データチーム CI ジョブ
GitLab データチーム CI ジョブ
これらの野心は、GitLabのデータプラットフォームのためのガイドビジョンとなるよう設定されています。
GitLabのデータプラットフォームへの貢献は簡単であり、プラットフォームの使用は直感的です
データプラットフォームとそれが提供するデータは、可用性と精度の点で一貫しています
データプラットフォームは人々を危険にさらしません
GitLabのデータプラットフォームは、GitLab以上のコミュニティに関連性があり、より大きなエンジニアコミュニティに依存しています。
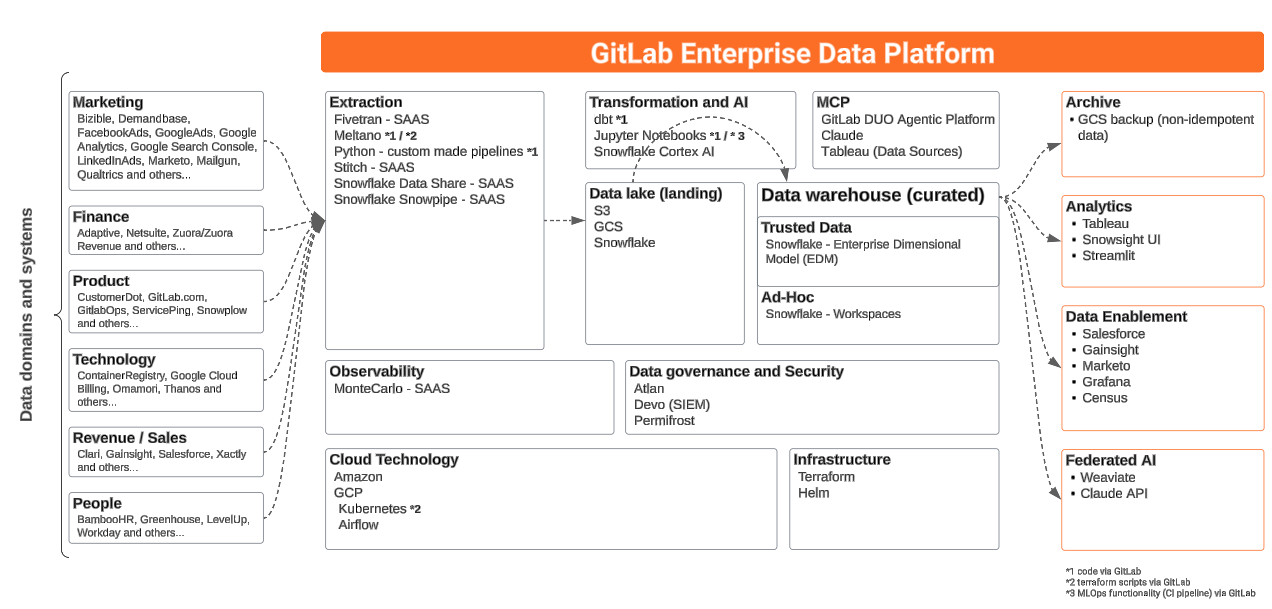
データプラットフォームはデータ分析の目的に使用されます。このドキュメントは、データプラットフォームとして総称的に定義されるコンポーネントを概念的に高レベルで説明します。
このドキュメントは、データプラットフォームを概念的に説明することに限定されます。それをより詳細に説明する他のリソースがあります(例: データパイプライン と インフラストラクチャ)。
| 役割 | 責任 |
|---|---|
| GitLab Team Members | データプラットフォームを形成する標準にどう注意を払うかについての責任 |
| Data Platform Team Members | この標準に基づいてデータユースケースを実装および実行する責任 |
| Data Management Team | この標準に対する重要な変更と例外を承認する責任 |
私たちは、分析機能を運用および管理するためにGitLabを使用しています。 すべてはIssueから始まります。 変更は、パイプライン、抽出、ロード、変換、および分析の一部への変更を含めて、マージリクエストを通じて実装されます。
| ステージ | ツール |
|---|---|
| Extraction | Stitch, Fivetran, Tableau Prep, Custom Code |
| Loading | Stitch, Fivetran, Tableau Prep, Custom Code |
| Orchestration | Airflow, Tableau Prep |
| Data Warehouse | Snowflake Enterprise Edition |
| Transformations | dbtとPythonスクリプト |
| Data Visualization | Tableau |
| Advanced Analytics | jupyter |
私たちは現在、一部のデータソースで Stitch と Fivetran を使用しています。これらは、一部のデータソースから当社のSnowflakeデータウェアハウスへのデータの移動の構築、メンテナンス、オーケストレーションの責任を取り除く、オフザシェルフのELTツールです。
StitchとFivetranは、データパイプラインの開始を自分自身で処理します。これは、AirflowがStitchおよびFivetranスケジュールのオーケストレーションで役割を果たさないことを意味します。
データを抽出するために使用する他のソリューションは以下です:
ソースの所有権については、Tech Stack Applicationsデータファイル を参照してください。
以下の表は、外部の場所からデータウェアハウスにロードしているすべてのRAWデータソースをインデックス化しています。私たちは New Data Source/Pipeline Project Management シートで開発バックログと優先順位を管理し、最新のステータスと進捗管理のためのGitLab Issueへのリンクがあります。new data sourceハンドブック ページでは、データチームが新しいデータソースのリクエストを処理する方法を説明しています。
以下の表のパイプラインの列のリンクは、該当する場合、特定のデータパイプラインの詳細ページに移動します。
キー
RAW データベースのスキーマ。PREP データベースのスキーマ。PROD レイヤーで利用可能になるまでの時間を意味します(これには、dbt内の変換が含まれます)。
x は未定義または実行されないことを示します| Name | Pipeline | Raw Schema | Prep Schema | Audience | RF / SLO | MNPI | Tier |
|---|---|---|---|---|---|---|---|
| Adaptive | Airflow | adaptive_custom | x | Finance | Yes | Tier 2 | |
| Adobe / Bizible | Airflow | bizible | sensitive | Marketing | 24h / 36h | No | Tier 2 |
| Airflow | Fivetran | airflow_fivetran | airflow | Data Team | 24h / 24h | No | Tier 3 |
| AWS Billing | Snowflake external tables | aws_billing | aws_billing | Engineering | 24h / 24h | No | Tier 2 |
| Clari | Airflow | clari | clari | Sales | 24h / 24h | Yes | Tier 2 |
| Clearbit | x | x | x | x / x | No | Tier 3 | |
| ClickHouse billing | Airflow | clickhouse_billing | clickhouse_billing | Engineering | 24h / 24h | No | Tier 2 |
| Common Room | Snowflake task | commonroom | commonroom | DevRels/Developer Advocates | No | Tier 3 | |
| Cornerstone | Fivetran | cornerstone | cornerstone | People | 6h / 12h | No | Tier 2 |
| Coupa Production | Fivetran | coupa | coupa | Marketing | 24h / 48h | No | Tier 2 |
| Coupa Sandbox | Fivetran | coupa_sandbox | coupa_sandbox | Marketing | Ad-hoc | No | Tier 3 |
| Cloudflare Billing | Airflow | cloudflare_billing | cloudflare_billing | Engineering | 24h / 24h | No | Tier 2 |
| CustomersDot | pgp | tap_postgres | customers | Product | 24h / x | No | Tier 1 |
| CustomerWins | Airflow | customerwins | customer_wins_losses | Sales and marketing | 7 Days/7 Days | No | Tier 3 |
| Demandbase | Snowflake task | demandbase | demandbase | Marketing | 24h / x | No | Tier 2 |
| Demo Architecture Portal | fivetran | fivetran_demo_architecture_portal_lab_information | demo_architecture_portal | Sales and marketing | 7 Days/7 Days | No | Tier 3 |
| Elastic Search Billing | Airflow | elasticsearch_billing | elastic_billing | Engineering | 24h / 24h | No | Tier 2 |
| End to End test metrics | Snowflake tasks | e2e_metrics | e2e_metrics | Engineering | 24h / 48h | No | Tier 2 |
| Ecosystems BVA | Airflow | ecosystems | ecosystems | Sales | 24h / 48h | No | Tier 3 |
| Facebook_ads | Fivetran | facebook_ads | facebook_ads | Marketing | 24h / 48h | No | Tier 3 |
| Fivetran_Logs | Fivetran | N/A | N/A | Data | 24h / 48h | No | Tier 3 |
| Flaky test Metrics | Snowflake tasks | flaky_tests | flaky_tests | Engineering | 24h / 48h | No | Tier 2 |
| Gainsight Customer Success | Fivetran | gainsight_customer_success | gainsight_customer_success | Customer Success | 24h / 48h | No | Tier 3 |
| GitLab Availability | Snowflake tasks | gitlab_availability | gitlab_availability | Product, Engineering | 24h / 48h | No | Tier 2 |
| GitLab.com | pgp | tap_postgres | gitlab_dotcom | Product, Engineering | 12h / 55h | No | Tier 1 |
| GitLab Profiler DB | x | x | x | x | x / x | No | Tier 3 |
| GitLab Container Registry Logs | Airflow | Container Registry | Container Registry | Engineering | x | No | Tier 2 |
| Google Ads | Fivetran | google_ads | google_ads | Marketing | 24h / 48h | No | Tier 2 |
| Google Analytics 360 | Fivetran | google_analytics_360_fivetran | google_analytics_360 | Marketing | 6h / 32h | No | Tier 2 |
| Google Analytics 4 | BigQuery Exporter | google_analytics_4_bigquery | google_analytics_4 | Marketing | 24h / 48h | No | Tier 2 |
| Google Cloud Billing | BigQuery Exporter | gcp_billing | gcp_billing | Engineering | 24h / x | No | Tier 1 |
| Google Search Console | Fivetran | google_search_console | google_search_console | Marketing | 24h / 48h | No | Tier 2 |
| Graphite API | Airflow | engineering_extracts | x | Engineering | 24h / 48h | No | Tier 3 |
| Greenhouse | Sheetload | greenhouse | greenhouse | People | 24h / 48h | No | Tier 2 |
| Hackerone | Airflow | hackerone | x | Security/Engineering | 24h / 48h | No | Tier 2 |
| Handbook YAML Files | Airflow | gitlab_data_yaml | gitlab_data_yaml | Multiple | 8h / 24h | No | Tier 2 |
| Handbook MR Data | Airflow | handbook | handbook | Multiple | 24h / 24h | No | Tier 2 |
| Handbook Git Log Data | Airflow | handbook | handbook | Multiple | 1w / 1m | No | Tier 2 |
| Iterable | Fivetran | iterable | n/a | Multiple | 24h / 48h | No | Tier 3 |
| Just Global Campaigns | Snowflake task | just_global_campaigns | just_global_campaigns | Marketing | 7d / 14d | No | Tier 3 |
| Kantata | Airflow | kantata | kantata | Customer Success | 24h / 48h | Yes | Tier 3 |
| Level Up/Thought Industries | Airflow | level_up | level_up | People | 24h / 24h | No | Tier 3 |
| LinkedIn ads | Fivetran | linkedin_ads | n/a | Marketing | 24h / 48h | No | Tier 3 |
| MailGun | Airflow | mailgun | sensitive | Sales, Marketing, Customer Success, Digital Success | 24h / 24h | No | Tier 3 |
| Marketo | Fivetran | marketo | x | Marketing | 24h / 24h | No | Tier 2 |
| ModernLoop | Airflow | modernLoop | modernLoop | People | 24h / 48h | No | Tier 3 |
| Monte Carlo | Snowflake Share | n/a | prep_legacy | Data | 12h / 24h | No | Tier 3 |
| Netsuite | Fivetran | netsuite2_fivetran | netsuite | Finance | 6h / 24h | Yes | Tier 2 |
| Omamori | Airflow | omamori | omamori | Engineering | 1h / 24h | No | Tier 2 |
| Pajamas Adoption Scanner | Airflow | pajamas_adoption_scanner | pajamas_adoption_scanner | Engineering | 24h / 48h | No | Tier 3 |
| PMG | x | pmg | pmg | x | x / x | No | Tier 3 |
| Qualtrics | Airflow | qualitrics | qualtrics | Marketing | 12h / 48h | No | Tier 2 |
| Rally | Fivetran Webhook | rally_webhook_fivetran | sensitive | UX | 24h / 48h | No | Tier 3 |
| SaaS Service Ping | Airflow | saas_usage_ping | saas_usage_ping | Product | 1 week / 24h | No | Tier 1 |
| Salesforce | Fivetran | salesforce_fivetran | sfdc | Sales | 6h / 24h | Yes | Tier 1 |
| Salesforce (for Gong Data) | Fivetran | RAW.gong_salesforce | prep.gong_salesforce | Sales | 6h / 24h | Yes | Tier 1 |
| Salesforce Sandbox | Fivetran | salesforce_sandbox_gtlbuat | TBC | Sales | 24h / 48h | Yes | Tier 3 |
| Salesforce Sandbox Test 2 | fivetran | salesforce_fivetran_sandbox_test2 | TBC | Sales | 24h / 48h | Yes | Tier 3 |
| SheetLoad | SheetLoad | sheetload | sheetload | Multiple | 24h / 48h | Yes | Tier 1 |
| SIRT Alertapp | Snowflake task | sirt_alertapp | sirt_alertapp | Engineering | 24h / 48h | No | Tier 3 |
| Snowplow | Snowpipe | snowplow | snowplow | Product | 15m / 24h | No | Tier 1 |
| Tableau Cloud | Tableau Prep | tableau_cloud | tableau_cloud | Data Team | 24h / 24h | No | Tier 3 |
| Tableau Back-end Data | Fivetran | tableau_fivetran | N/A | Data Team | 24h / 48h | No | Tier 3 |
| Thanos | Snowflake Task | prometheus | prometheus | Engineering | 24 h / x | No | Tier 3 |
| Version DB | Automatic Process | version_db | version_db | Product | 24 h / 48 h | No | Tier 1 |
| Workday | Fivetran | workday | workday | People | 6h / 24h | No | Tier 2 |
| Xactly | Meltano | tap_xactly | N/A | Sales | 24h / N/A | Yes | Tier 2 |
| Zendesk | Meltano | tap_zendesk | zendesk | Support | 24h / 48h | No | Tier 2 |
| Zuora | Fivetran | zuora_billing_fivetran | zuora | Finance | 6h / 24h | Yes | Tier 1 |
| Zuora Central Sandbox | Fivetran | zuora_central_sandbox_fivetran | zuora_central_sandbox | Finance Sandbox | - | Yes | Tier 3 |
| Zuora Central Sandbox 2 | Fivetran | zuora_central_sandbox_2 | zuora_central_sandbox_2 | Finance Sandbox | - | Yes | Tier 3 |
| Zuora Developer Sandbox | Fivetran | zuora_dev_sandbox_fivetran | TBD | Finance Sandbox | - | Yes | Tier 3 |
| Zuora Data Query | Airflow | zuora_query_api | zuora_query_api | Finance | 24h / 48h | Yes | Tier 1 |
| Zuora Revenue | Airflow | zuora_revenue | zuora_revenue | Finance | 24h / 48h | Yes | Tier 1 |
| Integrate DAP | Fivetran | integrate_dap | integrate_dap | Marketing | 6h / 12h | No | Tier 3 |
外部エラーがある場合に誰に連絡するかについては、source contact spreadsheet を参照してください。
| アスペクト | Tier 1 | Tier 2 | Tier 3 |
|---|---|---|---|
| 説明 | - 最も重要でビジネスクリティカルな信頼されたデータソリューション。 - 日々の運用を確保するために、コンポーネントが利用可能でリフレッシュされる必要があります | - 洞察を集めるために重要で有益なデータソリューション。 - コンポーネントは、日々の運用をサポートするために利用可能でリフレッシュされている必要があります | - Ad-Hoc、定期的、または一度きりの分析に重要なデータソリューション。 - コンポーネントは利用できない、またはデータがリフレッシュされない可能性があります。 |
| 基準 | - 24時間利用できない場合に$100k以上のビジネスインパクトをもたらす任意のデータ、プロセス、または関連サービス - 15人以上のビジネスユーザーに影響を与える | - 24時間利用できない場合に$100k未満のビジネスインパクトをもたらす任意のデータ、プロセス、または関連サービス - 5〜15人のビジネスユーザーに影響を与える | - 5営業日以上利用できない場合に即時のビジネスインパクトをもたらさない任意のデータ、プロセス、または関連サービス - 5人未満のビジネスユーザーに影響を与える |
| 停止による影響 | 重大 | 寛容 | 無視できる |
| モニタリングとオブザーバビリティ | 鮮度と量の異常についてMonte Carloを通じて監視。すべてのアラートが調査され、必要に応じて、上流(システム/データ)所有者にエスカレートされます。 | データパイプラインの継続性のために、Monte Carloを通じて技術的に鮮度が監視されます。アラート時に、技術的な失敗が調査されます。 | データパイプラインの継続性のために、Monte Carloを通じて技術的に鮮度が監視されます。アラート時に、技術的な失敗が調査されます。 |
モニタリングと根本原因調査に関するメモ: トリアージャーは、データコンテキスト(タイプ、ボリューム、履歴パターン)を評価して、上流(システム/データ)所有者との調査および/またはエスカレーションが必要かどうかを判断するべきです。チームメンバーは、データのコンテキストを考慮するべきです。以下は規範的ではありませんが、緩やかに従われるパラダイム(例、他も適用されます)として機能します: データソースが1日あたり1Mレコードを受信していたのに、パイプラインが実行されているのに突然データを受信しなくなった場合、これは必ずしもデータパイプラインに関連していない上流の問題を示しているため、調査が必要です。ただし、データソースが1日あたり10レコードを受信していたのに、特定の日付(例: 1月1日)で2レコードに低下した場合、これは履歴パターンに基づく期待される行動である可能性があるため、調査は必要ない可能性があります。
新しいデータソースをデータウェアハウスに統合するため、データチームの特定メンバーは、UIとAPIの両方でデータソースへの管理者レベルのアクセスが必要です。 適切な分析を構築するために必要なすべてのデータを取得するためにAPIを通じて、また準備された分析の結果をUIと比較するためにUIを通じて、この管理者レベルのアクセスが必要です。
機密データソースは、必要なレポートを構築するために、少なくとも1人のデータエンジニアと1人のデータアナリストがアクセスを持つように制限できます。 場合によっては、2人のデータエンジニアのみになる可能性があります。 自動化された抽出プロセスのために追加のアカウントをリクエストする可能性があります。
機密データは、以下にリストされたセキュリティパラダイムを通じてロックダウンされます。
Service ping データインジェスチョンに関する場合、特定の詳細は Service ping ページまたはService pingの Readme.md ページで見つけることができますセットアップに関する詳細については、Snowplow Infrastructureページ を参照してください。
私たちはデータプロダクトの開発にAIを使用し、データプロダクトでAIを使用します。
私たちは、GitLab Duo Agentic Platform(詳細は internal handbookページ で)、Tableauデータソース、ClaudeをModel Context Protocol(MCP)接続経由でSnowflakeデータウェアハウスに接続することで、データ開発プロセスを強化するためにAIを活用しています。この統合により、開発ワークフローを加速し、データプロダクトの品質を向上させることができます。
私たちのAIプロダクト開発は、2つの主要な領域に分類されます:
私たちは、データプラットフォーム内で Snowflake Cortex AI を活用して、データウェアハウス内で直接ネイティブAI機能を提供しています。詳細な実装ガイダンスとベストプラクティスについては、AI to Dataに関する内部ハンドブックページ を参照してください。
以下を含むフェデレーションAIツールを実装しています:
私たちは、オーケストレーションのためにKubernetes上のAirflowを使用しています。具体的なセットアップ/実装は こちら で見つけることができます。詳細については、Data Infrastructure ページも参照してください。
私たちは現在、データウェアハウスとして Snowflake を使用しています。Enterprise Data Warehouse(EDW)は、GitLabの企業データ、パフォーマンス分析、Key Performance Indicatorsなどのエンタープライズ全体のデータに関する信頼できる唯一の情報源です。EDWは、レポート作成、ダッシュボード作成、分析のための共通のプラットフォームとフレームワークをすべてのチームに提供することで、GitLabのデータ駆動のイニシアチブをサポートします。ポイントツーポイントのアプリケーション統合を除き、現在および将来のすべてのデータプロジェクトはEDWから推進されます。さまざまなGitLabソースシステムからのデータの受信者として、EDWはまた、すべての決定が可能な限り最高のデータを使用して行われることを確実にするために、データ品質のベストプラクティス、メジャー、修正を情報提供および推進するのに役立ちます。
Issue: Snowflake documentation
Snowplowにジオデータを抽出しないために、以下の列がnullifyされました:
geo_zipcodegeo_latitudegeo_longitudeuser_ipaddressこのnullifyは、2023-02-01 からSnowplowに適用され、ファイルは同じ構造を持ち、列値だけが NULL に設定されています。データチームは古いファイルを更新して、言及された列を NULL に設定し、Snowflakeでも列を NULL に設定しました。これはSnowflakeの RAW、PREP、PROD レイヤーに適用されます。
Snowflake documentation のとおりに S3 バケットで更新されたファイルの重複ロードを避けるため、フォルダ構造は以下から変更されました:
- gitlab-com-snowplow-events/
output/ <---- all files are located here
2019/01/01
...
(present day)
新しい構造に:
- gitlab-com-snowplow-events/
output_nullified_columns/ <---- all files are nullified and updated
2019/01/01
...
2023/01/31
output/ <---- new files will land here and will be loaded by Snowpipe
2023/02/01
...
(present day)
page_url_path 列のnullifyIssue: s3: Pseudonymize page_url_path in Snowflake and s3 bucket
Snowplowに対するデータコンプライアンスのために、以下の列が仮名化されました:
page_url_pathこの仮名化は、Snowplow データに対して、期間 2022-10-26 - 2024-12-01 で適用され、ファイルは同じ構造を持ち、列値だけが仮名化されています。
データチームは古いファイルを更新し、page_url_path 列を仮名化し、Snowflakeでも page_url_path 列を仮名化しました。
これはSnowflakeの RAW、PREP、PROD レイヤーに適用されます。
s3: Pseudonymize page_url_path in Snowflake and s3 bucket のとおりに S3 バケットで更新されたファイルの重複ロードを避けるため、フォルダ構造は以下から変更されました:
- gitlab-com-snowplow-events/
output_nullified_columns/ <---- all files are nullified and updated (in the previous iteration)
2022/10/26
...
2023/
02/
output/
2023/
02/
03/
新しい構造に:
- gitlab-com-snowplow-events/
output_nullified_columns/
2019/01/01
...
2022/10/25
output_mask_page_url_path/ <---- all files are pseudonimized
2022/10/26
...
2023/12/01
output/ <---- new files will land here and will be loaded by Snowpipe
2023/12/02
...
(present day)
注:
S3バケットへのすべての新しいロードは、以前と同じフォルダgitlab-com-snowplow-events/outputに入ります。
前提条件:
アクセスオプション:
サポートポータルアクセスには3つの権限レベルがあります:
MANAGE ORGANIZATION SUPPORT CASES - 組織全体のすべてのサポートケースを表示および管理MANAGE ACCOUNT SUPPORT CASES - アカウントのすべてのサポートケースを表示および管理MANAGE USER SUPPORT CASES - ユーザー自身がオープンしたケースを表示および管理アクセスポリシー:
個別リクエストには常にMANAGE USER SUPPORT CASESから始めてください。より高いアクセスレベル(MANAGE ACCOUNTまたはMANAGE ORGANIZATION SUPPORT CASES)は、個別レベルのアクセスが不十分である理由を示すビジネス上の正当化が必要です。
アクセスの付与:
ACCOUNTADMIN のみが、MANAGE ACCOUNT SUPPORT CASESまたはMANAGE USER SUPPORT CASES権限を付与できます。
ORGADMIN のみが、MANAGE ORGANIZATION SUPPORT CASES権限を付与できます。
適切な付与ステートメントを実行します:
– MANAGE USER SUPPORT CASES
USE ROLE ACCOUNTADMIN;
GRANT MANAGE USER SUPPORT CASES ON ACCOUNT TO ROLE <role_name>;
– MANAGE ACCOUNT SUPPORT CASES
USE ROLE ACCOUNTADMIN;
GRANT MANAGE ACCOUNT SUPPORT CASES ON ACCOUNT TO ROLE <role_name>;
– MANAGE ORGANIZATION SUPPORT CASES
USE ORGADMIN;
GRANT MANAGE ORGANIZATION SUPPORT CASES ON ACCOUNT TO ROLE <role_name>;
<role_name> :- これは個別のロールです。Oktaを介してSnowflakeにいるユーザーはユーザーロールを持っていないことに注意してください。
初回アクセス: 初回サポートにアクセスする場合、ユーザーはSnowsightで「Enable Support」を選択する必要があります。
snowflakeサポートポータルへのアクセスを取得するには、以下の手順に従ってください。
+ Support Case ボタンを押します
Snowflake へのアクセスを取得するには、Lumos Access Request を使用してください。3 つのオプションがあります:
マネージャーが承認すると、リクエストは Data Team にルーティングされます。Analyst と Analyst SAFE については、Okta SCIM が Snowflake アカウントをプロビジョニングし、適切なラッパーロールを割り当てます。Customer User については、Data Team が Snowflake-permissions リポジトリ を通じて手動でアクセスをプロビジョニングします。
SAFE アクセスについては、必要な承認について SAFE Guide を参照してください。
注: Snowflake アカウントが Lumos/Okta SCIM 統合の前に作成された場合、または Analyst と Analyst SAFE を超えるアクセスが必要な場合は、以下の 追加のアクセス パスを使用してください。アクセスアーキテクチャの完全な説明については、Snowflake Guide を参照してください。
すべてのユーザーは dev_xs ウェアハウスへの標準アクセスを持ちます。ウェアハウスはユーザーロールレベルでプロビジョニングされており、よりきめ細かいウェアハウス割り当てを可能にします。このアプローチでは、GitLab Team Membersに適切なウェアハウスサイズを割り当てることで、リソース割り当てとコスト管理を最適化できます。より大きなサイズのウェアハウスは、通常のアクセスリクエストプロセスを介してリクエストできます。
Snowflakeは、SQLコードを書くことで利用可能なデータの分析を実行するために使用できます。作成されたもの、分析の結果は、ad-hoc analyses と見なされます。作成されたもの(ワークシートとダッシュボード)はバージョン管理されておらず、中央データチームによってサポートまたは管理されていないことを知ることが重要です。つまり、チームメンバーがGitLabから離れたとき、ワークシートとダッシュボードはアクセスできなくなります。分析を永続化するために、チームメンバーはTableauワークブックを構築する、GitLabプロジェクトにコードスニペットを保存する、またはデータチームの dbt project にコードをコミットできます。
ユーザーがSCIMのLumos & oktaを介して実装される前にSnowflakeで作成された場合、またはdbtプロジェクトに貢献するために必要なdevデータベースの作成を含む、デフォルトの snowflake_analyst および snowflake_analyst_safe を超えるアクセスが必要な場合、必要なアクセスレベルを文書化した Access Request を使用してください。
ユーザーが標準の snowflake_analyst または snowflake_analyst_safe ロールを超えるロール(例: analyst_core ロール)を必要とする場合、これはpermifrostを通過する必要があり、roles.yml を更新する必要があります。permifrostの使用方法の詳細については、Snowflake Permissions Paradigm を参照してください。
ステップ1: 現在のアクセス状態の確認:
roles.yml でユーザー名を検索することで、ユーザーがpermifrostを介してすでにプロビジョニングされているかどうかを確認します。
ユーザー名が roles.yml にない場合、Snowflakeでロールおよびおそらくユーザーを作成する必要がある可能性があります。
この状態は、以下のクエリを使用してSnowflakeで検証できます。これは、Snowflakeにユーザーとユーザーロールが存在する場合、それらの行を返します。
SET username = 'username';
SELECT
'user' AS record,
name, created_on,deleted_on,
disabled, owner
FROM SNOWFLAKE.ACCOUNT_USAGE.users
WHERE LOWER(name) IN ($username)
UNION
SELECT
'role' AS record,
name, created_on, deleted_on,
null AS disabled, owner
FROM SNOWFLAKE.ACCOUNT_USAGE.ROLES
WHERE LOWER(name) IN ($username);
ステップ2: ユーザーの現在の状態に基づいて適切に処理:
roles.yml にすでに存在する:roles.yml を、Snowflake Permissions Paradigm に従って、必要な追加のロールおよび/または権限で更新するroles.yml のために user role を作成する必要がある:roles.yml を、Snowflake Permissions Paradigm に従って、必要な追加のロールおよび/または権限で更新する👥 users_snowflake_provisioning_snowflake を介してroles.yml を、Snowflake Permissions Paradigm に従って、必要な追加のロールおよび/または権限で更新するrestricted_safe ロールを通じて提供されている)ことに注意してください。analyst_marketing ロールを持っている場合、analyst_marketing のみが報告され、analyst_marketing 内のすべての継承されたロールは報告されません。roles.yml file を確認してください。何らかの理由で、ユーザーをOktaとLumosの外でプロビジョニングする必要がある場合、私たちは歴史的に以下のプロセスを使用してきました:
Provisioning ラベルが適用された元のアクセスリクエストにリンクするIssueがGitLab Data Teamプロジェクトにあることを確認しますsecurityadmin ロールに切り替えますsecurityadmin の所有権の下にあるべきですuser_provision.sql スクリプトをコピーし、初期ブロックでemail、firstname、lastname値を置き換えますokta-snowflake-users Googleグループ に割り当てられていることを確認します最後に、Oktaによって管理されていない、またはデフォルトを超える権限が付与されている既存のユーザーをデプロビジョニングするための適切なステップは以下です:
Deprovisioning ラベルが適用された元のソースリクエストにリンクするIssueがGitLab Data Teamプロジェクトにあることを確認します。securityadmin ロールに切り替えますsecurityadmin の所有権の下にあるべきです。user_deprovision.sql スクリプトをコピーし、USER_NAMEを置き換えます。snowflakeでユーザーを削除して残さず、disabled = TRUEに設定する理由は、ユーザーがアクセスを失った時の記録を持つためです。okta-snowflake-users Googleグループ から削除します詳細については、この 録画されたペアリングセッション を見てください(GitLab Unfilteredとして表示する必要があります)。
システムアカウントは、トークンキーを除き、私たちの Snowflake Terraformプロジェクト のコードを通じて完全に作成および管理されており、トークンキーは別途保存および設定されます。
サービスユーザー(人間の対話なしでSnowflakeとやり取りするサービスまたはアプリケーション)は、トークンキーを除き、私たちの Snowflake Terraformプロジェクト のコードを通じて完全に作成および管理されており、トークンキーは別途保存および設定されます。
私たちは、Snowflakeの権限を管理するのを助けるために Permifrost を使用しています。 私たちのSnowflakeインスタンスの設定ファイルは このroles.ymlファイル に保存されています。 Permifrostに関するハンドブックページ も利用可能です。
私たちはロール管理に関して以下の一般戦略に従います:
analyst_finance、data_manager、product_manager)を表すために存在しますaccountadmin、securityadmin、useradmin、sysadmin)はユーザーに直接割り当てられます各ユーザーは、ユーザー名と一致する独自のユーザーロールを持ちます。
Snowflakeでのオブジェクトレベルの権限(データベース、スキーマ、テーブル)は、ロールにのみ付与できます。
ロールはユーザーまたは他のロールに付与できます。
私たちは、ユーザーがデータベースとやり取りするのに1つのロールだけを使う必要があるように、すべての権限がユーザーロールを流れるよう努めています。
例外は accountadmin、securityadmin、useradmin、sysadmin などの特権ロールです。
これらのロールはより高いアクセスを付与し、使用時に意図的に選択されるべきです。
機能的ロールは、通常職務ファミリーにマップする権限セットとロール付与のグループを表します。
主な例外はanalystロールです。
組織のさまざまな領域にマップするanalystロールのいくつかのバリアントがあります。
これらには、analyst_core、analyst_finance、analyst_people などが含まれます。
analystは関連するロールに割り当てられ、必要なスキーマへのアクセスが明示的に付与されます。
機能的ロールはいつでも作成できます。 非常に類似した職務ファミリーと権限を持つ複数の人がいる場合、最も理にかなっています。
この機能的ロールのリストは、ロールが何を伴うかについての高レベルの理解を提供します。欠落している、またはロールが何を伴うかを完全に詳細に知るには、このYAML ファイル を確認してください。
| 機能的ロール | 説明 | SAFEデータ Y/N |
|---|---|---|
data_team_analyst | すべての PROD データ、機密マーケティングデータ、Data Platformメタデータ、一部のソースへのアクセス。 | Yes |
analyst_core | データプラットフォームのすべての PROD データとメタデータへのアクセス | No |
analyst_engineering | すべての PROD データ、データプラットフォームのメタデータ、エンジニアリング関連のデータソースへのアクセス。 | Yes |
analyst_growth | すべての PROD データ、データプラットフォームのメタデータ、さまざまなデータソースへのアクセス。 | Yes |
analyst_finance | すべての PROD データ、データプラットフォームのメタデータ、財務関連のデータソースへのアクセス。 | Yes |
analyst_marketing | すべての PROD データ、データプラットフォームのメタデータ、マーケティング関連のデータソースへのアクセス。 | Yes |
analyst_people | すべての PROD データ、データプラットフォームのメタデータ、機密人員データを含むさまざまな関連データソースへのアクセス。 | Yes |
analyst_sales | すべての PROD データ、データプラットフォームのメタデータ、さまざまな関連データソースへのアクセス | Yes |
analyst_support | PROD データ、データプラットフォームのメタデータ、機密Zendeskデータを含む raw / prep Zendeskデータへのアクセス | No |
analytics_engineer_core | analyst_core、data_team_analyst ロールといくつかの追加の組み合わせ | Yes |
data_manager | Snowflakeデータへの拡張アクセス | Yes |
engineer | Snowflakeでデータ操作タスクを実行するためのSnowflakeデータへの拡張アクセス | Yes |
snowflake_analyst | Snowflake、EDMスキーマ、ワークスペースの PROD データへのアクセス | No |
snowflake_analyst_safe | SAFEデータを含むSnowflake、EDMスキーマ、ワークスペースの PROD データへのアクセス | Yes |
sensitive_pii_data_viewer | 人物および連絡先データマスタリーモデル内のすべての機密フィールドへのアクセス。 | No |
オブジェクトロールは、データセットへのアクセスを管理するためのものです。
通常、これらは特定のソースに対するすべてのデータを表します。
zuora オブジェクトロールは例です。
このロールは、Stitchから来るraw Zuoraデータと、prep.zuora スキーマのソースモデルへのアクセスを付与します。
ユーザーがZuoraデータへのアクセスを必要とするとき、そのユーザーのユーザーロールに zuora ロールを付与することが最も簡単な解決策です。
何らかの理由でオブジェクトロールへのアクセスが理にかなわない場合、個別の権限をテーブルの粒度で付与できます。
マスキングロールは、ユーザーがマスクされたデータとどのようにやり取りするかを管理します。マスキングは列レベルで適用され、どの列がマスクされるかはソースシステムオーナーの決定です。マスキングは、dbtを介してデータオブジェクトが作成されたときに、dbtコードベース内の schema.yml ファイルで列に適用されます。一部のユーザーがマスクされていないデータへのアクセスを必要とするため、マスキングロールにより、機能的またはオブジェクトロールレベルで、マスクされていないデータへの権限を付与できます。たとえば、people_data_masking のマスキングロールが locality 列に適用されている場合、機能的ロール analyst_people を people_data_masking ロールのメンバーとして設定して、analystがマスクされていない人員データを見ることができるようにできます。
マスキングポリシーが作成されると、マスキングロールに基づいて作成され、列に1つのマスキングポリシーだけが適用できます。
これは、Data Analyst, Coreのロール階層の例です:
graph LR
A([User: datwood]) -->|Member of| B[User Role: datwood]
B -->|Member of| C[Functional Role: analyst_core]
C -->|Member of| D[Object Role: workday]
C -->|Member of| H[Object Role: dbt_analytics]
C -->|Member of| E[Object Role: netsuite]
C -->|Member of| F[Object Role: zuora]
G{{Privileges: analytics_sensitive}} -->|Granted to| Cこれは、Data EngineerとAccount Administratorのロール階層の例です:
graph LR
A([User: tmurphy]) -->|Member of| B[User Role: tmurphy]
B -->|Member of| C[Functional Role: engineer]
C -->|Member of| F[Functional Role: loader]
C -->|Member of| H[Functional Role: transformer]
G{{ Privileges: Read/Write Raw}} -->|Granted to| C
A -->|Member of| D[Privileged Role: sysadmin]
A -->|Member of| E[Privileged Role: securityadmin]これは、Security Operations Engineerのロール階層の例です:
graph LR
A([User: ssichak]) -->|Member of| B[User Role: ssichak]
A -->|Member of| C[Privileged Role: securityadmin]FY25-Q1で、上記の Snowflakeのロール管理 プロセスを半自動化することに向かって移動しています、OKR epic。
この変更の主な推進力は、エンジニアリングチームによるアクセスの増加が予想されており、複数のメンバーを同時にプロビジョニングできるプロセスが必要であったことです。さらに、これにより すべてのGitLab Team Members が、Data Platformチームからの最小限のサポートで、Snowflakeユーザーを自分で作成できるようになります。これにより、プロビジョニングプロセスが加速され、GitLab Team MemberがSnowflakeへのアクセスを得るまでの時間が短縮されます。
Snowflakeへのアクセスが必要な場合、すべてのGitLab Team Membersは、この runbook に従ってMRをオープンすることをお勧めします。
プロセスの高レベルの説明:
セクションの残りの部分は、自動化されたプロセスをより詳細に説明することを意図しています。
自動化された主なプロセスは以下です:
roles.yml を更新して、Snowflakeロール/ユーザー権限を更新するこれらの両方のプロセスは、ユーザーがセルフサーブできるようにCIジョブを介してアクセス可能になり、データエンジニアからのMRレビュー/承認のみが必要になります。
両方の CI ジョブは共通のパターンに従います。snowflake-permissions プロジェクトの snowflake_users.yml でユーザーを追加/削除します。
Permifrost を実行する前に、まず Snowflake でユーザーとロールを作成する必要があります。
👥 users_snowflake_provisioning_snowflake CI ジョブは、snowflake_users.yml の変更に基づいて Snowflake にユーザーとロールを作成します。
ジョブ入力と使用方法については、CI jobs ページ を参照してください。
ユーザー/ロールが Snowflake で作成されたら、希望する権限を反映するように roles.yml を更新する必要があります。
📚 roles_yaml_snowflake_provisioning CI ジョブは、snowflake_users.yml の変更に基づいて roles.yml を自動的に更新し、変更を MR にコミットして戻します。
ジョブ入力と使用方法については、CI jobs ページ を参照してください。
📚 roles_yaml_snowflake_provisioning CI ジョブは、1Password に保存され CI 環境変数として設定された Project Access Token を使用して、roles.yml への変更を MR にコミットして戻します。
PATは snowflake_provisioning_automation という名前で、[email protected]アカウントを使用して、‘GitLab Data Team’ project で作成されました。
snowflake_users.yml にユーザーを追加する際は、GitLab Single File Editor での予期しない動作を避けるため、#### do not insert users below this line #### とマークされた行より下にユーザーを挿入しないでください。
Data Platform チームメンバー向け: 両方のスクリプトは、より迅速なテストのためにローカルで実行できます。ローカル開発手順については、snowflake-permissions リポジトリ を参照してください。
非アクティブなSnowflakeユーザーは、snowflake_cleanup DAGを介して週次でデプロビジョニングされます。これは このissue で実装されました。
すべてのアクティブなSnowflakeユーザー/ロールは roles.yml 内で宣言されます。したがって、roles.yml にないSnowflakeユーザーは非アクティブと見なされ、プロセスがそれらをドロップします。
これらのユーザーは、以下の deprovision_user.sql スクリプトを実行することでドロップされます。
このプロセスは、その機密性のためにCIジョブを介して公開されておらず、時間的にもそれほど敏感ではありません。したがって、代わりにAirflowを介した週次の’cleanup’タスクが実行されます。
permifrost_bot_user は、Snowflakeのプロビジョニングおよびデプロビジョニングプロセスの両方を実行するために使用されます。これは2つの理由のためです:
permifrost_bot_user は、既存のPermifrostジョブを実行するのに必要な権限と同じであるため、プロビジョニング/デプロビジョニングを実行するための適切な権限をすでに持っています。permifrost_bot_user は、AirflowとGitLab CIの両方を使用して既存のPermifrostジョブを実行しているため、プロビジョニング(CIで実行)/デプロビジョニング(Airflowで実行)の両方に追加された場合、適用されるNSP IPアドレスが冗長になりません。snowflake内のユーザーロールへの外部テーブルへのUSAGE権限のプロビジョニングは、現時点ではpermifrostによって処理されません。ユーザーロールに対する外部テーブルへのアクセスをプロビジョニングする必要がある場合、securityadmin ロールを使用して、snowflake docs のGRANTコマンドを介して手動で付与する必要があります。これは、ユーザーロールが外部テーブルが配置されているスキーマとdbへのアクセスをすでに持っていることを意味しており、そうでない場合は roles.yml に追加してください。
AR経由でSnowflakeへの権限を申請し、アクセスがプロビジョニングされる場合、変更が有効になるまで3:00AM UTCまでかかります。これは、毎日Snowflakeでアクセスをプロビジョニングするスクリプトが実行されているからです。ログインできるとき、これをOkta経由で行うことができます。Okta経由でログインした後、アカウントに添付された正しいロールを選択する必要があります。これは、デフォルトでアカウントと同じで、@gitlab.com を除くメールアドレスの慣例に従います。
Snowflakeで正しいロールを選択しない場合、以下のSnowflakeオブジェクトしか見ることができません:
正しいロールの選択はGUI経由で実行できます。 Snowsightのホーム画面にいる場合、左上隅で。
Snowsightのワークシートにいる場合、右上隅で。

public をクリック以下を実行することで、これをデフォルトに設定できます:
ALTER USER <YOUR_USER_NAME> SET DEFAULT_ROLE = '<YOUR_ROLE>'
Snowflakeのコンピュートリソースは「ウェアハウス」として知られています。
クレジットの消費を効果的に使用するため、私たちはウェアハウスの量を最小化しようとしています。開発目的(dbtジョブをローカルで実行する、MRパイプラインを実行する、Snowflakeでクエリする)には、dev_x ウェアハウスを使用します。ウェアハウスの名前にはそのサイズが追加されます(dev_xs はextra small)。
| ウェアハウス | 目的 | 最大クエリ(分) |
|---|---|---|
admin | これはpermission botとその他の管理タスク用です | 10 |
data_classification | これはSnowflakeでデータ分類とラベリングプロセスを実行するためのものです | 60 |
dev_xs/m/l/xl | これは開発目的に使用されます。Snowflake UIとCIパイプラインで使用されるべきです | 180 |
gainsight_xs | これはgainsight data pump用です | 30 |
gitlab_postgres | これは内部のGitLab Postgresデータベースから引き出すための抽出ジョブ用です | 10 |
grafana | これは排他的にGrafanaが使用するためのものです | 60 |
loading | これはExtract and Loadジョブ用です | 120 |
reporting | これはBIツールでのクエリ用です | 30* |
transforming_xs | これらはプロダクションのdbtジョブ用です | 180 |
transforming_s | これらはプロダクションのdbtジョブ用です | 180 |
transforming_l | これらはプロダクションのdbtジョブ用です | 240 |
transforming_xl | これらはプロダクションのdbtジョブ用です | 180 |
transforming_2xl | Snowplowモデルのリフレッシュ用 | 120 |
transforming_4xl | これはAirflow dag: dbt_full_refresh 用です | 180 |
usage_ping | これはservice_pingとservice_ping_backfill loadに使用されます。 | 120 |
クエリの時間制限に達している場合は、最適化のためにクエリを確認してください。開発でのパフォーマンスの悪いクエリは、プロダクションでもパフォーマンスの悪いクエリになり、毎日影響を与えます。常に 正しい(サイズの)ウェアハウスを使用してください。ウェアハウスの使用/選択の基本ルール:
ウェアハウスはTシャツのサイズとして設定されます。より大きなウェアハウスはGitLabにとってより高コストです
動いているウェアハウスの使用を検討してください
Snowflakeのクエリタイムアウトは、REPORTING ウェアハウスに対して30分に設定されています。
私たちは、raw、prep、prod の3つの主要なデータベースを使用しています。
raw データベースは、データが最初にSnowflakeにロードされる場所です。他のデータベースは、分析の準備ができている(またはそこに到達している)データ用です。
prep と prod のすべてのテーブルとビューは、dbtを介して制御(作成、更新)されます。毎四半期 データプラットフォームチームは、dbtモデルに関連しないテーブルとビューのチェックを実行し、それらは削除されます。以下のスキーマのリストは例外であり、チェックされません:
SNOWPLOW_%DOTCOM_USAGE_EVENTS_%INFORMATION_SCHEMABONEYARDTDFCONTAINER_REGISTRYFULL_TABLE_CLONESQUALTRICS_MAILING_LISTNETSUITE2_FIVETRANGitLabインスタンス全体に関する情報を含む snowflake データベースがあります。
これにはすべてのテーブル、ビュー、クエリ、ユーザーなどが含まれます。
Snowflake Data Exchangeを通じて管理される共有データベースである covid19 データベースがあります。
Permifrostのテストに使用される testing_db データベースがあります。
biツーリングのテストに使用される bi_tool_eval データベースがあります。ユーザーは独自のテストセットを手動で作成できます。
私たちの roles.yml Permifrostファイルで定義されていないすべてのデータベースは、週次で削除されます。
| データベース | Tableauで使用するのに適しているか |
|---|---|
| raw | いいえ |
| prep | いいえ |
| prod | はい |
データが変換され、ビジネス使用のためにモデル化されているため、prod データベースだけがTableauで使用されるべきです。Tableauで raw と prep データベースを使用すると、不正確なデータおよび/または現在または将来の壊れたクエリ/ダッシュボードが発生する可能性があります。データ変換は prod データベースの結果に対してのみチェックおよびテストされることを覚えておくことが重要です。これは、ダッシュボードがrawまたは prep データベースに直接接続されている場合、現在または将来において壊れたり、間違ったデータを報告したりする可能性があることを意味します。
このデータのdbtモデルは存在しないため、データが役立つまたは正確になるためにはレビューまたは変換が必要な場合があります。このレビュー、ドキュメンテーション、変換はすべて、dbtの下流で PREP と PROD のために発生します。このデータベースはTableauで使用すべきではありません。
Snowflakeデータ共有により、データベース、テーブル、セキュアビューなどのさまざまなSnowflakeオブジェクトを1つのSnowflakeアカウントから別のアカウントに共有することができます。Snowflake共有は、InboundとOutboundの両方になり得ます。GitLabで使用されているInbound共有は、Zuora Revenueなどのサードパーティデータソースにアクセスするためのものです。ここで従われているメカニズムは直接共有で、データプロバイダーが特定のデータベースオブジェクトを当社のSnowflakeアカウントに共有します。 Outbound共有は、私たちのデータをサードパーティと共有したい場合です。これには、サードパーティアカウント内にsnowflakeオブジェクトのoutbound共有を作成し、共有する必要があるsnowflakeオブジェクト(テーブル、ビュー、データベースなど)へのアクセスを外部アカウントに、Webインターフェイスまたは SQLを使用して付与することが含まれます。
Snowflakeデータ共有は、raw レイヤーの拡張として見なすことができますが、シャードされ(さらに)、異なるアカウントにあります。私たちはSnowflakeデータ共有をデータをコピーする必要があるソースとは見ません。むしろ、raw レイヤーと同じようにSnowflakeデータ共有に直接接続します(つまり、dbtで)。このアプローチにより、余分なプロセスの作成を回避でき、パイプラインがより効率的になります。
これはウェアハウスでの検証と変換の最初のレイヤーですが、まだ一般のビジネス使用の準備ができていません。このデータベースはTableauで使用すべきではありません。
sfdc、zuora)このデータベースとその中のすべてのスキーマとテーブルは、Tableauによってクエリ可能です。このデータは変換され、ビジネス使用のためにモデル化されています。
public と boneyard を除き、すべてのスキーマはdbtによって制御されます。
詳細については、dbt guide を参照してください。
以下の表は、analyticsプロジェクトの models/ ディレクトリ内のフォルダに保存されたモデルが、データウェアハウスでどのようにマテリアライズされるかのマッピングを示しています。
これに関する真実のソースは、dbt_project.yml 設定ファイル にあります。
| snowflake-dbt/models/内のフォルダ | db.schema | 詳細 | Tableauでクエリ可能 |
|---|---|---|---|
| common/ | prod.common | factsとdimensionsのトップレベルフォルダ。ここにはモデルを置かないでください。 | はい |
| common/bridge | prod.common | 異なるソースから来るデータ間のmany-to-manyマッピングを作成するためのサブフォルダ。 | はい |
| common/dimensions_local | prod.common | 各分析エリアのディメンションを含むディレクトリを持つサブフォルダ。 | はい |
| common/dimensions_shared | prod.common | すべての分析エリアに関連するディメンションを持つサブフォルダ。 | はい |
| common/facts_financial | prod.common | 財務分析エリアのfactsを持つサブフォルダ。 | はい |
| common/facts_product_and_engineering | prod.common | productとengineering分析エリアのfactsを持つサブフォルダ。 | はい |
| common/facts_sales_and_marketing | prod.common | salesとmarketing分析エリアのfactsを持つサブフォルダ。 | はい |
| common/sensitive/ | prep.sensitive | 機密データを含むfacts/dims。 | いいえ |
| common_mapping/ | prod.common_mapping | 異なるソースから来るデータ間のone-to-oneマッピングを作成するために使用されます。 | はい |
| common_mart/ | prod.common_mart | すべての分析エリアに関連するjoined dimsとfacts。 | はい |
| common_mart_finance/ | prod.common_mart | financeに関連するjoined dimsとfacts。 | はい |
| common_mart_marketing/ | prod.common_mart | marketingに関連するjoined dimsとfacts。 | はい |
| common_mart_product/ | prod.common_mart | productに関連するjoined dimsとfacts。 | はい |
| common_mart_sales/ | prod.common_mart | salesに関連するjoined dimsとfacts。 | はい |
| common_prep/ | prod.common_prep | mapping、bridge、dims、factsの準備テーブル。 | はい |
| marts/ | varies | mart-levelデータとサードパーティソースにデータを送信するdata pumpsを含みます。 | はい |
| legacy/ | prod.legacy | 非次元の方法で構築されたモデルを含みます | はい |
| sources/ | prep.source | source modelsを含みます。スキーマはデータソースに基づきます | いいえ |
| workspaces/ | prod.workspace_workspace | SQLまたはdbt標準の対象とならないworkspaceモデルを含みます。 | はい |
| common/restricted | prod.restricted_domain_common | 制限付きfactsとdimensionsのトップレベルフォルダ。通常のcommonスキーマと同等ですが、制限付きデータ用。 | はい |
| common_mapping/resticted | prod.restricted_domain_common_mapping | 制限付きmapping、bridge、look-upテーブルを含みます。通常のcommon mappingスキーマと同等ですが、制限付きデータ用。 | はい |
| marts/restricted | prod.restricted_domaincommonmarts | はい | |
| legacy/restricted | prod.restricted_domain_legacy | 非次元の方法で構築された制限付きモデルを含みます。通常のlegacyスキーマと同等ですが、制限付きデータ用。 | はい |
ユーザーのためにデータを保存する必要があり、dbtで自動的に更新しないデータウェアハウスのユースケースには、STATIC データベースを使用します。これにより、アナリストや他のユーザーが自分のデータリソース(テーブル、ビュー、一時テーブル)を作成することもできます。staticデータベース内に機密データ用のsensitiveスキーマがあります。staticのユースケースに機密データの使用または保存が必要な場合は、データエンジニアにissueを作成してください。
STATIC データベースを使用してきたシナリオ:
データソースの1つにデータセットをアップロードするリクエストが来ます。 このデータセットは一度アップロードされ、二度と更新されません。
この場合、STATICデータベースに新しいテーブルを作成し、BULK UPLOAD / COPY コマンドを介してそこにデータをロードしました。次に、このモデルは PREP レイヤーに公開されました。最終モデルは、UNION ステートメントを介してこのテーブルから読み取ります。
この方法では、STATIC データベースにデータを持ち、データソースの完全リフレッシュを実行しても、この手動でアップロードされたレコードセットを含めることができます。
この実装の例は以下にあります:
データマスキングを使用して、データウェアハウス内のプライベートまたは機密情報を不明瞭にします。マスキングは、特定のデータニーズに応じて動的または静的な方法で適用できます。マスキングは、データソースシステムオーナーのリクエストまたはデータチームの裁量で適用できます。現在のデータマスキング方法は、dbtを使用して手続き的に適用されるため、PREP と PROD データベースにのみ適用できます。RAW データベースでマスキングが必要な場合は、代替のマスキング方法を調査する必要があります。
静的データマスキングは、データの変換中に適用され、マスクされた結果がテーブルまたはビューにマテリアライズされます。これは、ロールまたはアクセス権限に関係なく、すべてのユーザーに対してデータをマスクします。これは、dbt内の hash_sensitive_columns macro などのツールを使ってコードで実現されます。
動的マスキングは、Snowflakeの Dynamic Data Masking 機能を使用して、割り当てられたポリシーとユーザーロールに基づき、クエリ実行時に prep と prod レイヤーのテーブルまたはビューに現在適用されます。動的マスキングは、選択されたユーザーに対してはマスクされていない一方、他のすべてのユーザーに対してはマスクされたデータを許可します。これは、テーブルまたはビューの作成時に列に適用されるマスキングポリシーを作成することで実現されます。マスキングポリシーは、データウェアハウスのソースコードリポジトリ内に保持されます。動的マスキングを設定するには、dbt guide を参照してください。
注: 動的マスキングは raw データベースにはまだ適用されていません。
ウェアハウス内のすべてのタイムスタンプデータはUTCで保存される必要があります。Snowflakeセッションの デフォルトタイムゾーン はPTですが、UTCがデフォルトになるようにオーバーライドしています。これは、current_timestamp() がクエリされたとき、結果がUTCで返されることを意味します。
Stitchは明示的に タイムスタンプをUTCに変換します。Fivetranも同様に行います(サポートチャットで確認済み)。
このルールの唯一の例外は、fact tablesでdate_idを作成するためのpacific timeの使用です。これは常に get_date_pt_id dbtマクロによって作成され、_pt_id サフィックスでラベル付けされるべきです。
私たちはデータチームハンドブック全体で複数の場所でスナップショットという用語を使用しますが、コンテキストによってはこの用語は混乱を招く可能性があります。辞書で定義されるスナップショットは「特定の時間におけるストレージ場所またはデータファイルの内容の記録」です。私たちは、この単語を使用するときは常にこの定義を使用するよう努めています。
最も一般的な使用法は、dbt snapshots への言及です。dbt snapshotsが実行されると、source データの現在の状態を取り、対応する snapshot テーブルを更新します。これはソーステーブルの完全な履歴を含むテーブルです。特定のスナップショットが有効である期間を示す valid_to と valid_from フィールドがあります。技術的な詳細については、dbt guideの dbt snapshots セクションを参照してください。
dbt snapshotsによって生成および維持されるテーブルは、raw historical snapshotテーブルです。私たちは、さらなるクエリのためにこれらのraw historical snapshotsの上に下流モデルを構築します。snapshots folder は、dbtモデルを保存する場所です。私たちが構築する可能性のある一般的なモデルの1つは、特定の日(つまり、単一のスナップショット)のための単一のエントリを生成するものです。24時間以内に複数のスナップショットが撮影される場合に便利です。raw historical tableから最も現在のスナップショットを返すモデルも構築します。
私たちのGreenhouseデータはスナップショットとして考えることができます。GreenhouseがSnowflakeにロードする日々のデータベースダンプを提供されています。これらのテーブルのdbt snapshotsを撮影し始めたら、Greenhouseデータの履歴スナップショットを作成することになります。
一部の yaml files の抽出もスナップショットとして考えることができます。この抽出は、ファイル/テーブル全体を取得し、ウェアハウス内の独自のタイムスタンプ付きの行に保存することで動作します。これは、これらのファイル/テーブルの履歴スナップショットを持っていることを意味しますが、これらはdbtと同じ種類のスナップショットではありません。同じ valid_to と valid_from の動作を得るには、追加の変換を行う必要があります。
valid_to がnullのレコードです。yaml extractsでは、これは抽出ジョブが最後に実行された時間に対応します。Greenhouse rawでは、これはウェアハウス内のデータの状態を表します。Greenhouseデータのスナップショットを撮影し始めたら、スピーカーはraw tableまたはhistorical snapshots tableの最新レコードを意味するかどうかを明確にする必要があります。データプラットフォームレベルでのデータバックアップのスコープは、レポート作成と分析の目的でデータの継続性と可用性を確保することです。Snowflakeまたは私たちのSnowflakeプラットフォームでデータに予期せぬ状況が発生した場合、GitLabデータチームはデータを希望する状態に回復および復元することができます。私たちのバックアップポリシーでは、予期せぬイベントのリスクと緩和されたソリューションの影響のバランスを見つけようとしました。
注: (Snowflake)データプラットフォームは、コンプライアンス理由などのため、上流のソースシステムに対するデータアーカイブソリューションとして機能しません。データプラットフォームは、上流のソースシステムで利用可能だったまたは利用可能になっているデータに依存しています。
現在、2種類の予期せぬ状況を特定しています:
これは、GitLab Team MemberまたはSnowflakeのデータにアクセスできるサービスによって行われるデータ操作アクションです。いくつかの例には、誤ってテーブルをドロップ/切り捨てる、または変換で不正確なロジックを実行することが含まれます。
snowflake内のデータの大部分は、私たちの data sources からのコピーまたは派生であり、すべて dbt で 冪等的に 管理されているため、データ復元または回復の最も一般的な手順は、dbt Full Refresh を使用してオブジェクトを再作成またはリフレッシュすることです。私たちの抽出 pipelines から来る RAW データベース内のデータについては、適切なデータリフレッシュ手順に従います。
ただし、これにはいくつかの例外があります。冪等プロセスの結果ではないsnowflake内のデータ、または実用的な時間内にリフレッシュできないものは、バックアップする必要があります。このために、Snowflake Time Travelを使用します。これには以下が含まれます:
データ保持期間はdbt経由で設定されます。これは、dbt post-hook example を介してコードで実装する必要があります。
以下のルールとガイドラインのセットは、データのバックアップ/time travelの使用に適用されます:
現在、Time Travel回復のスコープには以下のsnowflakeオブジェクトが含まれています:
RAW.SNAPSHOTS.*テーブルが保持期間で永続化されたら、これらのテーブルの1つを回復する必要がある場合に Time Travel (internal runbook) を使用できます。
Snowflakeが不確実な期間使用できなくなるという稀なイベントの場合、私たちはさらに、Snowflakeが主要なソースである、ビジネスクリティカルなデータをGoogle Cloud Storage(GCS)にバックアップします。これらのバックアップジョブはdbtの run-operation 機能を使用して実行します。現在、すべての snapshots を日次でバックアップし、60日間(GCS保持ポリシーごと)保持しています。GCS バックアップ手順にテーブルを追加する必要がある場合は、backup manifest 経由で追加する必要があります。
Snowflakeを稼働させ続けるため、私たちは管理作業を実行します。
SnowflakeがGCSバケット内のファイルにアクセスするために、ファイルをSnowflake external stage にコピーする必要があります。
external stageを作成するため、バケットへの新しいパスを STORAGE_ALLOWED_LOCATIONS 属性に含める必要があります(含めるは、既存のストレージ場所のリストに 追加 することを意味します)。追加するのではなく、既存の属性を 上書き すると、既存のすべてのストレージ場所が 消去 され、多くのパイプラインの実行が停止します。
新しいexternal stageを追加するための以下の手順に従ってください:
(注: GCS_INTEGRATION はGCPで gitlab-analysis プロジェクト用のSnowflakeストレージ統合です。バケットが別のプロジェクトにある場合、新しい統合を作成する必要があります。)
これを実行してすべての 現在の ストレージ場所を取得:
DESC INTEGRATION GCS_INTEGRATION;
出力から、property=STORAGE_ALLOWED_LOCATIONS の property_value の値をコピーします。次のように見えます: gcs://postgres_pipeline/,gcs://snowflake_backups/,..。
以下のClaudeプロンプトを特定の値で更新し、Claudeに貼り付けます:
<paste full output here> をステップ1のDESC INTEGRATION出力で置き換える<your new gcs://bucket-path/> を新しいバケットパスで置き換える<database.schema.stage_name> を希望のステージ名で置き換えるClaudeに貼り付けるプロンプト:
Paste output of DESC INTEGRATION GCS_INTEGRATION: <paste full output here>
New bucket path to add: <your new gcs://bucket-path/>
Stage name: <database.schema.stage_name>
Above are existing storage locations, can you please output the correct ALTER STORAGE INTEGRATION and CREATE STAGE commands?
It should be done like:
1. Update the Storage Integration instructions:
* Take the 'current_paths' that you just copied and combine it with the 'new_path' that you want to add.
* Each path needs to be separated by a `,`
* Each path needs to have its own pair of `''`, these need to be added manually
* ALTER statement template:
```sql
ALTER STORAGE INTEGRATION GCS_INTEGRATION
SET STORAGE_ALLOWED_LOCATIONS = ('current_path1','current_path2','new_path');
```
* ALTER statement example:
```sql
ALTER STORAGE INTEGRATION GCS_INTEGRATION
SET STORAGE_ALLOWED_LOCATIONS = ('gcs://postgres_pipeline/','gcs://snowflake_backups/','gcs://snowflake_exports/');
```
2. After you run the ALTER statement, the new stage can now be created, like so:
```sql
CREATE STAGE "RAW"."PTO".pto_load
STORAGE_INTEGRATION = GCS_INTEGRATION URL = 'bucket location';
```
Claudeからの出力を取り、ACCOUNTADMIN ロールを使用して ALTER STORAGE INTEGRATION を実行
Claudeからの出力を取り、LOADER ロールを使用して CREATE STAGE コマンドを実行
COPY INTO が後で失敗した場合、GCP Consoleのバケットに移動し、Permissionsタブに移動し、サービスアカウント [email protected] に Storage Object Viewer ロールを付与します
このガイドでは、既存のSnowflakeストレージ統合を使用してSnowflakeに新しいS3バケットへのアクセスを許可する方法について説明します。
プロセスには以下が含まれます:
config-mgmt レポへのアクセス、特に aws-gitlab-analysis 環境への。ACCOUNTADMIN ロールでのSnowflakeアカウントアクセスaws-gitlab-analysis 環境でTerraformを介して新しいS3バケットを作成:
resource "aws_s3_bucket" "some_new_bucket" {
bucket = "your-new-bucket-name"
# Add other configuration as needed
}
前のステップと同じレポで、GitLabのポリシーファイルに移動:
environments/aws-gitlab-analysis/templates/iam_policy_snowflake_s3_integration.json既存のバケットと同じパターンで、Resource 配列の下に新しいバケットパスを追加します。
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:GetObjectVersion",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::your-new-bucket-name/*",
"arn:aws:s3:::your-new-bucket-name"
]
}
config-mgmtレポの任意の変更と同様に、承認を取得し、その後 atlantis apply を実行して変更をデプロイします
新しいバケットをSnowflakeの許可されたストレージ場所に追加します:
ACCOUNTADMIN ロールを使用
Snowflakeストレージ統合を更新します。既存のバケットのリストに新しいバケットを 必ず追加 してください:
ALTER STORAGE INTEGRATION S3_DATA_PUMP
SET STORAGE_ALLOWED_LOCATIONS = ('s3://existing-bucket-1/', 's3://existing-bucket-2/', 's3://your-new-bucket-name/');
統合設定を検証します:
DESC INTEGRATION S3_DATA_PUMP;
注: 私たちは S3_DATA_PUMP Snowflakeストレージ統合をSnowplowインスタンスが実行されているメインAWSプロジェクトでS3への接続を確立する責任のあるジェネリックなものとして扱っています。顧客が提供したものなど、異なるプロジェクトに新しいバケットがある場合は、そのAWSプロジェクト用に新しいSnowflake統合を作成する必要があります、Snowflake docs。
すべてが正しく動作していることを確認するには:
すべての変換に dbt を使用します。 このツールを使用する理由と方法の詳細については、dbt guide を参照してください。
データ顧客は、重要な決定を行うために信頼できるデータをデータチームが提供することを期待しています。そして、データチームは提供するデータの品質に自信を持つ必要があります。しかし、これは解決が難しい問題です: Enterprise Data Platformは複雑であり、データ処理と変換の複数の段階が含まれており、数十から数百の開発者とエンドユーザーが24時間ずっと積極的にデータを変更およびクエリしています。Trusted Data Framework(TDF)は、技術チーム とビジネスチーム がアクセスできる、データ処理段階全体でのデータテストと監視の標準フレームワークを定義することで、これらの品質と信頼のニーズをサポートします。既存のデータ処理技術とは別個のスタンドアロンモジュールとして実装されたTDFは、独立したデータ監視ソリューションの必要性を満たします。
TDFの主要要素には以下が含まれます:
TDFは、ビジネスユーザーを 信頼されたデータを確立する最も重要な参加者 として受け入れ、シンプルでアクセス可能なテストモデルを使用します。テストエージェントとしてSQLとYAMLを使用すると、幅広い人々がテストケースに貢献できます。テスト形式はシンプルなPASS/FAIL結果と4つのテストケースタイプだけで、わかりやすいです。TDFが価値を示すにつれて、採用は急速に成長します:
時間が経つにつれ、日次で実行され、データ品質を継続的に検証する数百のテストケースを開発することは珍しくありません。
SQLはデータベースの普遍的な言語であり、データを扱うほぼ全員がある程度のSQL能力を持っています。ただし、SQLに慣れていない可能性のある全員、貢献できる人を制限したくありません。私たちは、TDFをサポートするために dbt を使用し、SQL と YAMLを介してテストを定義できるようにします。
すべてのテストがdbtを介して実行されると、テスト結果の保存はシンプルです。すべてのテスト実行の結果をデータウェアハウスに保存します。テスト結果を保存することで、以下を含むさまざまな貴重な機能が可能になります:
これらのテスト結果はパースされ、Tableauでクエリ可能です。
すべてのテスト結果を保存するスキーマは WORKSPACE_DATA です。
注: このスキーマにはビューのみが含まれます。
データウェアハウス環境は急速に変化する可能性があり、TDFは変化する可能性の高いデータウェアハウスの領域のテストカバレッジで、予測可能性、安定性、品質をサポートします:
これらのテストの実装の詳細は、dbt guide で文書化されています。
データチームは、信頼されたデータダッシュボードと、信頼されたデータとして認定された公開Tableauデータソースを整理するためのダッシュボードまたはコレクションの使用に取り組んでいます。
詳細は今後追加されます。
行数テストは、ソースDBテーブルからデータを抽出してSnowflakeテーブルにロードし、Snowflakeから同様の統計を抽出してソースとターゲット間の比較を実行することで、ソースデータベースとターゲットデータベース間の行数を調整します。ソースとターゲット間で正確な一致を取得することには課題があります、なぜなら:
シナリオに応じて、最高(テーブル)レベルではなく、より低い粒度レベルで行数を確認することが推奨されます。これは、論理的な分布を持つ1つ以上のフィールドであり得ますが、集約レベルにとどまります。例として、テーブル内の挿入または更新日があり得ます。
ソースからの行数とターゲット(Snowflakeデータウェアハウス)の行数に基づいて、すべての行がデータウェアハウスにロードされたかどうかを判断するための調整を実行できます。
フレームワークは、テストを実行するための任意の種類のクエリの実行を処理するように設計されています。現在のアーキテクチャでは、すべてのクエリは1つのKubernetesポッドを作成するため、1つのクエリにグループ化することで、Kubernetesポッドの作成数が減ります。postgres DBとsnowflake間のレコード数とデータの実際のテストでは、低ボリュームのソーステーブルを一緒にグループ化し、大ボリュームのソーステーブルを個別タスクとして実行するアプローチが従われています。
新しいyamlファイルが作成され、すべての種類の調整を実行することになっています(したがって、既存のyaml抽出マニフェストには組み込まれていません)。マニフェストファイルは、低ボリュームテーブルのグループを一緒に、大ボリュームテーブルを個別タスクとして組み合わせます。Postgresとsnowflakeからの行数比較は、“PROD”.“WORKSPACE_DATA”.“PGP_SNOWFLAKE_COUNTS"という名前のsnowflakeテーブルに保存されます。
Snowflake から GitLab の Tech Stack 内の他のアプリケーションにデータを送信するため、Enterprise Applications Integration Engineeringチームと提携して、Data Pump と呼ばれるデータ統合フレームワークを構築しました。これは、データをS3に抽出し、Workato処理が下流でさらに行われます。もう1つのルートは現在 セットアップ されており、Fivetran(統合)を介してSnowflakeから下流のシステムにデータを直接プッシュできます。
graph LR
yml>pumps.yml]
dataModel[(data model)] --> o{{Airflow DAG}}
yml --> o
o --> S3
S3 --> workato{{Workato recipe}} --> target[(Target)]dbtモデル(例: pump_smb_daily_case_automation)はSnowflakeでマテリアライズされます。Data Pump Airflow DAG は、その後、結果をデータチームの gitlab-com-snowflake-data-pump S3バケットに直接エクスポートします。そこで、Workato recipeがそれを取り上げ、ターゲットアプリケーションに配信します。
現在のスケジュール:
⚠️ このプロセス全体は固定時間スケジュールで時間トリガーされており、データレイテンシが(より)高くなる可能性があることに注意してください。dbt DAGの完了に近いAirflow Exportsをスケジュールしてレイテンシを減らす follow-up issue があります。
| 時間 (UTC) | ステップ |
|---|---|
| 05:00 | Airflow が PROD.pumps_sensitive.pump_smb_daily_case_automation を S3 にエクスポート |
| ~11:00 | dbt-combined-product-models-run が PROD.pumps_sensitive.pump_smb_daily_case_automation をリフレッシュ |
ステップ1: dbtを使用 して、/marts/pumps(モデルが RED or ORANGE Data を含む場合は /marts/pumps_sensitive)にデータモデルを作成し、私たちの SQL と dbt スタイルとドキュメンテーション標準に従います。dbtモデルチェンジテンプレートを使用してMRを作成します。これがマージされて PROD.PUMPS または PROD.PUMPS_SENSITIVE のSnowflakeに表示されると、ステップ2と3の準備ができます。
ステップ2: ‘Pump Changes’ MRテンプレートを使用して、以下の属性で pumps.yml にModelを追加します:
null、テーブルが小さい場合)TrueTrue。複数のファイルを書き込める場合は Falseステップ3: ‘change’ issueテンプレートを使用して、Integrationチームがデータをターゲットアプリケーションにマップして統合できるように、platypusプロジェクトのissue を作成します。
| モデル | ターゲットシステム | RF | MNPI |
|---|---|---|---|
| pump_hash_marketing_contact | Marketo | 24h | No |
| pump_marketing_contact | Marketo | 24h | No |
| pump_marketing_premium_to_ultimate | Marketo | 24h | No |
| pump_subscription_product_usage | Salesforce | 24h | No |
| pump_product_usage_free_user_metrics_monthly | Salesforce | 24h | No |
| pump_daily_data_science_scores | Salesforce | 24h | Yes |
| pump_churn_forecasting_scores | Salesforce | 24h | Yes |
Daily Data Science Scores Pump と Pump Churn Forecasting Scores Pump は、data scienceに関連するデータをSnowflakeからS3に持ち込むためのdata pumpの2つの特定のユースケースで、Openpriseによってピックアップされ、Salesforceにロードできます。
Daily Data Science Scores pumpのソースモデルである mart_crm_account_id には、PtE と PtC スコアの組み合わせが含まれていますが、Churn Forecasting Scores pumpのソースモデルである mart_crm_subscription_id には、Churn Forecasting モデルに厳密に関連するスコアが含まれています。
Email Data Mart は、構造化された対象を絞ったコミュニケーションの作成を可能にするため、Marketoへの更新を自動的に駆動するように設計されています。
Data Model to Gainsight Pump は、Customer Successが顧客のGitLab使用を成功させるための視覚化、アクションプラン、戦略の作成を可能にするため、Gainsightへの更新を自動的に駆動するように設計されています。
Qualtricsメーリングリストデータポンププロセス(コード内ではQualtrics SheetLoadとも呼ばれる)は、データウェアハウスからQualtricsへ、最初にチームメンバーのマシンにダウンロードされる必要なく、メールをアップロードできるようにします。このプロセスは、qualtrics_mailing_list で始まる名前のファイルを探すため、SheetLoadと同じ名前を共有します。最初の列として id 列を持つ見つかった各ファイルについて、そのファイルをSnowflakeにアップロードします。結果のテーブルは、メールアドレスを取得するためにGitLabユーザーテーブルと結合されます。結果はQualtricsに新しいメーリングリストとしてアップロードされます。
プロセス中、Google Sheetが更新され、プロセスのステータスが反映されます。最初の列の名前は、プロセスが開始されたときに processing に設定され、その後メーリングリストと連絡先がQualtricsにアップロードされたときに processed に設定されます。列の名前を変更することで、リクエスト者にプロセスのステータスが通知され、デバッグの支援、そして各スプレッドシートに対してメーリングリストが一度だけ作成されることが確実になります。
エンドユーザー体験は UX Qualtrics page で説明されています。
スプレッドシートにエラーがあり、リクエストファイル自体に明らかな問題がない場合、スプレッドシートを再処理することが通常最初の行動です。再処理は、新しいGitLabプランの名前が gitlab_api_formatted_contacts dbtモデルに追加されたとき、およびファイルの処理中にAirflowタスクがハングしたときに、過去に必要でした。このプロセスは、スプレッドシートの所有者との調整、またはリクエスト時にのみ実行されるべきで、彼らがプロセスによって作成された部分的なメーリングリストを使用していないこと、およびスプレッドシートに追加の変更を行っていないことを確認できるようにします。
Qualtricsメーリングリストリクエストファイルを再処理するには:
1. AirflowでQualtrics Sheetload DAGを無効にします。
2. エラーが発生しているスプレッドシートから作成されたQualtricsの任意のメーリングリストを削除します。Qualtrics - API user 認証情報を使用してQualtricsにログインし、メーリングリストを削除できるはずです。メーリングリストの名前は、qualtrics_mailing_list. の後のスプレッドシートファイルの名前に対応します。これはスプレッドシートファイルのタブの名前と同じである必要もあります。
3. エラーが発生しているファイルのセルA1を id に編集します。
4. AirflowでQualtrics Sheetload DAGを再度有効にし、Airflowタスクログを密接に監視しながら実行させます。
Data Spigotは、外部システムがSnowflakeデータに制御された方法でアクセスする概念/方法論です。Snowflakeへの外部システムのアクセスを提供するため、以下の制御が設定されています:
新しいData Spigotを設定するプロセスは以下です:
| 接続システム | データスコープ | データベーステーブル/ビュー | MNPI |
|---|---|---|---|
| Grafana | Snowplowロード時間 | prod.legacy.snowplow_page_views_all_grafana_spigot | No |
| Gainsight | prod.common_prep.prep_usage_ping_no_license_key | No | |
| Gainsight | prod.common_mart_product.mart_product_usage_wave_1_3_metrics_latest | No | |
| Gainsight | prod.common_mart_product.mart_product_usage_wave_1_3_metrics_monthly | No | |
| Gainsight | prod.common_mart_product.mart_product_usage_wave_1_3_metrics_monthly_diff | No | |
| Gainsight | prod.common_mart_product.mart_saas_product_usage_metrics_monthly | No | |
| Gainsight | prod.common_mart_product.mart_product_usage_paid_user_metrics_monthly | No | |
| Gainsight | prod.common_mart_product.mart_product_usage_free_user_metrics_monthly | No | |
| Gainsight | prod.restricted_safe_common_mart_sales.mart_arr | Yes | |
| Salesforce | mart_product_usage_paid_user_metrics_monthly, mart_product_usage_paid_user_metrics_monthly_report_view | No | |
| Zapier | t.b.d. | prod.workspace_customer_success.mart_product_usage_health_score | No |
Sales Systems Use-Case: Snowflake APIの使用
データの重複排除は、Snowflakeでのデータ品質の確保とストレージおよびコンピュートコストの削減に不可欠です。現在のGitLab.comパイプラインは、インクリメンタル抽出が実現可能でない特定のテーブル、およびSlowly Changing Dimensions(SCD)モデリングを目的としたテーブルに対して、完全なデータ抽出を実行するように設計されています。ソースシステムでの欠落したトランザクションを確認するため、インクリメンタル抽出テーブルは一貫して30分間オーバーラップします。
さらに、別のアプリケーションCustomersDotから取得されたすべてのデータは、各抽出が下流のSCDの構築に役割を果たすため、1日に2回完全に抽出されます。
サービスレベル目標(SLO)とサービスレベル契約(SLA)の削減のニーズに対応するため、私たちはCustomersDotとGitLab.comの両方でより頻繁な抽出に移行しました。この調整により、Snowflakeで重複レコードが増加し、完全およびインクリメンタル抽出に関連するテーブルのストレージ要件が高くなりました。重複の増加は、これらのデータソースのdbtモデルおよびdbtテストの結果に時間とともに悪影響を与えました。
dbtの実行時間を短縮し、Snowflakeのコンピューティングとストレージの効率を強化するため、これらのデータソースを特定的に対象とする重複排除フレームワークを開発しました。このフレームワークは、重複レコードが蓄積する可能性のあるSnowflake内の他のデータソースに簡単に拡張できます。
重複排除フレームワークは、2つの主要コンポーネントで構成されています:
Airflow: Airflowは3つの重複排除DAGで構成されています:
t_deduplication_gitlab_com_incrementalt_deduplication_gitlab_db_scdt_gitlab_customers_db_dbtgitlab_data_extractパイプラインの一部としてマニフェストファイルでデータを抽出するテーブルのリストを維持しているため、Airflowは、重複排除ロジックを実行する必要のあるテーブルのリストを取得するために、正確な真実のソースに依存します。DAGは週次で実行するようにスケジュールされています。
Snowflake: Snowflakeでは、以下のアクティビティが実行されます:
TAP_POSTGRES_BKP スキーマで、タイムスタンプサフィックス付きのSnowflake clone コマンドを使用して作成されます。temporary テーブルが作成され、GROUP BY 句を使用して重複を排除しながら最も最近のレコードを保持し、_uploaded_at や _task_instance などの特別な列を管理する重複排除データセットを作成します。重複排除ロジックは、テーブルからすべてのユニークな行を選択します。私たちは、Data VisualizationおよびBusiness Intelligenceツールとして Tableau を使用しています。アクセスをリクエストするには、access request を提出してください。Tableauアクセスリクエストには、Tableau_Rquest テンプレートを使用してください。
GitLabのパスワードポリシーごとに、パスワードのみで認証されるサービスアカウントを90日ごとにローテーションします。変更されたシステムと、それらのパスワードが更新された場所の記録は このGoogle Sheet で保持されています。
私たちはまた、3か月ごとの月の最初の日曜日(1月、4月、7月、10月)に、Snowflake Password Reset DAG を介してSnowflakeユーザーパスワードをローテーションします。
データチームは、データチームが管理するツール内のユーザーをプロビジョニングする責任があります。これには、Tableau、MonteCarlo、Fivetran、Stitch、Snowflakeなどのツールが含まれます。
Snowflakeについては、このページの Snowflake Permissions Paradigm セクションで文書化された強固なプロセスがあります。
その他のツールについては、UIおよび存在する場合は適切な Googleグループ でユーザーを追加します。
Stitchの新しいユーザーは、デフォルトで General ロールに追加されるべきです。このロールは、新しい抽出の作成、既存の抽出の変更、実行中の抽出のトラブルシューティングを行うのに十分なStitchへのアクセスを与えます。Stitchプロビジョニングは2段階のプロセスです。最初に、IT operationsチームがAccess Requestを完了することで、チームメンバーをapp.stitch Oktaグループに追加します。2番目のステップは、Stitchアプリケーションにユーザーのメールを追加することを含みます。
Google Driveのように、すべてのGitLabチームメンバーはGoogleの Data Studio へのアクセスを持ち、これはGoogle Sheetsまたは他のGoogleデータソースからのデータでダッシュボードを構築するために使用できます。したがって、Google Data Studioへのアクセスをプロビジョニングするためのアクセスリクエストは必要ありません。 Google Data Studioは、Google Analyticsの使用でマーケティングに特に人気があります。これは上記で説明したプラットフォームの外部にありますが、Google’s Data Studio内で管理されているデータは、プラットフォームの残りの部分と同じ Data Categorization and Management Policies に従う必要があります。
Google Data Studioで利用可能な3つのタイプのオブジェクトがあります:
Data Studioでの共有とアクセスプロセスは、Google Drive / Google Docsでの共有と同等です。Google Studioオブジェクトは、GitLab組織アカウントの個人または組織全体と共有できます。グループまたはロールレベルの権限は利用できません。Data studioでダッシュボードとデータソースを管理する分散型の品質を考えると、ビジネスクリティカルなデータとレポートは最終的にSnowflakeとTableauに移行することをお勧めします。これは、sheetload またはBigQueryコネクタを持つFiveTranの使用により、簡単になります。
Google Studioでアーティファクトを作成するGitLabチームメンバーは、その特定のオブジェクトのオーナー権限を所有します。所有権により、GitLabチームメンバーはGitLab内外でデータを SAFE に保つ責任を持ちます。Google Data Studioは現在、所有権を引き継ぐことができる管理インターフェイスを提供していません。オフボーディング時、業務継続性を確保するため、既存オブジェクトの所有権はそれぞれのオブジェクトのオーナーによって引き継がれるべきです。Red Data はGoogle Data Studio内で保存または転送されるべきではないことに注意してください。
Sales Analytics には、人間の介入なしに自動的に実行できることから利益を得るいくつかの(拡大している)定期的な更新プロセスがあります。
そのいくつかは以下です:
Snowflake に直接アップロードできます。このため、スケジュールごとに、複数のAirflowのdagsで構成されるソリューションを実装しました。
現時点では(さらなるイテレーションと変更の対象)、ステップは以下です:
Sales AnalystがPythonノートブック(サンプルノートブック)で作業し、プロダクション用に準備します(セル実行結果がクリアされ、ローカル変数/シークレットが残っていないことなどを確認します)
Sales Analystは、ノートブックを実行すべきスケジュールに応じて、対応するフォルダにノートブックとそのそれぞれのクエリをアップロードします。https://gitlab.com/gitlab-data/analytics/-/tree/master/sales_analytics_notebooks の下にある利用可能なスケジュール(およびしたがってフォルダ)は:
これは、各スケジュールに対する1つの主要DAG(合計4つ)を作成することで実装されており、そのスケジュールに対するノートブック数と同じだけのタスクで構成されます。新しいタスクは、ノートブックがリポジトリにコミットされるときに、DAGに動的に追加されます。
dagsのコードは gitlab-data/analyticsプロジェクトのSales Analytics Dags で見つけることができます。
現在、/daily/ ノートブックの下に、1つのサンプルノートブックとそれに対応するクエリ があります。
このノートブックは日次で実行され、実行中に生成されたスコアは、Snowflake の RAW.SALES_ANALYTICS スキーマにロードされます。
このデータをTableauで利用可能にするには、プロダクションデータベースのビューとして公開するため、PROD.WORKSPACE_SALES スキーマの下に dbt モデルを書く必要があります。
そのため、Sales Analystは、gitlab-data/analytics プロジェクトに直接MRをオープンするか、このプロジェクトでissueを作成して、データプラットフォームエンジニアが必要なdbtモデルを実装することができます。
これらのスケジュールの希望する曜日/時間を変更するには、Sales Analystは gitlab-data/analytics プロジェクトでissueをオープンできます。
Dagの失敗アラートは、Airflowから #sales-analytics-pipelines に送信されるため、Sales Analystsはノートブックでのエラーを監視できます
エラーがプラットフォーム関連のように見える場合、Sales AnalystはSlack(#data-engineering チャンネル経由)またはissueを gitlab-data/analytics プロジェクトでオープンすることで、データプラットフォームエンジニアに連絡できます
GitLabdataライブラリ(Link to PyPi、Link to the source code)に、GSheetsファイルからの読み取りとへの書き込みを可能にするいくつかの新しい関数が追加されました。
関数は read_from_gsheets (link to function source code) と呼ばれ、spreadsheet_id と sheet_name をパラメータとして受け入れ、dataframe を返します。
⚠️ 特定のシートは、関連する
gCloud SERVICE ACCOUNTユーザーのメールアカウントと共有される必要があります(System Set Upを参照)。
関数は write_to_gsheets (link to function source code) と呼ばれ、spreadsheet_id、sheet_name、dataframe をパラメータとして受け入れます。
⚠️ 特定のシートは、関連する
gCloud SERVICE ACCOUNTユーザーのメールアカウントと共有される必要があります(System Set Upを参照)。
プロダクションのユースケースのため、サービスユーザーが提供されており、認証情報は Data Team Secure Vault の GCP Service Account for Exporting to GSheets の下に保存されています。
⚠️ 特定のシートは、この関数を呼び出す前にサービスアカウントユーザーのメール(
[email protected])と共有される必要があります。そうでないと、アカウントはシートに書き込んだり、読み取ったりできません。
ローカル開発のため、GSHEETS_SERVICE_ACCOUNT_CREDENTIALS 環境変数をチームの gCloud SERVICE ACCOUNT Credentialの値で設定する必要があります(実際のJSON内容がこの環境変数の値である必要があり、パスではありません。)
これは、選択したターミナルで以下のコマンドを実行することで行えます: export GSHEETS_SERVICE_ACCOUNT_CREDENTIALS = 'JSON_CREDENTIAL_CONTENTS'
セキュリティの高い基準を維持し、潜在的な侵害を回避するため、各チームが独自の gCloud SERVICE ACCOUNT をリクエストして管理することが要求されます。
GCPチームは、ユーザー/GCPプロジェクトの作成をサポートできます。Revenue Strategy and AnalyticsチームのService Accountを作成するためのissueの例はこちらです。
gCloud SERVICE ACCOUNT には Google Workspace Delegated Admin 権限が必要です。
⚠️ 特定のシートは、この関数を呼び出す前に
gCloud SERVICE ACCOUNTユーザーのメールと共有される必要があります。そうでないと、アカウントはシートに書き込んだり、読み取ったりできません。
Sales Systems チームは、Snowflakeに対して1日に複数回同じクエリを実行し、そのデータをSalesforceにロードする必要があります。
データチームは、Sales AnalyticsチームがデータをマニュアルでダウンロードしてSalesforceにアップロードする代わりにこのプロセスを自動化できるように、APIユーザーを提供しました。 このユースケースの詳細は、元のissue #15456 で見つけることができます。
データベースから引き出されたデータは、リクエストされたデータのみを厳密に公開するビューにカプセル化されており、sales systemsチームはSnowflake API経由でこのビューを直接クエリします。
このユースケースのためにSnowflakeで SALES_SYSTEMS_SNOWFLAKE_API_ROLE という新しいロールが特定的に作成され、基礎となるビューに対する読み取りアクセスのみを持つように設定されています。
Snowflake APIユーザーは、Using Key Pair Authentication のSnowflake公式ドキュメンテーションのステップに従って作成されました。認証情報はData Team Secure Vaultに保存されており、Sales Systemsチームと共有されることになっています。
この目的のためのユーザーとロールの作成方法のステップバイステップガイドのrunbookを作成しました - Snowflake API Userへのリンク runbook。
この標準への例外は、情報セキュリティポリシー例外管理プロセスに従って追跡されます。
プラットフォーム インフラストラクチャ
c955a93f)