty 通知をトリガーできます。
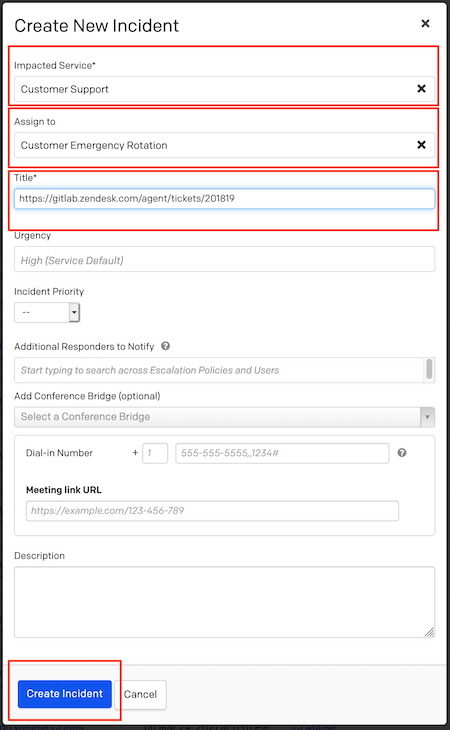
gitlab.pagerduty.com にログインし、右上の + New Incident を選択します。次のようにフォームを記入します。
- Impacted Service: Customer Support
- Assign to: Customer Emergency Rotation
- Title: Zendesk チケット番号をここに追加
他のフィールドは記入する必要がないため、Create Incident をクリックします。
特別な処理ノート
特別な処理ノート は 顧客緊急オンコールワークフロー に記載されています。サポートマネージャーとして、あなたはこれらの(およびその他の)ユニークな状況をご自身の判断で処理する権限が与えられています。 助けやアドバイスが必要な場合は、ためらわずに エスカレートしてブロックを解除 してください。
侵害されたインスタンス
サポートエンジニアには、侵害されたインスタンス の場合、通話を提案する前にサポートマネージャーに連絡することを推奨しています。
これらのケースにおける Support の役割は、顧客が良好な既知の動作状態にできるだけ早く復帰できるよう支援することです。最速のルートは、以前の既知の良好な状態に復元することです(多くの場合、バックアップから復元する)。この状態のインスタンスを持つ顧客には他の懸念があり、おそらく感情が高ぶっている状態にあります。
- どうしてこうなったのか?(私たちが簡単に答えられるかどうか分からない質問で、フォレンジック分析は復元後に行うべきです。)
- 復元せずにどう回復できるか?(「安全に」はできません。私たちは環境への100%の信頼を持つために復元を推奨します。)
- どのデータがアクセスされたのか?(これは常に難しい質問で、侵害が人間によって主導された場合、跡を消した可能性があります。完全な知識を得ることは決してないかもしれません。できるだけ早く復元を始め、フォレンジックは後で行うべきです。)
通話に進むのが正しい場合、エンジニアより 前 に(またはエンジニアの代わりに)通話に参加して、達成可能な範囲を伝えることを検討してください。
私たちが設定する通話(または顧客が主導するブリッジ通話)の例のフレームワーク:
Hi
customer. Based on the ticket it sounds likely that your instance is compromised. In cases like these we’ve prepared a set of best practices (GitLab internal link) to help you get back up and running as quickly as possible. We’re here to support and advise where GitLab is concerned. Unfortunately, GitLab cannot provide a one-size-fits-all solution or comprehensive checklist to completely secure a server that has been compromised. GitLab recommends following your organization’s established incident response plan whenever possible. The first step is to shut down the instance, create a new one at the same version, and restore your most recent backup. This ensures you are operating on a “clean” environment, where you have confidence that all the software installed is unmodified. Please get that process started; we are monitoring this ticket with HIGH priority. If you have any problems getting set up or restoring, please let us know in the ticket immediately. After your new instance is set up, you need to upgrade to a more recent version of GitLab before you expose this server to the public Internet. If you have any trouble with the upgrade process, let us know in the ticket immediately. Finally, as described in the recovery guide previously sent (should have been shared in the ticket via the Compromised Instance Zendesk macro, you should do an audit of the integrity of GitLab itself: checking for any users, code, webhooks, runners or other settings that you did not enable yourselves. If you have any questions, please let us know in the ticket. I’m going to leave the call now, but rest assured that we’re on standby and ready to help as you work through this.
c955a93f)