エンタープライズデータウェアハウス
エンタープライズデータウェアハウスの概要
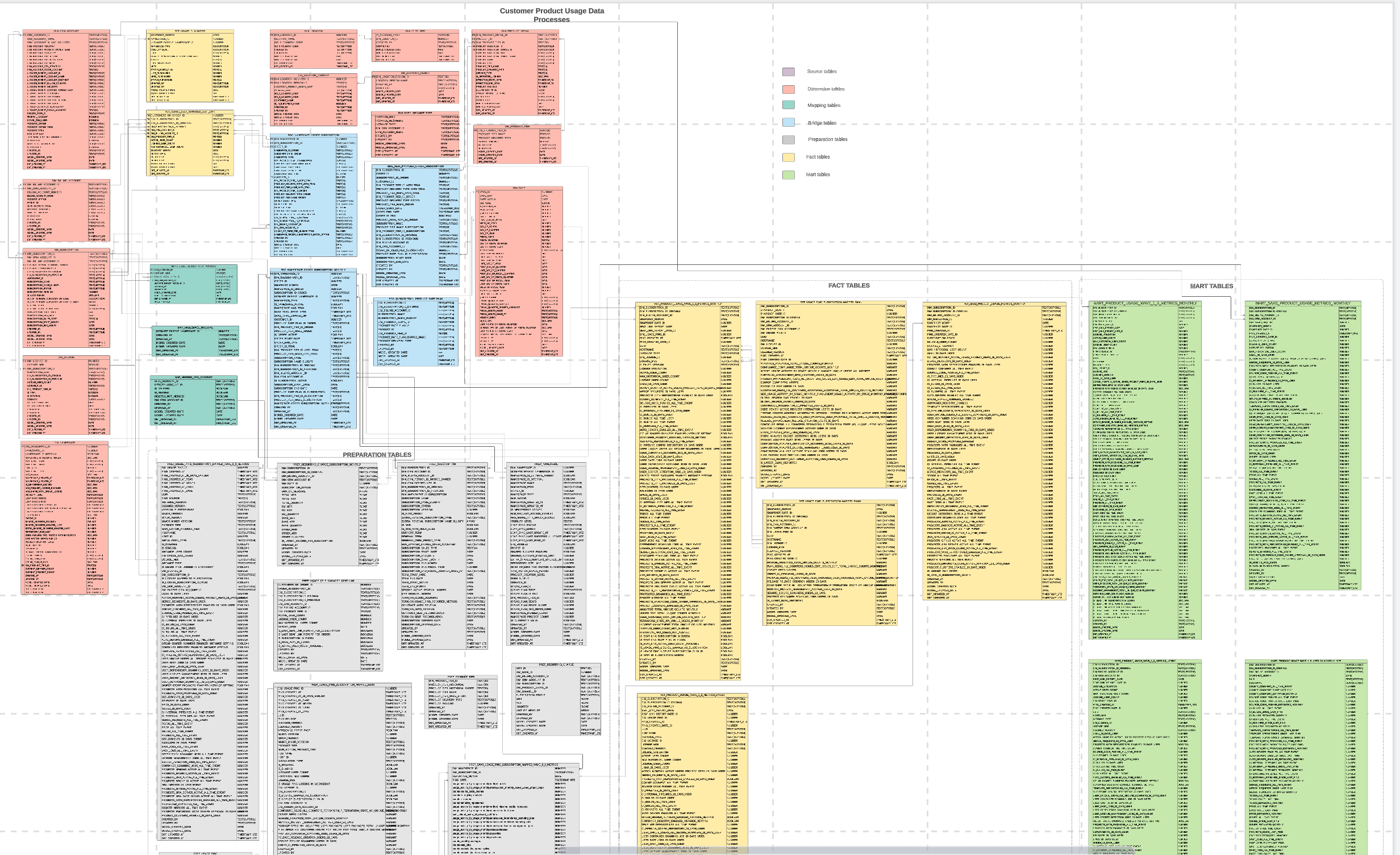
アーキテクチャの概要
EDWは一連のレイヤーとして捉えられています。5つの連続したレイヤーがあり、データはこのレイヤーを通じて処理されます。また、データが探索・開発される1つの開発レイヤーがあります。各レイヤーはEDWの全体的な運用と有効性における役割を持っています。EDW内のすべてのデータはLandingに格納されます。その後のすべてのレイヤーはオプションですが、Tableauはprodデータベーススキーマにのみ接続する必要があることに注意してください。
| レイヤー | 目的 | スキーマ例 |
|---|---|---|
| Landing | ソースシステムからの読み込み 非冪等データの生成 | raw.salesforce_v2_stitch |
| Staging | カラム名とデータ型の標準化 フィルタリングと重複排除(クレンジング) | prep.salesforce |
| Preparation | 処理中のステップと変換 汎用ビジネスロジックの適用 | prod.common_prep |
| Model | 磨かれた製品 エンタープライズ次元モデル 機能データモデル 信頼性が高く、検証済みでサポートされている | prod.common |
| Semantic | 論理的および物理的な構成 レポートと分析のエントリポイント | prod.common_mart |
| Workspace | 開発中 探索 高速イテレーション | prod.workspace_sales |
各レイヤーで実行される活動の詳細については、レイヤーセクションを参照してください。
重要なスキーマ
EDWの本番データベースは、GitLabのデータコンシューマーによるレポートと分析に使用されます。主要な4つのスキーマCOMMON_、SPECIFIC、LEGACY_、WORKSPACE_で構成されています。
- COMMON スキーマ: エンタープライズ次元モデル(EDM)を格納し、統合されたアプリケーションデータの中核として機能します。Kimball手法を実装して最高のデータ品質基準を確保します。
- SPECIFIC スキーマ: 他のシステムとの統合を必要とせず独立したアプリケーションデータを維持します。
- WORKSPACE スキーマ: 実験とプロトタイピングのための柔軟な環境を提供します。
- LEGACY スキーマ: 現代のアーキテクチャへの移行に際して、歴史的なモデリングアプローチを維持します。
次元モデリングの基礎
次元モデリングはRalph Kimballによって開発されたビジネス次元ライフサイクル手法の一部です。
レイヤー
Landing
LandingレイヤーはソースシステムからのデータがEDWにコピーされる場所です。従来のSQLテーブルとファイルベースのデータの両方を含むことができます。
Staging
Stagingレイヤーは最初の管理的な変換が行われる場所です。これらの変換により、予測可能な動作をするデータセットが作成され、GitLab標準の規則に準拠したデータになります。
データ型の適合: NULLおよびブランク値の処理は、データのステージング中に行う必要があります。ブランク値はNULLに変換する必要があります。
カラム名の標準化: カラム名を適合させることで、変換がより自己文書化され、将来の変換の可読性が向上します。
データのクレンジング: 誤ったデータレコード(重複など)の削除は、ダウンストリームの変換を効率化します。
非表形式データのフラット化: Landingレイヤーのデータが非表形式で格納されている場合、他のステージングステップを実行できるようにデータをフラット化することが必要です。
Preparation
Preparationレイヤーは一般的なビジネスロジックの変換がデータに初めて適用される場所です。
フィールドの計算: 計算フィールドは、ソースシステムに由来しないが、単一のデータセット内のデータにビジネスロジックを適用することで形成できるフィールドです。
フィールドの導出: 導出フィールドは、ソースシステムに由来しないが、複数のデータセットにわたるデータへのビジネスロジックの適用によって形成できるフィールドです。
レコードの導出: 日付間隔データのファンアウトなどの導出レコードは、ソースシステムに由来しないが、JoinまたはAggregationを通じて形成されるレコードです。
モデリング
モデリングレイヤーは、データが保守と拡張を容易にする正式な構造に変換される場所です。
ファクトとディメンションの作成: Kimball次元モデリングの原則を使用して、データをフィルタリング、グループ化、結合して再利用可能なディメンションモデルとファクトを作成します。
ビッグテーブルの作成: ビッグテーブルモデルは、できるだけ多くの関連する属性を単一の広いテーブルに提供することを目的としています。
エンタイトルメントテーブルの作成: エンタイトルメントモデルは、SnowflakeとTableauなどのツールでデータレコードへの明示的なアクセスを許可するための人物識別子とJoin条件のリストを作成することを目的としています。
セマンティック
セマンティックレイヤーは、ビジネスレポートのニーズに合わせてデータが変換される場所です。
マートテーブルの作成: マートテーブルは、多くの関連するビジネス質問に答えるために必要なレコードと列を提供します。
レポートテーブルの作成: レポートテーブルは、単一のビジネス質問に答えるために必要なレコードと列を提供します。
ワークスペース
ワークスペースは、データウェアハウス内で探索と初期開発が行われるレイヤーです。
ワークスペースを使用する場合:
- EDWでこれまでモデル化されたことのない完全に新しいデータソースを探索する
- 継続的なレポートには使用されない一時的な分析を作成する
- EDM標準を満たさない可能性のある実験的な変換を実行する
- 本番レポートに影響を与える可能性のある既存のEDMモデルへの主要な変更をテストする
ワークスペースを使用しない場合:
- 最小限の変換で既存の EDM テーブルを結合する
- ビジネスで定期的に使用される新しいレポートまたはダッシュボードを作成する
- EDM ソースに標準的なビジネスロジックを適用する
- 既存の次元モデルを追加のメトリクスまたは属性で拡張する
継続的なレポート作成にとって価値のあるモデルは、ワークスペースから適切な EDM スキーマへ移行する必要があります。定期レビューでは、ビジネスレポートに不可欠になったワークスペースモデルを特定し、強固なデータガバナンスを維持するためにその移行を優先する必要があります。
エンタープライズ次元モデル(COMMON スキーマ)
有用なリンクとリソース
コアコンセプト
次元モデリングは2つの主要なコンポーネントを使用します:
- ファクト(メジャー): データの数値的な値。これらは分析したい「いくつ」「いくら」の値です。
- ディメンション(コンテキスト): ファクトに意味を与える記述的な属性。ディメンションはデータの「誰が、何を、いつ、どこで、なぜ」に答えます。
このアプローチにより、いくつかのスキーマパターンが作成されます:
- スタースキーマ: 中央のファクトテーブルをディメンションテーブルにリンク
- スノーフレークスキーマ: 他のディメンションテーブルにリンクするディメンションテーブル
- ギャラクシースキーマ: 相互に接続された複数のファクトテーブル
開発プロセス
次元モデルは4つの主要なステップで構築されます:
- ビジネスプロセスを選択する(例: 年間収益の追跡)
- 粒度を宣言する(例: 顧客ごと)
- ディメンションを特定する
- ファクトを特定する
スキーマ
Common Prep スキーマ
Common Prepスキーマはデータアーキテクチャの重要な中間レイヤーとして機能します。
コア原則
4つの基本原則が開発と保守を導きます:
- 真実の単一ソース 次元エンティティごとに1つのprepモデルを維持します。
- 最低粒度の保持 次元エンティティの最低可能粒度でprepモデルを維持します。
- 包括的なデータ保持
COMMON_PREPスキーマでのレコードのフィルタリングを避けます。 - 実用的なモデル作成 Commonスキーマへの直接変換がより効率的な場合、prepレイヤーをスキップします。
Common Mapping スキーマ
ディメンションテーブルをサポートするマッピング/ルックアップ(map_)テーブルはcommon_mappingスキーマで作成する必要があります。
Common スキーマ
Common スキーマは、エンタープライズ次元モデルを構成するすべてのファクトとディメンションを格納する場所です。Common スキーマには、複数のスタースキーマを作成するさまざまな種類のディメンションとファクトが含まれます。このスキーマのモデルは堅牢であり、GitLab のビジネスプロセスを分析する基盤を提供します。
私たちの次元モデルは、ディメンション(コンテキストを提供する)とファクト(イベントを測定する)という 2 つのコアコンポーネントを中心に構成されています。効果的なデータモデリングには、各コンポーネントの役割と特性を理解することが不可欠です。
ディメンションテーブル
ディメンションテーブルは、ビジネスイベントにコンテキストを与える記述的な属性を提供します。これはデータにおける「誰が、何を、どこで、いつ、なぜ、どのように」を表します。ディメンションテーブルは通常、顧客、製品、場所などのビジネスエンティティを表します。
ディメンションの特性
- 記述的な属性(テキストベースまたはカテゴリ型)を含む
- 通常、ファクトテーブルよりも行数が少なく、列数が多い
- 時間の経過に対する変化が比較的遅い
- クエリとフィルタリングの入口を提供する
- 階層関係を含む
一般的なディメンションの種類
適合ディメンション 適合ディメンションにより、複数のファクトテーブルとデータマートにわたって、ファクトとメジャーを一貫して分類および記述できます。これらのディメンションは、複数のファクトテーブルにわたって一貫した意味を維持します。この標準化により、信頼できる分析レポーティングが確保され、データウェアハウス全体での再利用性が促進されます。適切に実装すると、各サブジェクトエリアを独立して分析しながら、関連エリアとインサイトを組み合わせる能力を維持できます。ただし、サブジェクトエリア間でディメンションにわずかな違いでもある場合、このエリア横断分析の能力は機能しなくなります。Kimball は、この標準化された共有ディメンションのセットを「conformance bus」と呼んでおり、共通ディメンションのシームレスな統合を促進し、複数のサブジェクトエリアにわたる包括的なレポーティングを可能にします。例:
- さまざまなビジネスプロセスで使用される日付ディメンション
- セールスとマーケティングで使用される顧客ディメンション
ローカルディメンション 単一のビジネスプロセスまたはファクトテーブルに固有のディメンションで、特定のイベントまたはメトリクスにコンテキストを提供します。例:
- サポートチケットのステータス
- 注文タイプ
- キャンペーン属性
ディメンションテーブルのキー
- サロゲートキー:
dbt_utils.surrogate_keyマクロで生成するハッシュ化キーです。主キーとして機能し、ソースアプリケーションデータに由来せず、ディメンションとファクトを結合するために使用します。2022 年 6 月以降、_sk接尾辞(例:dim_order_type_sk)を使用し、dim_を前置する必要があります。最終ディメンションテーブルの最初の列として、--Surrogate Keyコメントセクションに置く必要があります。 - 自然キー: ソースシステムから取得します。単一フィールドまたは複合にできます。ディメンションテーブルの 2 番目の列(複数可)として、
--Natural Keyコメントセクションに置く必要があります。一貫性のため、単一フィールドの自然キーにはdim_プレフィックスを使用します。 - 欠損メンバー値: すべてのディメンションには、欠損メンバーのレコードが必要です。
dbt_utils.surrogate_key(MD5('-1')と同等)を使用して生成します。自動生成には missing member column macro を使用できます。
ゆっくりと変化するディメンションとスナップショット
時間的視点の理解
データ分析では通常、現在と履歴という 2 つの視点が必要です。現在のビューでは最新のディメンション値を使用しますが、履歴分析では特定の時点で物事がどのように見えていたかを理解する必要があります。例:
- 以前の製品カタログを使ったセールスの分析
- 時間の経過に伴う顧客所在地の変更の追跡
- 組織構造の理解
ディメンションのタイプ
時間ベースの変更を処理するために、3 つのアプローチを実装しています:
タイプ1ディメンション
- 変更時に値を上書き
- 現在の状態のみを維持
- 最もシンプルな実装
- 履歴コンテキストを失う
タイプ2ディメンション(SCD)
- 変更に対して新しいレコードを追加
valid_fromとvalid_to日付で有効期間を追跡- 履歴分析を有効化
- 完全な変更履歴を維持
タイプ3ディメンション
- 現在の値と代替の値を維持
- 複数の分析的視点を可能にする
- 二重の分類ニーズをサポートする
- 現在EDMでは実装されていない
実際の SCD
スナップショットテーブルは履歴追跡システムの中核を成し、ビジネスオブジェクトを作成から現在の状態に至るまで、変更のたびに完全なライフサイクルを取り込みます。これらのテーブルは、効率的な履歴分析を可能にしながら、変更の詳細な監査証跡を維持します。
私たちの実装では、ゆっくりと変化するディメンションは dbt のスナップショット機能を使用して作成します。dbt スナップショットは、データの履歴変更を追跡するシンプルかつ強力な方法を提供します。スナップショットを実行すると、dbt はデータの現在の状態を前回のスナップショットと比較し、valid_from と valid_to の日付を通じて変更を自動的に追跡します。
スナップショットは有効期間を通じて変更を追跡し、各状態にこれらのタイムスタンプを付けます。たとえば、単純な状態変更は次のようになります:
| id | attribute | valid_from_date | valid_to_date |
|---|---|---|---|
| 1 | ‘open’ | 2022-01-01 | 2021-01-02 |
| 1 | ‘closed’ | 2022-01-02 | NULL |
この形式は履歴データを効率的に格納しますが、ビジネスユーザーが分析するには難しい場合があります。使いやすさを改善するために、これらのスナップショットを COMMON スキーマ内の日次粒度レコードに変換します。これらの _daily_snapshot モデルは、次元モデルとの一貫性を維持しながら有効期間を個々の日のレコードへ展開し、時間ベースの分析をより直感的にします。
モデル開発では、まず COMMON_PREP のステージングモデルでビジネスロジックを実装し、次に dbt のスナップショット機能を使用して変更を追跡します。この基盤により、パフォーマンスへの影響を管理しながら、必要に応じて日次スナップショットを作成できます。
スナップショット実装のベストプラクティスには、明確な現在レコードインジケーターの追加、関連モデル間での一貫した粒度の維持、有効期間の徹底的な文書化が含まれます。これらのプラクティスにより、多様な分析ニーズに対応しながら履歴追跡の正確性とパフォーマンスを維持できます。
ファクトテーブル
ファクトテーブルは、分析したいビジネスイベントを記録します。ビジネスプロセスの定量的なメトリクス(メジャー)と、関連するディメンションへの参照を含みます。
主要な特性
ファクトテーブルは数値メジャーを含むビジネスイベントを取り込み、新しいイベントの発生に伴って通常は継続的に増加します。多くの行(それぞれが単一のイベントを表す)を持ちますが、列数は比較的少ないことが特徴です。
これらのテーブルのメジャーの大部分は集計できますが、平均のように部分的にしか集計できないものや、パーセンテージのようにまったく集計すべきでないものもあります。各ファクトテーブルは特定のビジネスプロセスを表し、ディメンションテーブルにリンクする外部キーを含むことで、メジャーにコンテキストを提供します。
ファクトの種類
アトミックファクト ファクトテーブルは、ビジネスイベントを最も細かい粒度で取り込むことで、ファクトベース分析の基盤を形成します。各行は、完全でフィルタリングされていないデータを持つ個々のビジネスイベントを表し、最大レベルの詳細を保持します。この粒度を維持することで、アトミックファクトはさまざまな分析ニーズに柔軟な集計オプションを提供します。
派生ファクト 派生ファクトは、明確なデータリネージを維持しながら特定の分析ニーズに対応するため、アトミックファクトの上に構築される特殊なビューです。大きなアトミックファクトテーブルの対象を絞ったサブセットを作成することで、パフォーマンスを改善します。たとえば、アナリストが通常、大きなイベントテーブルのわずか 10% だけを扱う場合、派生ファクトでその部分だけを抽出してクエリ速度を改善できます。これらのテーブルは、よく使われる集計を事前に計算することでメトリクスも標準化します。
さらに、「drill across facts」を通じて、共有する適合ディメンションを介して複数のファクトテーブルを結合し、統合された分析ビューを作成できます。共通ディメンションで完全外部結合を使用することで、このプロセスは次元的一貫性を維持しながら関連するビジネスプロセスをリンクする派生ファクトテーブルを作成し、複数のビジネスエリアにわたる分析を可能にします。
ファクトテーブルのキー
- 主キー: ファクトテーブルの最初の列でなければなりません。
<table_name_without_fct_prefix>_pkとして命名します(例:fct_eventのevent_pk)。--Primary Keyコメントセクションに置く必要があります。作成にはdbt_utils.surrogate_keyマクロまたは連結関数を使用できます。 - 外部キー:
--Foreign Keysコメントセクションに置く必要があります。これらはディメンションからのハッシュ化されたサロゲートキーです。さらにConformed DimensionsとLocal Dimensionsのサブセクションに分類できます。すべての外部キーでは、欠損メンバーを処理するためにget_keyed_nullsマクロを使用する必要があります。
特殊用途テーブル
ブリッジテーブル
ブリッジ(bdg_)テーブルは common スキーマに置かれ、次元モデルで重要な役割を果たします。これらの中間テーブルは、テーブル間の多対多関係を解決し、適切な関係管理を確保しながらデータモデルの柔軟性を維持します。
Common Mart スキーマ
Common Mart スキーマはディメンションとファクトをビジネスにすぐ使える分析モデルへ結合し、ビジネスユーザーと分析ツールの主なアクセスポイントとして機能します。
目的と構造
マートレイヤーは、関連するファクトとディメンションを結合することで、次元モデルをビジネス固有のデータセットへ変換します。共通の属性を事前に結合し、標準的なビジネスルールを適用することで、マートは各ビジネスドメイン内の特定の分析ニーズに合わせてデータを最適化します。
ビジネスドメイン別の編成
マートモデルはビジネス機能別に編成され、データを Finance、Marketing、People、Product、Sales などの焦点を絞った領域に分離します。この機能別の編成により、各部門は適合ディメンションを通じてより広範なデータウェアハウスとの接続を維持しながら、分析ニーズに合わせて特別に調整されたデータを利用できます。
主な特性
マートモデルは Enterprise Data Model のファクトテーブルおよびディメンションテーブルに直接基づいて構築され、一貫したビジネス定義と標準化された関係を確保します。データリネージを維持し複雑さを防ぐため、他のマートモデルをソースとして参照することはありません。
分析を念頭に設計されたこれらのモデルは、一般的なクエリパターンに対して事前結合済みのテーブルを備え、頻繁に使用される計算を含みます。データの粒度は、ユーザーニーズとパフォーマンス要件のバランスをとるよう慎重に検討されます。
この設計では、テーブルとフィールドに技術的な用語ではなく馴染みのあるビジネス用語を使用し、ビジネスユーザーを最優先にします。このビジネス指向の構造とドキュメントは、一般的な分析パターンに合わせることでセルフサービス分析を支援し、データへのアクセスと理解を容易にします。
ベストプラクティス
- モデルの対象を特定のビジネスドメインに絞る
- 前提条件と制限事項を文書化する
- 関連するマート間で命名の一貫性を維持する
- ビジネスロジックを定期的にテストする
- 最適化のため使用パターンを監視する
- ソースモデルへの明確なリネージを維持する
特殊用途テーブル
スキャフォールドテーブル
スキャフォールドテーブルはファクトテーブル間の基盤構造として機能し、可視化や分析におけるすべての可能なディメンションの組み合わせを包括的にカバーします。Tableau のような可視化ツールで作業する場合、これらのテーブルは欠損を補い、実績と目標の一貫した比較を可能にするため、特に価値があります。データポイントが欠けている場合でも連続したビューを維持する必要がある時間ベースの分析で、特に役立ちます。この完全なディメンションフレームワークを提供することで、スキャフォールドテーブルは、データが存在しない期間や組み合わせを含む全体像をアナリストが確認できるようにし、レポートやダッシュボードで誤解を招く空白が生じるのを防ぎます。これらのスキャフォールドテーブルは、common_mart スキーマ内に rpt_scaffold_ プレフィックスで配置され、完全なディメンションの組み合わせを維持しながらファクトテーブルを基に構築されます。
目標と実績のレポートでは、データの完全性と一貫性を確保するためにスキャフォールドテーブルを使用します。このテーブルは、販売活動の有無にかかわらず、すべての期間と属性の組み合わせをカバーする包括的な構造を維持します。
Specific スキーマ
SPECIFICスキーマは、エンタープライズ次元モデルの次元モデリング構造に準拠しないがレポート機能を実行し、真実のソースとして機能するテーブルに使用されます。
変換なしビュー
変換なしビューは、さらなる変換なしにレポートに必要な生ソースデータの直接ビューである必要があります。常にビューとしてntv_プレフィックスで作成する必要があります。
エンタイトルメント
SnowflakeとTableauの両方での行レベルセキュリティの使用を促進するために、エンタイトルメントテーブル専用のスキーマが使用されます。
命名
エンタイトルメントテーブルの名前は、他のテーブルへの参照と使用するアプリケーションを示す必要があります。例: ent_team_member_directory_tableau
技術的な実装詳細
Tableau統合のベストプラクティス
Tableauは主要な可視化ツールであるため、すべてのEDWモデルはTableauの互換性を念頭に置いて設計する必要があります。
命名標準
- PREP テーブル:
prep_<subject> - FACT テーブル:
fct_<verb> - DIMENSION テーブル:
dim_<noun> - MART テーブル:
mart_<subject> - REPORT テーブル:
rpt_<subject> - PUMP テーブル:
pump_<subject> - MAP テーブル:
map_<subjects> - BRIDGE テーブル:
bdg_<subjects> - SCAFFOLD テーブル:
rpt_scaffold_<subject> - 単数命名を使用する(例: dim_customer、dim_customersではない)
- テーブルと列名にプレフィックスを使用して同様のデータをグループ化する
テストフレームワーク
モデルは信頼できるデータフレームワーク(TDF)に従ってschema.ymlファイルによるテストとドキュメントが必要です。
時間標準
すべてのシステムで月曜日を週の最初の日として標準化します:
CASE WHEN day_name = 'Mon' THEN date_day
ELSE DATE_TRUNC('week', date_day)
END AS first_day_of_week
エンティティ関係図(ERD)ライブラリ
これらの図は主要なビジネスプロセスフライホイール全体でエンタープライズ次元モデル内のデータオブジェクト間の関係を示します。
Lead to Cash ERDs
ERDライブラリ
Product Release to Adoption ERDs
Team Member ERDs
Lucidchartを使用したエンティティ関係(ER)図の作成
Lucidchartはユーザーが図表を視覚的にコラボレーションして描画・修正・共有できるWebベースの作図アプリケーションです。
ステップ1: 'Lucidchartアプリ'からブランクのlucidドキュメントを作成します。
ステップ2: ページの左下にある「シェイプライブラリ」の下に表示される「データのインポート」をクリックします。
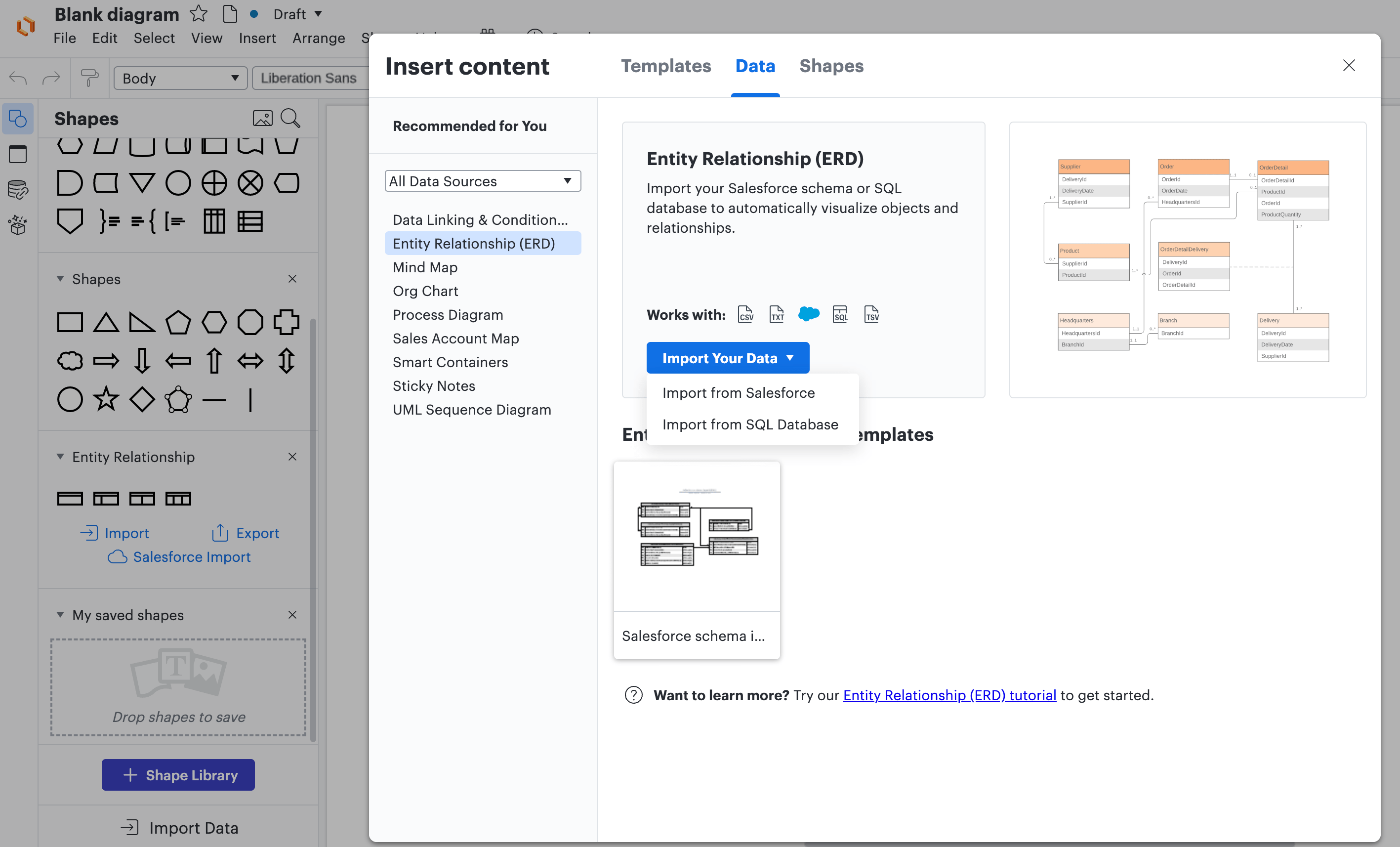
ステップ3: 「すべてのデータソース」から「エンティティ関係(ERD)」を選択します。
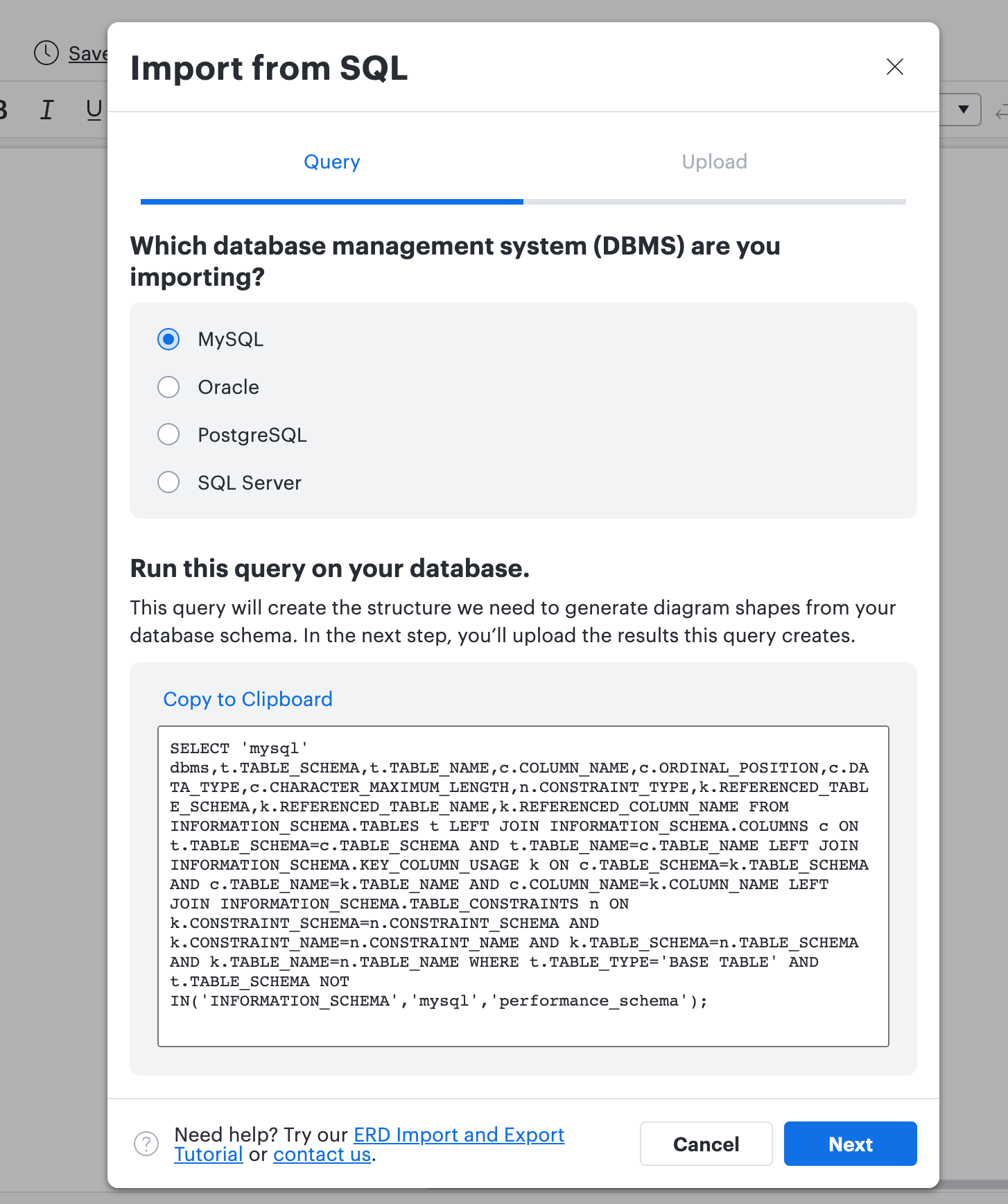
ステップ4: データをインポートするDBMSソースとして「MySQL」を選択します。
ステップ5: Snowflakeで以下のスクリプトを実行します。
The below query can be run in Prod database in Snowflake to get all the Models/tables from COMMON and COMMON_PREP Schemas:
SELECT 'mysql' dbms,
t.TABLE_SCHEMA,
t.TABLE_NAME,
c.COLUMN_NAME,
c.ORDINAL_POSITION,
c.DATA_TYPE,
c.CHARACTER_MAXIMUM_LENGTH,
'' CONSTRAINT_TYPE,
'' REFERENCED_TABLE_SCHEMA,
'' REFERENCED_TABLE_NAME,
'' REFERENCED_COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLES t
LEFT JOIN INFORMATION_SCHEMA.COLUMNS c
ON t.TABLE_SCHEMA=c.TABLE_SCHEMA
AND t.TABLE_NAME=c.TABLE_NAME
WHERE t.TABLE_SCHEMA NOT IN('INFORMATION_SCHEMA')
AND t.TABLE_SCHEMA IN ('COMMON', 'COMMON_PREP')
ステップ6: Snowflakeからクエリの結果をcsvファイルにダウンロード・エクスポートします。
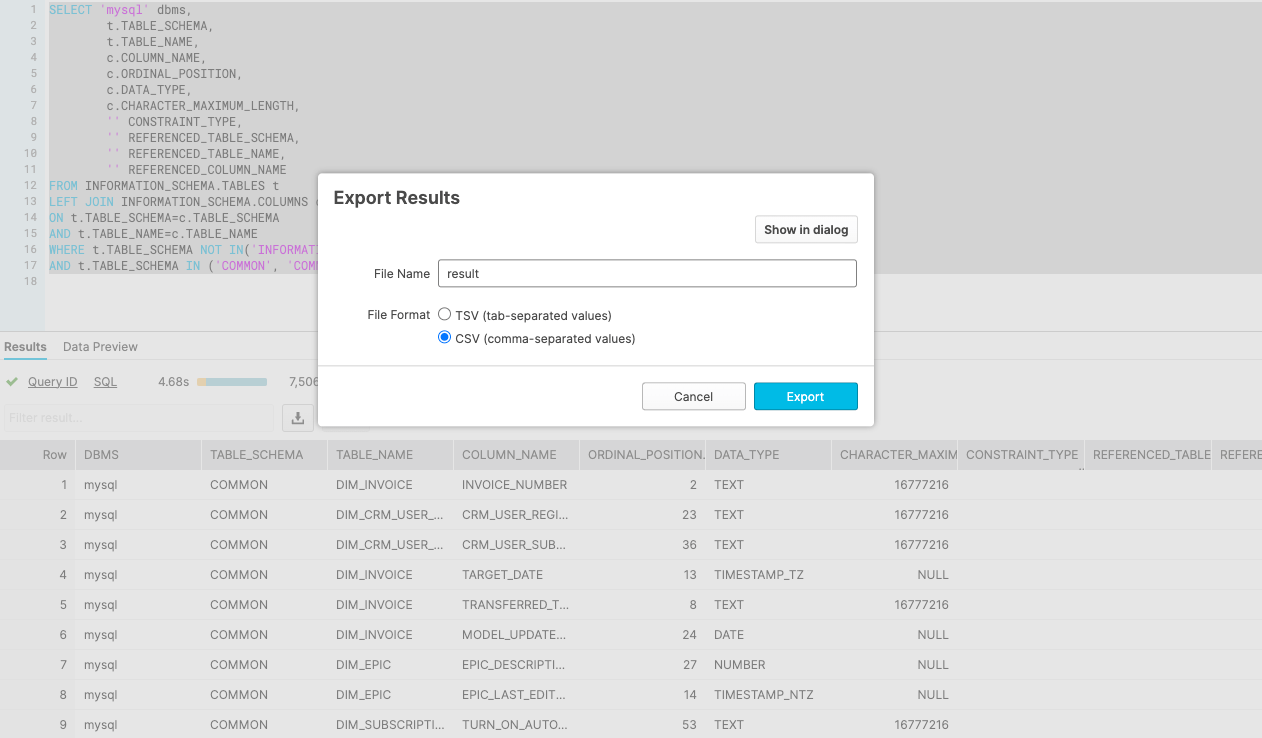
ステップ7: Lucidchartアプリに戻り、result.csvファイルを選択してアップロードし、「インポート」をクリックします。
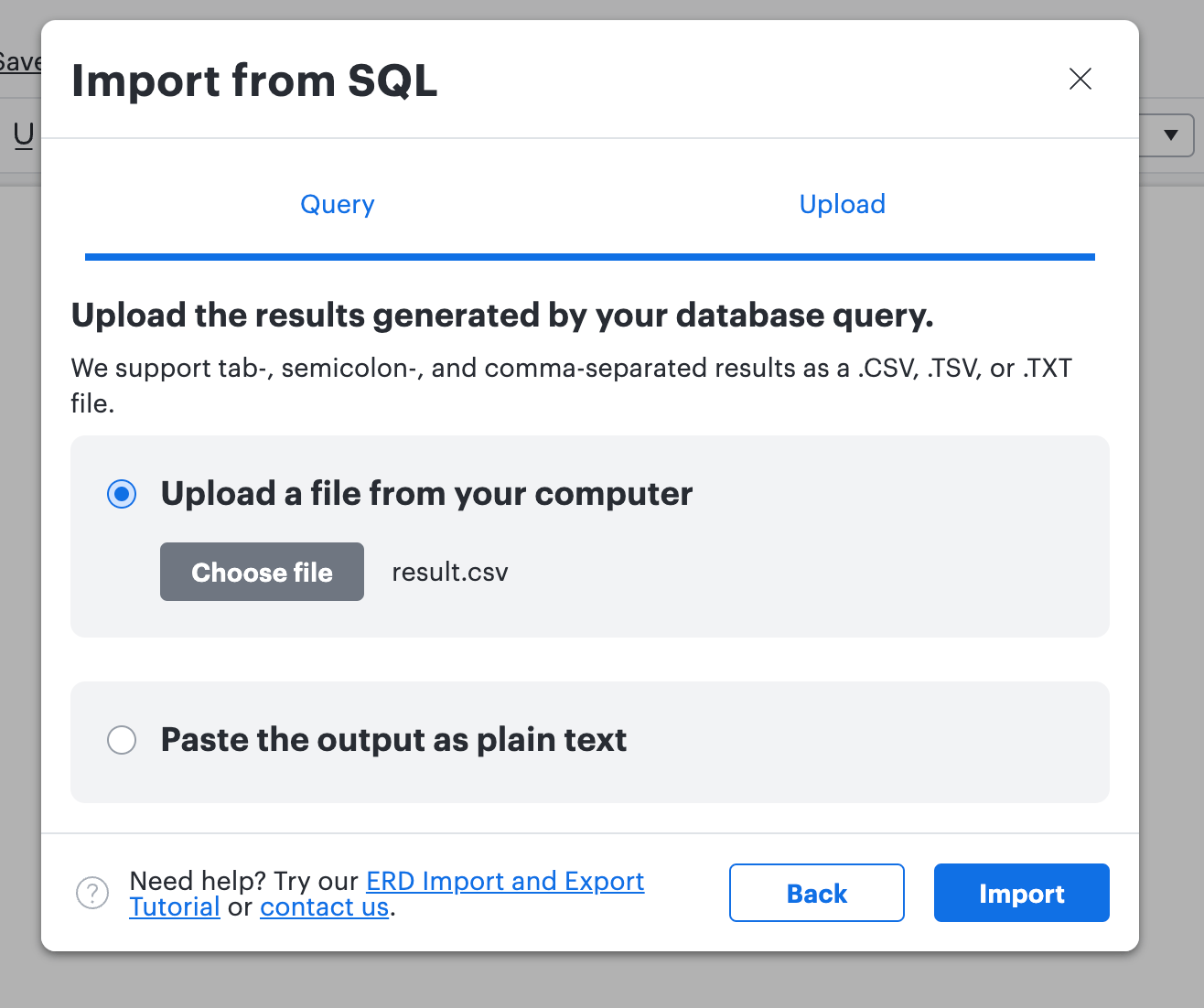
ステップ8: 選択した「table_schema」リストのすべてのテーブル/モデルが「ERD インポート」の下に表示されます。
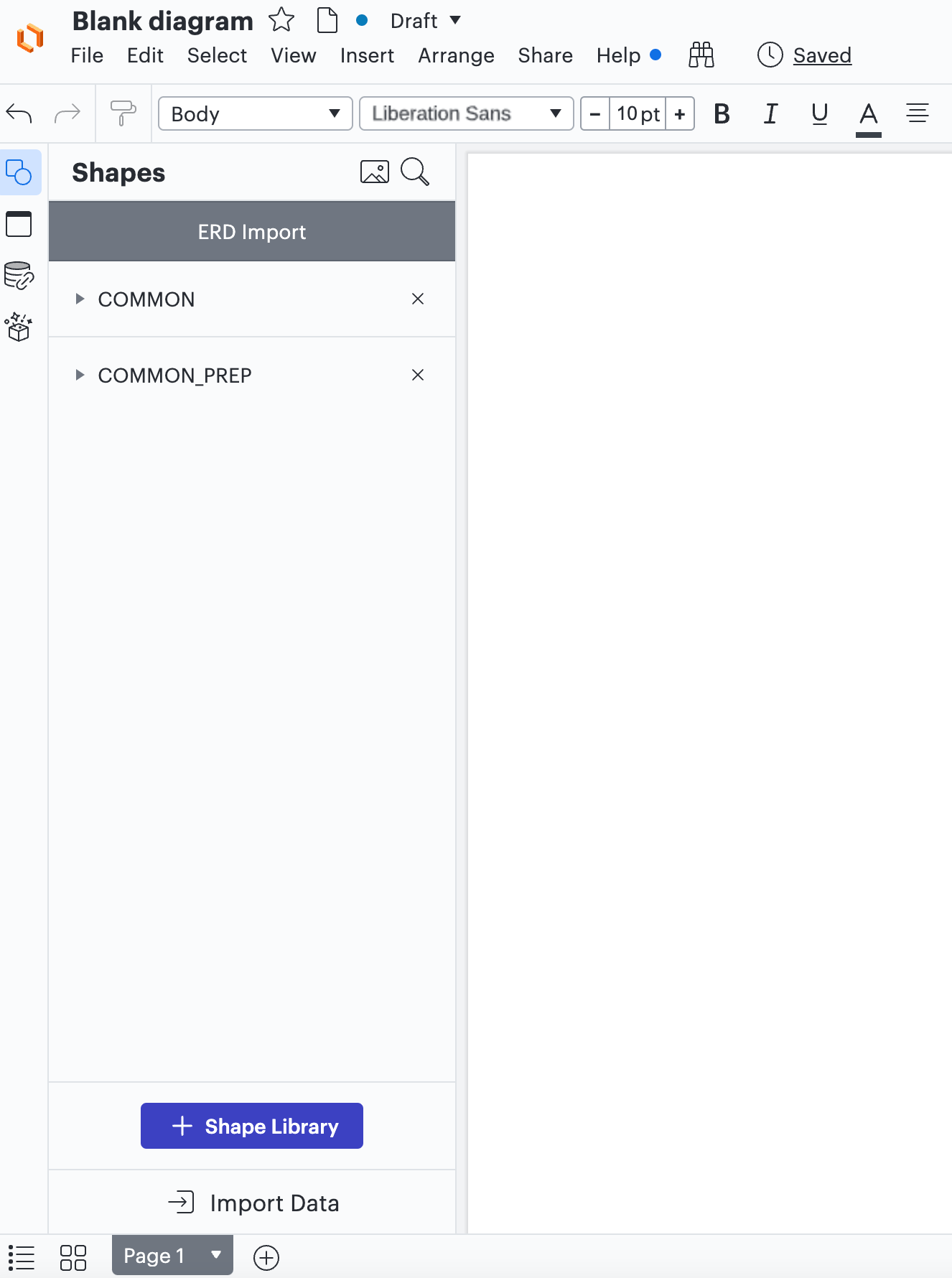
ステップ9: 必要なテーブル/エンティティをキャンバスにドラッグし、リボンからエンティティ間の関係を定義してER図を作成します。
ビッグデータ
ビッグデータは、データサービスの限界を理解するために使用するコンセプトです。一般的に、ビッグデータとは現在のデータサービスの処理・提供能力を超えるまたは負荷をかけるものです。
ビッグデータとエンタープライズデータウェアハウス
EDWのビッグデータは3つの一般的なトピックで分類されます:
- ボリューム - 関連するソース、コンセプト、またはモデルに対してどれだけのデータがあるか
- ベロシティ - データがどれだけ速く変化し、取り込まれ、消費されるか
- バラエティ - データソースの構造とフォーマットが他のソースとどれだけ異なるか
アナリティクスパフォーマンスポリシーフレームワーク
問題の説明
EDWのデータボリュームとビジネスロジックの複雑さの増加により、EDWで構築されたデータモデルの変換は時間の経過とともにパフォーマンスが低下しており、日次のdbtモデル本番実行が12時間以上かかっています。
dbtモデルの実行を3つの主要な次元で考えます:
- パフォーマンス モデルのビルドにかかる時間に関連
- 効率性 モデルがローカルストレージ、リモートストレージ、パーティションプルーニングをどれだけうまく使用するかに関連
- コスト モデルの実行に必要なSnowflakeクレジット数に関連
パフォーマンスターゲット
- 本番dbt DAGの実行時間を8時間未満に維持します。
- 個々のdbtモデルの実行時間は一貫して1時間未満であり、予測されるデータボリュームの増加を考慮した設計になっています。
- SnowplowのビッグデータセットのSnowflakeでのシンプルなクエリはLまたはXLウェアハウスで1分未満で完了します。
パフォーマンス向上のためのアーキテクチャアプローチ
- データモデルで変換・表示するデータ量を削減します。
- データモデルへのクラスタリングキーの追加を検討します。
- データモデルでの
simple_cteマクロの使用を評価します。 - データモデルをインクリメンタルに設定することを検討します。
履歴アーカイブプロセス
- パフォーマンスポリシーの考慮によりデータモデルで再作成またはサーフェスできない非冪等データの場合は、データプラットフォームのアーカイブ方法論を活用して履歴アーカイブを作成します。
c955a93f)