Incident Follow Up Issues
このページでは、インシデントからのフォローアップ項目を管理するプロセスを記述します。
用語 Follow Up Item: インシデント中に特定された、インシデント解決後に対処する必要のあるアクション …
インシデントとは、サービス低下や停止につながる、またはつながる可能性のある 異常な状態 です。これらのイベントは、混乱を回避するため、またはサービスを運用可能な状態に復元するために人の介入を必要とします。 インシデントには常に即座の対応が与えられます。
インシデント管理の目標は、混乱を整理して迅速なインシデント解決へ導くことです。そのために、インシデント管理は以下を提供します:
インシデントが開始する と、インシデント自動化がテキストベースのコミュニケーション用のインシデントごとの Slack チャンネルへのリンクを含むメッセージを、対応する インシデント告知チャンネル に送信します。 インシデントチャンネル内に、インシデントごとの Zoom リンクが作成されます。 さらに、Production tracker に GitLab Issue が作成されます。
GitLab では、インシデント管理を以下のステップを持つフィードバックループとして捉えています:
私たちのモニタリングとアラートの概要については、モニタリングハンドブックページ を参照してください。必要に応じて開発チームから専門知識を得るために、開発エスカレーションプロセス も活用しています。
インシデントパフォーマンスは、一連の目標メトリクス(MTTR、30 分以内に軽減された割合、内部検出された割合など)に対して追跡されます。定義、スコープ、ダッシュボードへのリンクは Incident Metrics ページに記載されています。
C1 の計画メンテナンスは、宣言されていないインシデントとして扱うべきです。
メンテナンスウィンドウが始まる 30 分前に、変更を担当する Engineering Manager は、メンテナンスが始まろうとしていることを SRE オンコール、Release Manager、CMOC に通知すべきです。
調整とコミュニケーションは Situation Room Zoom で行うべきで、メンテナンスに問題が発生した場合に他のエンジニアを迅速・容易に巻き込めるようにします。
メンテナンス手順中に関連するインシデントが発生した場合、その EM はインシデントの間 Incident Manager として機能すべきです。
メンテナンス手順中に別の無関係なインシデントが発生した場合、計画メンテナンスに関わっているエンジニアは、進行中のインシデントを優先するために Situation Room Zoom から退出すべきです。
計画メンテナンス中に短時間のエラーが予想される場合、これも関連するステータスページの更新を通じてユーザーに伝達するべきです。 メンテナンスの時間を Service Level Agreement へのダウンタイムとしてカウントしないために、メンテナンスウィンドウを設定 する必要もあります。
Incident Lead の役割は、すべてのインシデントに対して意図的に設定する必要があります。インシデントのオーナーの判断に助けが必要な場合、EOC が支援できます。 Incident Lead はいつでもオーナーシップを別のエンジニアに委譲したり、IM にエスカレーションしたりすることができます。 インシデントのオーナーは常に 1 人 で、そのオーナーのみがインシデントを解決済みと宣言できます。 Incident Lead はいつでも、サポートを得るために階層の次の役割を呼び出すことができます。Incident Lead の役割は常に現在のオーナーに割り当てられるべきです。
GitLab では、インシデント管理フレームワークは 2 つの重要な概念を区別します:
インシデント対応役割: インシデント対応中に必要な機能的なポジションで、それを誰が担うかに関わらず、特定の責任とアクションで定義されます。現在、Incident Lead、Incident Responder、Communications Manager の 3 つの役割が定義されています。
対応チーム: これらの役割を担う特定のチームとローテーションです。異なる対応チームが異なる環境(例: GitLab.com 対 Dedicated)または特化された機能をカバーする場合があります。
この区別を理解することで、インシデント中に誰が何をするかが明確になり、インシデント管理プロセス全体での適切な調整が可能になります。
Incident Response Roles vs. Teams の詳細を視聴する
インシデント中の責任の明確な区切りは重要です。迅速な解決には、フォーカスとタスク委譲のための明確な階層が必要です。重複を防ぎ、適切な操作順序を確保することは、軽減の鍵です。
| 役割 | 説明 | 必要な時 |
|---|---|---|
| Incident Lead | インシデントのオーナーで、インシデント対応の調整を担当し、インシデントを解決へと導きます。Incident Lead は常に incident.io 内でこの役割が割り当てられるべきです。 | すべてのインシデントは Incident Lead を必要とし、インシデントごとに意図的に設定する必要があります。Incident Lead の選び方の詳細は ワークフローセクション を参照してください |
| Incident Responder | 技術的な調査と軽減を実施します。インシデントを引き起こしている技術的問題の実際のトラブルシューティングと解決に責任を負います。 | すべてのインシデント |
| Communications Lead | 複数のメディアを通じてステークホルダーと顧客に情報を発信します。外部コミュニケーションとステータスアップデートを管理します。 | S1/S2 インシデント、または重要なコミュニケーションが必要な場合 |
私たちは、オンコールスケジュールを維持することで、インシデントを解決できるチームメンバーがいることを確実にしています。
オンコールのチームメンバーがページされるとインシデントに参加し、上記のインシデント対応役割のいずれかを担います。
オンコールプロセスとポリシーの詳細は、オンコールハンドブックページ にあります。
以下は、インシデント解決をサポートするオンコールローテーションのサマリーです:
自動システムによって通知されるオンコールローテーション:
| チーム | 主な役割 | 機能 | 環境 | 誰? |
|---|---|---|---|---|
| Engineer On Call (EOC) | Incident Responder | 主に自動アラートおよび GitLab.com エスカレーションに対する最初の Incident Responder として機能します。役割への期待は オンコールに関するハンドブック にあります。EOC のチェックリストは runbooks にあります。EOC が広範な問題のトラブルシューティングを支援するために設計されたランブックがあります - ランブックが不十分な場合、EOC は Incident Manager と CMOC を関与させる ことでエスカレーションします。 | GitLab.com | 一般的に SRE で、インシデントを宣言できます。incident.io の “GitLab.com Production EOC” オンコールスケジュールの一部です。 |
| Incident Manager On Call (IMOC) | Incident Lead | 複雑なインシデント中に戦術的な調整とリーダーシップを提供します | GitLab.com | incident.io のローテーション |
低重大度のインシデントでは、ページされた個人が複数の役割を担う場合があります。例えば S4 インシデントでは、EOC が Incident Lead と Incident Responder の両方を兼ねる場合があります。重大度が上がるにつれて、これらの役割を別々の個人が担うことがより重要になります。 Tier 2 の人がページされる必要があります。
人間によって通知されるオンコールローテーション:
| チーム | 役割 | 機能 | 環境 | 誰? |
|---|---|---|---|---|
| Communications Manager On Call (CMOC) | Communications Lead | Communications Manager の役割を担います | すべての環境 | 一般的に GitLab のサポートチームのメンバー。 |
| Infrastructure Leadership | n/a | 高重大度のインシデントに対するエスカレーションサポートを提供し、#cto を最新に保つことを含みます。 | すべての環境 | Infrastructure、Platform 部門の Staff+ または EM。 |
| Subject Matter Expert (Tier 2 SME) | Incident Responder | インシデント中のサポートを提供できる特定の知識を持つエンジニア | GitLab.com / Dedicated | 特定の知識を持つエンジニア |
この表は、インシデント対応中に通常どのチームがどの役割を担うかを示しています:
| 役割 | 主なチーム | 代替チーム |
|---|---|---|
| Incident Lead | インシデントタイプによって異なる (Incident Lead 参照) | EOC、IMOC、Product Engineers |
| Incident Responder | EOC | Product Engineers、その他の Subject Matter Experts |
| Communications Lead | CMOC | N/A |
Incident Lead は、インシデントが進行し最新の状態に保たれることを保証する責任を負います。この役割は自動的には設定されず、インシデントのタイプに基づいて割り当てるべきです。Incident Lead の割り当てのガイダンスについては、ワークフローセクション を参照してください。Incident Lead は、必要に応じて EOC や IMOC など他の関係者を関与させる権限があると感じるべきです。
Incident Lead の責任 のより詳細な内訳を参照してください。
Incident Responder は、インシデントの技術的な調査と解決に貢献するすべての人です。EOC チームが通常一次対応者として機能しますが、関連する専門知識を持つ GitLab のチームメンバーは誰でも支援を求められることがあります。
Incident Responder の責任 のより詳細な内訳を参照してください。
Communications Lead は、ステータスページ更新の管理、ステークホルダー通知の調整、確認された重大な外部顧客影響のあるインシデントに関するタイムリーな公開コミュニケーションの確保によって、深刻なインシデント中の GitLab の公式な声として機能します。
複数のチャンネルにわたる調整されたコミュニケーションを必要とする深刻なインシデントでは、IMOC はインシデントの期間中 Communications Lead に頼ります。
Communications Lead の責任 のより詳細な内訳を参照してください。
Engineer On Call は通常、主な Incident Responder として機能し、宣言されたインシデントの影響軽減と解決を担当します。EOC は、助けが必要な場合、または他の人をインシデント調査に支援するために必要な場合、IMOC に連絡すべきです。
EOC は Incident Responder の責任 を確認すべきです。
Incident Manager On Call は通常、Incident Lead として機能し、インシデント中の戦術的なリーダーシップと調整を担当します。
IMOC は、Incident Lead が低重大度のインシデントの多くで Communications Lead としても機能する可能性があるため、Incident Lead の責任 と Communications Lead の責任 の両方を確認すべきです。
シフトのスケジュール方法、PTO を取るときや代替が必要なときに何をするかについての一般的な情報は、Incident Manager オンボーディングドキュメント を参照してください
Infrastructure Leadership は、Engineer On Call (EOC) と Incident Manager On Call (IMOC) の両方のエスカレーションパス上にあります。 これはアクティブな IMOC の代用または置き換えではありません(現在の IMOC が対応できない場合を除く)。
Infrastructure Leadership を直接ページするには、/inc escalate を実行し、Oncall Teams ドロップダウンメニューから Infrastructure leadership escalation を選択してください。
以下の状況でページされます:
ページされると、Infrastructure Leadership は以下を行います:
Infrastructure Leadership は、すべての S1 インシデントについて、インシデントオープン時、重要なステータス変更時 (例: Investigating から Fixing)、およびインシデント解決時に、GitLab.com と GitLab Dedicated の両方のインシデントについて #cto Slack チャンネルに更新を行うべきです。 更新は GitLab.com で使用される標準の incident.io Summary 形式に従うべきで、通常はインシデントサマリーからコピー&ペーストできます。 既存のサマリーが不十分な場合、@incident Slack ボットにインシデント用の executive summary をドラフトするよう依頼できます。
:s1: **Incident on GitLab.com**
**Problem**:
(include high level summary)
**Impact**:
(describe the impact to users including which service/access methods and what percentage of users)
**Causes**:
(List of causes if known)
**Response Strategy**:
(What we're doing to remediate the issue)
**— Production Issue —**
Main incident: (link to the incident)
Slack Channel: (link to incident slack channel)
~IM-Onboarding::Ready および ~IM-Offboarding の Issue をレビューし、それらのチームメンバーをスケジュールに追加します。#im-general にスケジュールが変更されたことを示すお知らせを投稿し、MR へのリンクと追加/削除された人の簡単な概要を共有します。EOC コーディネーターは、SRE オンコールの QoL を改善し、社内全体のオンコールエンジニアが高い自信のレベルで運用できるようにするためのプロセスを構築することに焦点を当てています。
この役割の責任:
EOC コーディネーターは、コアなオンコールとインシデント管理の懸念について Ops チームと密接に協力し、必要に応じて組織全体の他のチームを関与させます。
必要に応じて、Infrastructure Platforms チームからさらにサポートを得ることができます。 Infrastructure Platforms のリーダーシップには PagerDuty Infrastructure Platforms Escalation を介して連絡できます (詳細はInfrastructure Platforms のチームページ で確認できます)。 Delivery のリーダーシップには PagerDuty を介して連絡できます。Delivery グループページの Release Management Escalation 手順を参照してください。
Admin Notes に関するサポートガイドライン に従い、インシデントへのリンクを含むメモと、ユーザーがブロックされている理由を説明する追加のメモを残してください。以下のいずれかに該当する場合、Incident Manager を関与させるのが最善です:
注意してください: インシデントの重大度が上がる場合 (例えば S3 から S1 へ)、incident.io が EOC、IMOC、CMOC に自動的にページします。
時折、複数のインシデントが同時に発生します。場合によっては、1 人の Incident Manager が複数のインシデントをカバーできます。これが常に可能とは限らず、特に活動が多い高重大度のインシデントが 2 つ同時に発生している場合は難しくなります。
複数のインシデントがあり、追加の Incident Manager のヘルプが必要だと判断したら、以下のアクションを取ってください:
/inc escalate を使って Infrastructure Leadership にエスカレーションします。EOC は週末でもアラートに対応する責任があります。~severity::1 または ~severity::2 でない限り 、インシデントを軽減するための時間を費やすべきではありません。~severity::3 および ~severity::4 のインシデントの軽減は、通常の営業時間 (月曜日から金曜日) に行うことができます。この点について質問があれば、Infrastructure Engineering Manager に連絡してください。
~severity::3 および ~severity::4 が複数回発生して週末の作業が必要な場合、複数のインシデントを単一の severity::2 インシデントに統合すべきです。
重大度の決定に支援が必要な場合、EOC と Incident Manager は /inc escalate を使って Infrastructure Leadership に連絡することを推奨します。
Engineer on Call (EOC) が応答しない場合、ページは Incident Manager (IM) にエスカレーションされます。 このエスカレーションは incident.io を通過するすべてのアラート (低重大度アラートを含む) に対して発生します。 大量のページがあって EOC がページの確認に集中できないときにこれが発生する可能性があります。 これが発生した場合、IM は対応する インシデント告知チャンネル の Slack で、EOC がアシスタンスを必要としているかどうかを確認するために連絡を取るべきです。
例:
@sre-oncall, I just received an escalation. Are you available to look into LINK_TO_INCIDENT_ESCALATION, or do you need some assistance?
EOC が対応できないために応答しない場合、incident.io アプリケーションを使ってインシデントをエスカレーションする必要があります。これにより Infrastructure Engineering リーダーシップにアラートが送られます。
インシデント中に、Incident Responder (EOC)、IMOC、または Communications Manager (CMOC) を関与させる必要がある場合、以下のいずれかの方法を使ってオンコールの担当者をページしてください。これは PagerDuty インシデントまたは incident.io エスカレーションをトリガーし、選択した Impacted Service に基づいて適切な人物にページします。
/inc escalate コマンドを使い、以下のチームに基づいて Oncall team ドロップダウンメニューから正しいチームを選択します。| ページするチーム | サービス名 |
|---|---|
| dotcom EOC | dotcom EOC |
| dotcom IMOC | dotcom IMOC |
| CMOC | dotcom CMOC |
S1 または S2 インシデント中に、1 人以上の顧客と同期的な会話を持つことが有益と判断された場合、その会話のために新しい Zoom ミーティングを利用するべきです。通常、この行動につながる状況は 2 つあります:
オーバーヘッドが多く、影響の軽減作業から注意が逸れるリスクがあるため、このコミュニケーションオプションは慎重に、非常に明確かつ独自のニーズがある場合にのみ使用すべきです。
インシデントに対する顧客との直接のやり取りの呼び出しの実施は、現在の Incident Manager がこれらのステップに従って開始します:
/here A second incident manager is required for a customer interaction call for XXX のようなメッセージで #im-general でその必要性をアナウンスします。インシデントの履歴と現在の状態を把握した後、Engineering Communications Lead は以下のアクションを通じて顧客とのやり取りを開始・管理します:
GitLab であることを示し、また自身の役割 (CSM Engineering Communications Lead) を示すべきですシナリオによっては、インシデントのほとんどの参加者 (EOC、他の開発者などを含む) が直接顧客と作業する必要がある場合があります。この場合、Incident Zoom ではなく、顧客とのやり取り Zoom を使用すべきです。これにより、会話 (およびテキストチャット) を許可しつつ、一次対応者が内部コミュニケーションを Incident Zoom でいつでもすばやく再開できるようにします。
是正措置 (CA) は、インシデントの結果として作成される作業項目です。
インシデントから生じる Issue のみが ~"corrective action" ラベルを受け取るべきです。
それらは同種のインシデントを防ぐか、軽減までの時間を改善するために設計されており、そのためインシデント管理サイクルの一部です。
下流の分析に役立てるため、是正措置はインシデント Issue に関連付けられている必要があります。
Production Engineering プロジェクト における是正措置 Issue は、形式、ラベル、完了に向けたサービスレベル目標 のアプリケーション/モニタリングの一貫性を確保するために、Corrective Action Issue テンプレート を使って作成する必要があります。
~"corrective action" ラベルが付いた Issue には、自動的に ~"infradev" ラベルが付与されます。
これは、開発に対するプロセスに従って 特定の時間枠 で解決されるようにするために行われます。
詳しくは infradev プロセス を参照してください。
| 悪い表現 | より良い表現 |
|---|---|
| 停止を引き起こした問題を修正する | (具体的) ユーザー住所フォーム入力で無効な郵便番号を安全に処理する |
| このシナリオに対するモニタリングを調査する | (実行可能) このサービスが >1% のエラーを返すすべてのケースに対するアラートを追加する |
| エンジニアが、更新前にデータベーススキーマが解析できることを確認するようにする | (制限) スキーマ変更に対する自動 presubmit チェックを追加する |
| 信頼性を向上させるようにアーキテクチャを改善する | (時間制約と具体的) サービスに対する単一障害点が無くなるように、冗長ノードを追加する |
オンコールエンジニア向けに Runbooks が用意されています。プロジェクト README には、上記の各役割のチェックリストへのリンクが含まれています。
GitLab.com の停止時には、runbooks リポジトリのミラーが Ops インスタンス https://ops.gitlab.net/gitlab-com/runbooks で利用可能です。
現在の EOC を確認するには @sre-oncall ハンドルを使ってください
現在の EOC には Slack の @sre-oncall ハンドルを通じて連絡できますが、以下のシナリオに限定してこのハンドルを使用してください。
EOC は、Slack での @sre-oncall ハンドルの使用に対してできるだけ早く応答しますが、状況によってはすぐに対応できない場合があります。緊急で即時の応答が必要な場合は、インシデントの報告 セクションを参照してください。
GitLab のチームメンバーで、GitLab.com に関する可能性のあるインシデントを報告したい場合、以下の手順に従ってインシデントを宣言してください。EOC がオンラインになり、インシデントについてあなたと関与するチャンスを得るまで、オンラインのままでいてください。ご協力ありがとうございます!
GitLab の Slack で /incident または /inc と入力し、プロンプトに従ってインシデント Issue を開きます。
重大度の選択にあたっては、より高い重大度を選ぶ方が安全であり、確信が持てなくても本番問題に対してインシデントを宣言するのは常に良い選択です。
このプロセスを通じて高重大度のバグを報告するのが推奨されるパスです。これにより、必要に応じて適切なエンジニアリングチームを関与させられるようになります。
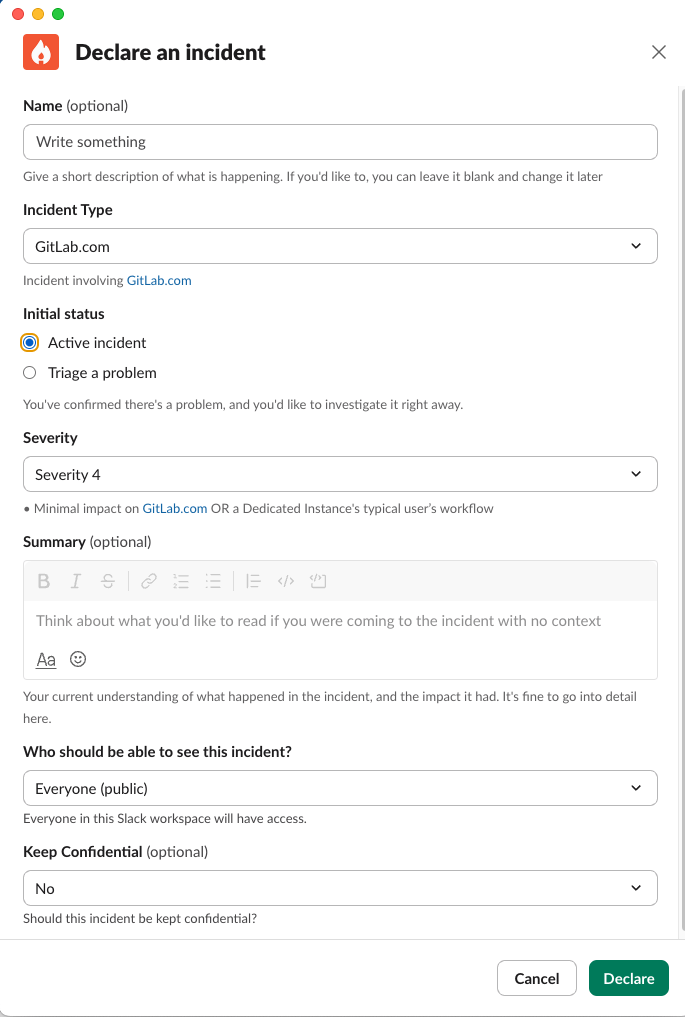 インシデント宣言の Slack ウィンドウ
インシデント宣言の Slack ウィンドウ
| フィールド | 説明 |
|---|---|
| Name | 何が起きているかの短い説明を提供する。空欄のままにして後で変更することもできます |
| Incident Type | 影響を受けるサービスに応じて、適切なインシデントタイプを選択する: GitLab.com、Dedicated、SIRT、または Gameday |
| Initial status | 問題があることを確認し、すぐに調査したい場合は「Active incident」を選択し、初期調査の場合は「Triage a problem」を選択 |
| Severity | 重大度に確信が持てないが、大量の顧客への影響が見られる場合は、S1 または S2 を選択してください。詳細はこちら: Incident Severity。EOC は S1 または S2 でのみ自動的にページされます。 |
| Summary (optional) | インシデントで何が起こったか、どのような影響があったかの現在の理解を提供する。ここで詳細に踏み込むのは問題ありません |
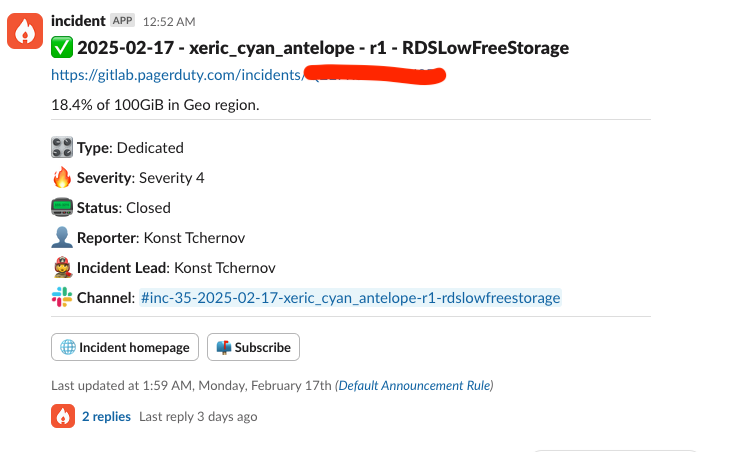
インシデント宣言の結果
GitLab インシデント Issue が開かれるだけでなく、専用のインシデント Slack チャンネルも開かれます。incident.io は対応する インシデント告知チャンネル にこれらすべてのリソースへのリンクを投稿します。インシデント宣言の結果として作成およびリンクされるインシデント Slack チャンネルに参加して、オンコールエンジニアとインシデントを議論してください。S3 または S4 を宣言して EOC の支援が必要な場合は、Slack チャンネルに /inc escalate と入力してエスカレーションしてください。
これは Status.io の用語に対する Service Disruption (Outage)、Partial Service Disruption、Degraded Performance の定義の初回改訂版です。 データは Key Service Metrics Dashboard のグラフに基づいています。
Outage と Degraded Performance のインシデントが発生するのは:
Degraded は、サービスがそのドキュメント化された Apdex SLO を下回るか、ドキュメント化されたエラー比率 SLO を超える状態が継続して 5 分間続いた場合です。Outage (Status = Disruption) は、エラー比率グラフの Outage ラインを超えるエラー率が 5 分間継続した場合です
Degraded または Outage のいずれの場合も、イベントが 5 分を経過したら、Engineer on Call と Incident Manager は、外部コミュニケーションを支援するために CMOC を関与させるべきです。合計時間が 5 分を超えるすべてのインシデント (「blip」インシデントを含む) は、インシデント発生から 1 時間以内にできるだけ迅速に公に伝達されるべきです。
SLO は runbooks/rules に記載されています。
GitLab.com が Degraded または Disrupted であるかどうかをチェックするには、これらのグラフを見ます:
Partial Service Disruption は、GitLab.com のサービスまたはインフラストラクチャの一部のみがインシデントに遭遇している場合です。partial service disruption の例として、GitLab.com は通常通り運用されているが、以下のような場合があります:
高重大度のバグの場合、私たちは依然として インシデントを報告する を通じてインシデントが作成されることを好みます。これにより、イベントと対応を追跡できるインシデント Issue が得られます。
進行中または今後のデプロイメントにある高重大度バグの場合、デプロイメントをブロックする ための手順に従ってください。
インシデントがセキュリティ関連である可能性がある場合、Slack で /security を使って Security Engineer on-call を関与させてください。詳細は Security Engineer On-Call の関与 を参照してください。
情報はインシデントに影響を受けるすべての人にとって資産です。サプライズを最小化し、期待値を設定するためには、情報の流れを適切に管理することが重要です。私たちは、関心のあるステークホルダーに対して、適切に計画できるようにタイムリーに進捗を伝え続けることを目指しています。
この流れは次によって決定されます:
さらに、すべてのステークホルダーのフォーカスを維持するために、情報過多を回避することが必要です。
そのために、以下を用意しています:
私たちは、インシデントが告知される 3 つの専用の Slack チャンネルを持っています
私たちは、status.gitlab.com を更新する status.io を使ってインシデント コミュニケーション を管理しています。status.io のインシデントには state と status があり、CMOC によって更新されます。
status.io でインシデントを作成するには、Slack で /woodhouse incident post-statuspage を使用できます。
場合によっては status.io への投稿をしないことを選択することがあります。投稿/ツイートをスキップする例を以下に示します。これは、セキュリティアップデートをリリースするまで、自己管理インスタンスのセキュリティを保護するのに役立ちます。
state と status の遷移のための定義とルールは以下のとおりです。
| State | 定義 |
|---|---|
| Investigating | インシデントが発見されたばかりで、影響や原因がまだ明確に理解されていません。EOC が関与してから 30 分以上この状態が続く場合、インシデントは Incident Manager On Call にエスカレートされるべきです。 |
| Active | インシデントは進行中であり、まだ軽減されていません。注: 影響が軽減された後にインシデントを Active 状態のままにしておくべきではありません。 |
| Identified | インシデントの原因が特定されたと考えられ、軽減のためのステップが計画され合意されています。 |
| Monitoring | ステップが実行され、メトリクスが監視されてベースラインで動作していることを確認しています。解決につながる特定の軽減の明確な理解と、影響が再発しないという高い確信がある場合、この状態をスキップする方が望ましいです。 |
| Resolved | インシデントの影響が軽減され、ステータスは再び Operational です。解決されたインシデントは レビュー対象としてマーク され、Corrective Actions が定義できます。 |
Status は state とは独立して設定できます。これらが一致しなければならないのは、Issue が次のとおりの場合のみです:
| Status | 定義 |
|---|---|
| Operational | インシデントが開かれる前およびインシデントが解決された後のデフォルトのステータス。すべてのシステムが通常通り運用されています。 |
| Degraded Performance | ユーザーは断続的に影響を受けますが、影響はメトリクスに観察されていないか、広範または systemic であるとは報告されていません。 |
| Partial Service Disruption | ユーザーは私たちの SLO に違反する率で影響を受けています。Incident Manager On Call を関与させる必要があり、解決まで 30 分以上モニタリングが必要です。 |
| Service Disruption | これは Outage です。Incident Manager On Call を関与させる必要があります。 |
| Security Issue | セキュリティ脆弱性が公開と宣言され、セキュリティチームがステータスページへの公開を要請した場合。 |
インシデントの重大度は、組織全体での適切な対応を確保するために、インシデントの開始時に割り当てるべきです。インシデントの重大度は、その時点で 利用可能な情報に基づいて決定すべきです。重大度は、より多くの情報が利用可能になるにつれて調整できますし、すべきです。重大度レベルは、インシデントが持っていた最大影響を反映し、インシデントが軽減または解決された後でもそのレベルにとどまるべきです。Customer Impact または GitLab Impact の基準のいずれかが満たされる場合、その行の Severity が割り当てられるべきです。
Incident Manager と Engineers On-Call は、インシデント重大度を割り当てるためのガイドとして以下の表を使用できます。
| 重大度 | 影響 | GitLab の対応 | 例 |
|---|---|---|---|
| Severity:1 Critical | Customer Impact: ユーザーへの非常に高い影響: ユーザー側の顧客またはビジネス成果が影響を受ける OR GitLab Impact: ビジネスに対する確実なまたは深刻なダメージ | 即時の総力対応 | - 顧客向けサービスがダウン - 確認されたデータ侵害または赤/オレンジデータの曝露 - 顧客データの損失 - GitLab のプラットフォームまたはサプライチェーンに対する複雑度が低く、検証済みのエクスプロイトシナリオ。 - 積極的にエクスプロイトされている、またはパッチ未適用で到達可能でエクスプロイト可能性の telemetry がない Critical RCE - 公開されている (プレス、顧客、研究者による 0-day) Critical 脆弱性 - 外部のアクターが特権の高い GitLab サービスアカウントを制御する |
| Severity:2 High | Customer Impact: ユーザーへの重大な影響: ユーザーの内部運用が中断される OR GitLab Impact: ビジネスに対するありうる、または高まったダメージ | リソースの割り当て、チーム間の調整、定期的なステークホルダー更新 | - 一部の顧客にとって顧客向けサービスが利用できない - コア機能が大きく影響を受けている - アカウント侵害またはインサイダー脅威の動機と知識を必要とする特権昇格シナリオ - エクスプロイトの証拠がある、または高いプレスの注目を集める高重大度脆弱性 - 機密の GitLab システムへの不正アクセスの疑い - GitLab のクラウドインフラストラクチャでのマルウェア検出 |
| Severity:3 Medium | Customer Impact: ユーザーへの中程度の影響: ユーザーの内部運用が妨げられる可能性がある OR GitLab Impact: ビジネスに対するありそうもない、または軽度のダメージ | 通常の運用手順を超えた対応のためにリソースが配分される | - 軽微なパフォーマンス劣化 - 重要でない機能が最適に動作していない - 重要でないシステムにおける一般的マルウェア検出 |
| Severity:4 Low | Customer Impact:: ユーザーへの低い影響: ユーザーの内部運用が変更される可能性がある OR GitLab Impact: ビジネスに対する最小限のダメージ | 標準の手順に従って問題が解決される | - 顧客への不便、回避策あり - 使用可能なパフォーマンス劣化 - 赤/オレンジデータに影響を与えない GitLab セキュリティポリシー違反 |
GitLab の Data Classification Standard には 4 つのデータ分類レベルが定義されています。
Incident Manager は注意を払い、自分の最良の判断を行使すべきです。一般的に、可能ならば issue 全体を confidential としてマークするのではなく、内部ノートを使用することが推奨されます。 わずかな匿名性のあるログデータはデータセキュリティの懸念を示さない可能性がありますが、より大きなログ、クエリ、または他のデータセットには、より制限的なアクセスが必要です。
インシデントライフサイクル全体は incident.io を通じて管理されます。すべての S1 および S2 インシデントにはレビューが必要であり、その他のインシデントも ここで説明 されているようにレビューすることができます。
インシデントは 報告 され、劣化が終わりおそらく再発しない時点で解決されます。
Incident Lead は、インシデントが進行し、最新の状態に保たれることを保証する責任を負います。この役割はインシデントの開始後に意図的に割り当てられます。 Lead は、インシデントのタイプに基づいて選ばれるべきです。例えば:
incident.io の web インターフェースのインシデントで、ページ下部の Activity セクションで「Highlights」を「All Activity」に変更することで、インシデントタイムラインが利用可能です。
インシデントチャンネル内の Slack 投稿に対する :pushpin: (📌) または :star (⭐) の絵文字リアクションを介して、タイムラインに項目を追加できます。:pushpin: でリアクションすると、GitLab インシデント Issue にパブリックコメントが残ります。:star: でリアクションすると、GitLab インシデント Issue に内部コメントが追加されます。Slack メッセージに添付された画像は incident.io のタイムラインに追加されますが、GitLab Issue には投稿されません。
私たちは、もはやインシデントのステータスを説明するために GitLab のラベルのみを使用しません。インシデントの真実の情報源は incident.io です。 ただし、incident.io はインシデントの状態に基づいて一部のラベルを設定するように設定されています。
| ラベル | ワークフロー状態 |
|---|---|
~Incident::Active | ラベル付けされたインシデントがアクティブで進行中であることを示します。初期重大度はオープン時に割り当てられます。インシデントが Active -> Investigating または Active -> Fixing に設定されると設定されます |
~Incident::Mitigated | インシデントが軽減されたことを示します。このラベルは、インシデントステータスが Active -> Monitoring に設定されている場合に適用されます |
~Incident::Resolved | インシデントへの SRE の関与が終了し、アラートをトリガーした状態が解決されたことを示します。インシデントが “Post-incident” または “Closed” のライフサイクル段階にあるときに適用されます。 |
これらのラベルは、メトリクスと追跡のためのメタデータを追加するためのメカニズムとしてインシデント Issue に追加されます。
| ラベル | 目的 |
|---|---|
~incident (自動的に適用) | メトリクスの追跡とインシデント Issue の即時識別に使用されるラベル。 |
~blocks deployments | インシデントがアクティブな場合、デプロイメントのブロッカーになることを示します。このラベルは、incident.io のカスタムフィールド「Blocks Deployments」が「yes」に設定されている場合に設定されます。~severity::1 および ~severity::2 インシデントに自動的に適用されます。 |
~blocks feature-flags | インシデントがアクティブな間、フィーチャーフラグへの変更のブロッカーになることを示します。このラベルは、incident.io のカスタムフィールド「Blocks Deployments」が「yes」に設定されている場合に設定されます。~severity::1 および ~severity::2 インシデントに自動的に適用されます。 |
既存のインシデントの重複であるインシデントが作成された場合、適切なプライマリインシデントとマージするのは EOC 次第です。 インシデントはオープンなインシデントにのみマージできるため、必要に応じてマージするために短時間インシデントを再オープンする必要があります。
incident.io で「Follow-up」が作成されると、GitLab Issue が自動的に作成されます。インシデント Slack チャンネルにリンクを貼ることで、任意の GitLab Issue を Follow-up 項目として追加できます。 Follow-up 項目はデフォルトで incident-follow-ups プロジェクト に作成され、インシデント終了後に適切なプロジェクトに移動すべきです。
graph TD
A(Incident is declared) --> |initial severity assigned| B(Active->Investigating)
A -.-> |If duplicate| Z(Merged)
B --> |"Fix identified"| C(Active->Fixing)
C --> |"Fix deployed"| D(Active->Monitoring)
D --> |"Incident resolved"| E(Resolved)
E --> |"S1 or S2"| F(Post-Incident Review)
E --> |"S3 or S4"| G(Incident Closed)ニアミス、「ニアヒット」、または「ヒヤリハット」は、引き起こす可能性があったが実際にはインシデントを引き起こさなかった計画外のイベントです。
米国では、航空安全報告システムが 1976 年以来、ヒヤリハットの報告を収集しています。ニアミスの観察と他の技術改善により、致命的事故の発生率は約 65 パーセント減少しました。 出典
John Allspaw が述べる ように:
ニアミスはワクチンのようなものです。誰にも、何にも害を与えることなく、将来のより深刻なエラーから会社をより良く防衛するのに役立ちます。
ニアミスが発生した場合、通常のインシデントと同様の方法で扱うべきです。
~Near Miss ラベルを付けます。c955a93f)