ユーザーペルソナの作成方法
このハンドブックページでは、ユーザーペルソナを作成するプロセスのみを定義します。
GitLab では、ユーザーのニーズと感情に焦点を当てたデータ駆動型の洞察に基づいて、2 種類のペルソナを作成し使用しています:
ユーザーペルソナ - UX 専門家とプロダクトマネージャー(PM)が、エンドユーザーのニーズ、動機、行動、スキルとつながるためのメカニズムとして使用します。プロダクトマネージャーが所有し、ペルソナ関連のリサーチ活動の DRI でもあります。
バイヤーペルソナ - ユーザーになる可能性のある潜在的な顧客の高レベルな目標に焦点を当てます。マーケティングチームが所有します。
この洞察に富んだUX Collective の記事は、これらの違いやその他について詳しく説明しています。
ユーザーペルソナは、プロダクトマネージャーとプロダクトデザイナーの両方に役立つように開発されます。潜在的な機能の優先順位を理解するため、ユーザーへのコミュニケーションやプレゼンテーションでの共感を高めるため、そしてユーザーの背景を理解することでデザインの選択を形成するために使用できます。各ユーザーペルソナは、長期間にわたってステークホルダーにとって有用な情報のままであるよう、高い精度を持つように作成されます。非常に正確な情報を取得することの重要性のため、各ペルソナの作成プロセスは非常に詳細であり、リサーチに相当な時間がかかる場合があります。
ユーザーペルソナを構成するものは?
GitLab のペルソナページの各ペルソナには、以下の特性が含まれている必要があります:
- ジョブの概要 - 主要な焦点領域と、スキルおよび責任の一般的な説明を含むべきです
- 代替タイトル
- 動機 - 次の形式を維持することをお勧めします: [状況]のとき、私は[タスク]を実行できるように[機能]が欲しい
- フラストレーション - フラストレーションは、ペルソナの責任に対する一般的な障害に焦点を当てるべきです
- Jobs to be Done(最近更新されたペルソナの場合)
(オプション)
- パーソナルスキル&特性 - ユーザーペルソナに生命と共感を与えるポジティブな属性
- 主要なツール - ユーザーがタスクを完了するのに役立つ重要なソフトウェア
- ワークフロー - ユーザーが通常タスクを完了するために行う一連のステップ
- 協働するチーム - 責任の重複がある可能性のある、またはペルソナのワークフローが依存している、組織内のチーム
私たちのSimone(Software Engineer in Test)は、これらの多くの良い例です。
追加の詳細すべてが必要なわけではないため、どれが有用かを知るためにステークホルダーと話し合うことが役立つ場合があります。疑問がある場合、ガイドラインとしては、詳細であるほど良いとされています。
ユーザーペルソナを構築するためのステップ
ユーザーペルソナを構築するプロセスは、ユーザーリサーチを通じて取得されたデータに基づいています。次のステップは、チームが高い信頼度と精度で新しいユーザーペルソナを構築するために必要なデータを提供するように設計されています。
各ステップの開始時と終了時に UX リサーチャーと相談することを強く推奨します。 これにより、活動を開始する際の成功に役立ち、データをレビューするための別の目を提供してもらえます。
ステップ 1: ステークホルダーとのミーティング
ステークホルダーは、自分の作業のプロセスでこのユーザーペルソナを使用する可能性が高いチームメンバーです。理想的なチームメンバーは通常、構築しようとしているペルソナのためのツールの経験を持つソフトウェアエンジニア、プロダクトマネージャー、プロダクトデザイナーなどです。たとえば、セキュリティアナリストのペルソナを構築する場合、ステークホルダーはこれらのユーザー向けのセキュリティツールの構築経験を持つべきです。
このステップの目的は、インタビューで質問する最も重要な情報と、参加者を収集するためのスクリーナーで使用する情報についての私たちの理解を深めることです。
- 問題検証のためのリサーチ Issue を作成し、できる限りテンプレートに記入します。
- 次に、User Persona - Stakeholder conversation [Template]を使用して、自分のペルソナの情報を記入します。
- このシートへのリンクを Issue に配置します。
- このペルソナのフィードバックを求めたいステークホルダーのリストを書き出します。これは理想的には、このペルソナと対話し、対象のユーザーに関する知識を持つ 5 人のチームメンバーです。ステークホルダーに、User Persona Stakeholder Conversation シートの自分のセクションを記入するよう依頼してください。
- このプロジェクトのステークホルダーの 1 人である場合、このフェーズではあまり貢献せず、他のステークホルダーに洞察のほとんどを導いてもらうようにしてください。
- シートに記入するときは、潜在的なペルソナが仕事で直面しなければならない、GitLab との対話に影響を与える可能性のあるさまざまなユースケース、ツール、ジョブの責任、その他何でも考慮してください。
- すべてのステークホルダーが情報を記入したら、Google Sheet の「summary」タブにフィードバックを要約し、結果をリサーチ Issue に書き込みます。
ステップ 2: 内部インタビュー
2 番目のステップは、作成するユーザーペルソナと同じまたは類似のジョブタイトルを持つ 5〜10 人の GitLab チームメンバーをインタビューすることです。このミーティングは約 30 分ですが、より多くの情報が必要な場合は、より多くの時間を確保することをお勧めします。
このステップの目的は、すでに収集された情報を拡張し、理解しようとしている人口と直接対話することです。これにより、適切な参加者に正しい質問をしていることを知るのに役立ちます。
これらのインタビューを実施するには:
- インタビューと結果を追跡するための新しいリサーチ Issue を作成します。
- User Persona - Internal Stakeholder Script [Google Docs Template]を使用し、ペルソナでタイトルと詳細を記入します。
- Google Sheet を Issue にリンクします。
- GitLab team ページ、さまざまな部門チームページ(Engineering ページなど)を使用するか、チームの Slack チャンネル(通常はチームページの下部近くにあります)にメッセージを投稿して、フィードバックのための内部参加者を募集します。
- Calendly リンクを使用して、30 分のインタビューセッションをスケジュールします。
- 各インタビューセッション中に:
- メモを取る必要がある場合、または追加のメモ取り係がいる場合は、user interview notes templateを使用してください。
- インタビューデータを質問ごとに要約し、傾向を探します。何を探すかを導くためにPersona - Screener Questions templateを使用してください。
- 要約された洞察(スクリーナー質問を含む)をリサーチ Issue に文書化し、ステークホルダーにデータをレビューするよう依頼します。
- 以前に実施したリサーチステップ 1に基づいて、傾向がステークホルダーの期待とは異なるかどうかに注意してください。違いがある場合は、どのような仮定がなされたのか、そしてそれを修正する方法を理解するように努めてください。
ステップ 3: より広い GitLab コミュニティのユーザーとユーザーペルソナを検証する
これは重要なステップです!このステップの目的は、内部インタビューから派生した特性を検証して優先順位を付け、私たちの期待と実世界の発見との違いを確立することです。 これらの司会者付きインタビューは約 1 時間かかるはずです。特定のペルソナのために 8〜10 人の参加者を募集し、市場の一般的な構成を反映する参加者に焦点を当てます。これらのインタビューの目的は、ユーザーとつながり、実際のユーザーデータでユーザーペルソナのフレームワークを埋めることです。
A) 参加者の募集とスケジューリング
参加者募集を開始するには、参加者の募集とスケジューリングに関する UX ハンドブックガイドを参照してください。募集 Issue を開き、以前のリサーチステップ 2から派生したスクリーナーを使用します。必要に応じて、効果的なスクリーナー質問の書き方に関するハンドブックページを参照してください。
B) インタビュースクリプトの作成
ステップ 1とステップ 2から作成された要約情報を使用して、外部インタビュー用のスクリプトを作成します。スクリプトの最初のセクションは、ペルソナのトップジョブ、およびそれらのジョブの動機とフラストレーションに焦点を当てるべきです。
GitLab の JTBDに馴染みがない場合は、ここに小さな概要とガイドがあります
- ユーザーの目標
- 使用するツールと素材
- 仕事の成功がどのように評価されているかを理解する
スクリプトの後のセクションは、過去のリサーチが示すペルソナにとって重要なものに応じて異なる場合があります。ペルソナが使用する主要なツール、ペルソナが使用するまたはトラブルを抱える GitLab の領域、またはペルソナに不可欠な作業を提供する他のチームについて質問することがおそらく多いでしょう。
C) インタビューの実施
十分な参加者が募集されスケジュールされたら、インタビューを実施する時が来ました!これらのインタビューに備えるために、ユーザーインタビューを促進する方法に関する GitLab のハンドブックページを理解してください。詳細なヘルプはディスカッションガイドテンプレートにもあります。
インタビュー中のデータ取り込みを合理化するために、このPersona Interview テンプレート(Google Form)をスクリプトおよび参加者の回答を記入するためのツールとして使用できます。
これらのインタビューを実施するには:
- インタビューと結果を追跡するための新しいリサーチ Issue を作成します。
- 以前のリサーチからのデータと共にUser Persona - External Interviews Script(Google Form テンプレート)を使用します。参加者の回答を記録しながらスクリプトを読む方法として、フォーム要素を使用します。
- Google Sheet を Issue にリンクします。
- 各インタビューセッション中に:
- 参加者の名前、職名、職務内容を記録し、各質問を声に出して読み、参加者の回答をフォームに記録します。
- メモを取る必要がある場合、または追加のメモ取り係がいる場合は、user interview notes templateを使用してください。
- Google Form の Response タブでデータを要約するか、sheets export ボタンを使用してデータを Google Sheet にエクスポートします。
- 要約された洞察(スクリーナー質問を含む)をリサーチ Issue に文書化し、ステークホルダーにデータをレビューするよう依頼します。
ステップ 4: 結果の統合と比較
A) ユーザーデータの統合
上記のようにGoogle Form テンプレートを使用している場合、データ統合は各リサーチラウンドで同様のプロセスになります。結果を体系化するためにさらに助けが必要な場合は、データ統合に関するこのハンドブック記事が役立つかもしれません。
すべてのオープンエンドな質問について、まず定性データを理解しやすいものに変換する必要があります。これは、回答をテーマにクラスター化し、すべてのテーマのカウントを集計することで行います。これの例は以下の表で見つけることができます:
| 質問された質問 | 参加者の回答 | テーマ |
|---|---|---|
| 仕事の目標を達成しようとするときに、どのような障害に直面しますか? | 同僚がマージリクエストを送信したことに気づかないことがあり、承認に時間がかかることがあります。 | コミュニケーションの見落とし |
すべてのクローズエンドな質問について、傾向を特定するために、各質問のすべての参加者にわたって各回答が与えられた回数を文書化します。
すべての回答がカウントされたら、各質問に回答した参加者の数を確認し、傾向のデータを評価します。この分析に設定されたルールはありませんが、探すべき傾向には次のようなものがあります:
| 探すべき傾向 | 例 |
|---|---|
| 参加者の 50%以上が少数の回答を選択 | 回答 A: 60% 回答 B: 20% 回答 C: 10% 回答 D: 10% |
| 他と比較した特定の回答の大きな落ち込み | 回答 A: 40% 回答 B: 40% 回答 C: 10% 回答 D: 10% |
B) 結果の比較
各リサーチラウンドを要約しながら、前の参加者の回答を最新の参加者と比較できます。予期しない結果が見られる場合は、違いの理由を理解し、それらを最終的な洞察に組み込むようにしてください。
ステップ 5: マージリクエストを通じて新しいペルソナを公開する
すべてのデータが収集され、要約されたら、Roles & Personas ハンドブックページを更新する時が来ました。
既存のユーザーペルソナの 1 つからテキストをコピーし、現在記入されている最後のペルソナの下に貼り付けます。データを収集したペルソナの情報を編集し、ペルソナの名前とタイトルを含むすべての情報をダブルチェックします。
マージリクエストを、同じ Roles & Personas ページの「Maintained By」セクションにあるマネージャーの 1 人に割り当てます。
ユーザーペルソナを最新に保つ
ペルソナが整合しなくなる最も一般的な方法は、ビジネスまたは技術の変更がある場合、またはユーザーベースに変更がある場合です。この役立つNielsen Norman Group の記事は、違いまたはそれらを認識する方法がわからない場合に、これらの両方について詳しく説明しています。
ステークホルダーが特定のユーザーペルソナがもはや必要な情報を提供していないと信じる場合、または市場データがペルソナに影響を与える変更を示している場合、既存のペルソナを更新するか、新しいペルソナを作成する時です。
2 つ以上のペルソナの結合
元々互いに独立していたペルソナは、役割や職務の変化により、時間の経過とともに区別が少なくなる場合があります。ステークホルダーが 2 つ以上のペルソナの間に重複があると信じる場合、変更を行う前にいくつかのステップに従う必要があります。
- ステークホルダーは、対象のペルソナに関するすべての既知の情報を収集する必要があります。たとえば、これには顧客とのインタビューや、特定のペルソナに関する以前にリサーチされた JTBD ステートメントが含まれます。
- ペルソナに関するすべての既存データをマッピングして、ステークホルダーが一度にすべての情報を視覚化できるようにする必要があります。ペルソナ間の重複の量を評価する 1 つの方法は、ベン図です。
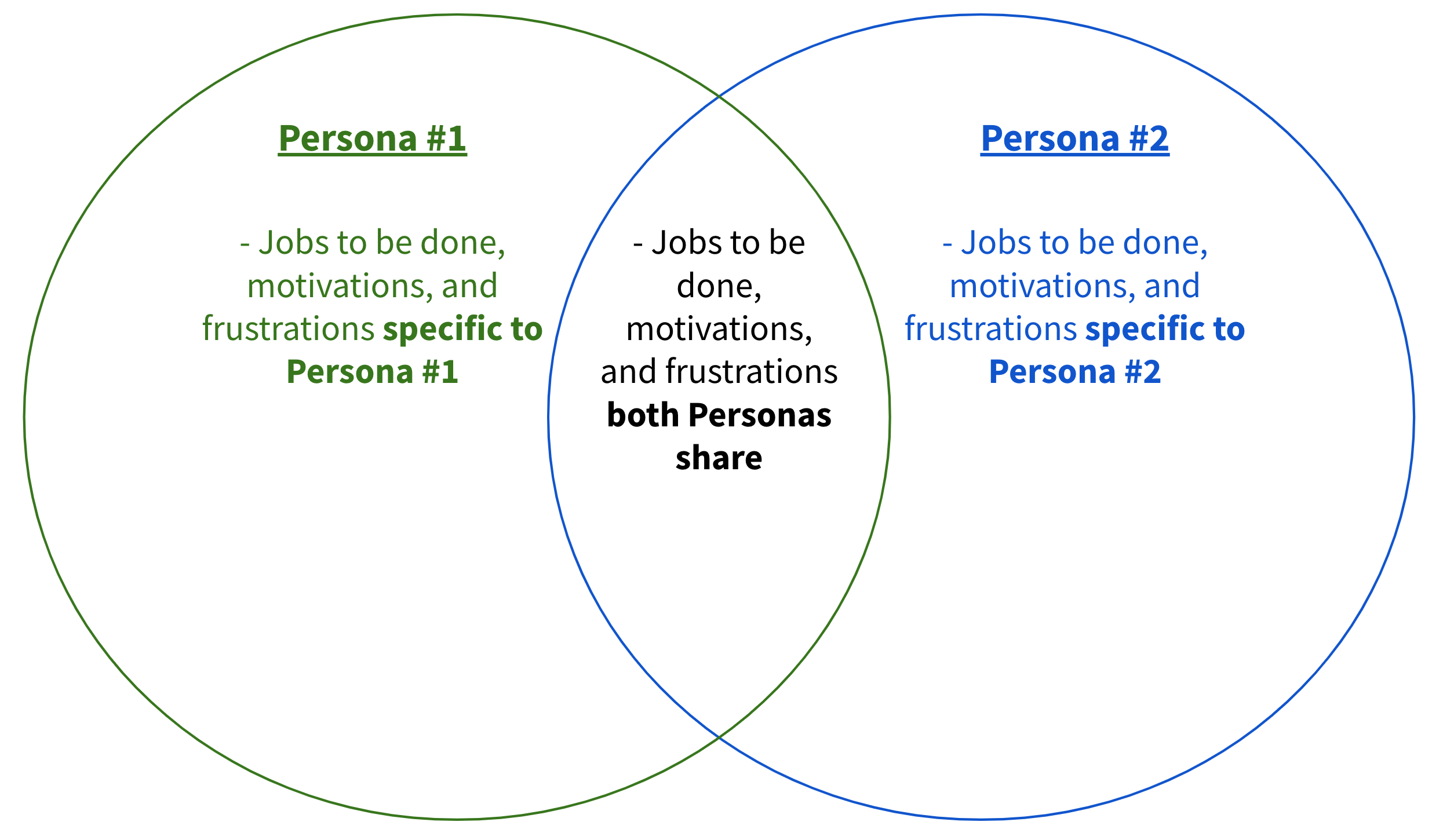
- ベン図を作成する際に従うべき一般的なガイドラインがいくつかあります:
- 対象のペルソナ間で類似する箇条書きの数(つまり、jobs to be done、動機、フラストレーションの合計数)が、異なる箇条書きの数より多い場合、ペルソナを統合できます。
- 対象のペルソナ間で類似する箇条書きの数が異なる箇条書きの数と同じ場合、新しいペルソナを作成できます。
- 対象のペルソナ間で類似する箇条書きの数が異なる箇条書きの数より少ない場合、ペルソナはそのままにできます。
- マッピング演習に基づいて、ステークホルダーはこのマッピング演習の結果について UX リサーチと相談し、どの方向に進むか(つまり、既存のペルソナを統合するか、ペルソナをそのままにするか、新しいペルソナを作成するか)を決定する必要があります。
よくある質問
企業内で使用すべきペルソナの数は?何個が多すぎですか?
企業が持つべきペルソナの「正しい」数はありません。一般的に、ペルソナは互いに十分に区別できるべきであり、1 つのペルソナが別のペルソナと簡単に間違えられないようにするべきです。ペルソナが多ければ多いほど、チームメンバーがそれらについて明確な情報を覚えていない可能性が高まります。企業内のペルソナの数を決定する簡単な方法は、プロダクトでターゲットにしたい最も重要なユーザーグループを特定し、それらのグループに基づいてペルソナを作成することです。
より広いペルソナは、詳細なものよりも良いですか、悪いですか?
ペルソナは、信じられるほど詳細であるべきですが、特定のタイプのユーザーグループを表すのに十分広いものであるべきです。ペルソナに望まれる詳細レベルは、活動の目標に依存します。理想的には、ペルソナは少なくともそれぞれの目標、動機、フラストレーションをカバーするのに十分な詳細であるべきです。
ペルソナはいつ古くなったと見なされるべきですか?ペルソナはどのくらいの頻度で更新されるべきですか?
ペルソナは、当初特定された主要なタイプのユーザーを表しているかどうかを評価するために、時間をかけて評価される必要があります。ペルソナは時間のスナップショットと見なされるため、ビジネス、市場、ユーザーに関する人口統計の変化を考慮しないと、古くなる可能性があります。これらの要因を検討して、データと現在のペルソナの間に違いがあると判断した場合、ペルソナを更新する前に追加のリサーチが必要になる場合があります。ペルソナの潜在的なリサーチに関するアドバイスが必要な場合は、支援のために UX リサーチに相談してください。
ペルソナを更新する正しい頻度はありませんが、企業はペルソナを更新するために必要な時間とリソース(上記で議論された要因に加えて)を考慮する必要があります。また、ペルソナが最後にリサーチされて以来、プロダクトやユーザーエクスペリエンスがどれだけ変わったかを考慮することも重要です。一般的に、約 5 年以上停滞していたペルソナは、より最新のペルソナほど有効ではない可能性があります。
ペルソナを作成するためにどれくらいの時間を費やすべきですか?
外部リサーチは、大規模(500 人以上の従業員)組織の従業員がユーザーペルソナの作成に費やした時間の量を調査しました。全体的に、非経験的データ(ユーザー人口に関する過去のデータや知識を活用する)を使用する場合と、経験的データ(ユーザー人口について学ぶためにリサーチ活動を利用する)を使用する場合で、ペルソナの作成にかかる時間の量に違いがありました。非経験的データを使用したプロジェクトの場合、ペルソナを作成するために必要な時間は約 55 時間でした。経験的データの取得に焦点を当てたプロジェクトの場合、大企業はペルソナを作成するために約 102.5 時間を必要としました。
c955a93f)