スケーラビリティ
スケーラビリティは戦略的なプラクティスです。私たちは以下が必要です:
- スケーラビリティに関連する技術的な意思決定をコンテキストの中で評価するフレームワーク
- スケーラビリティの設計と実装を導くベストプラクティスガイドライン
フレームワーク
フレームワークは問題を管理可能な概念部分に分解することで、問題に対する思考をコンテキスト化し、現在と将来の両方において選択肢を評価できる視点を提供します。設計がより予測可能になり、議論がより焦点を絞られ、意思決定がより正確かつ正しくなります。トレードオフをより見えやすくし、理解・論理的に考えやすくなります。
スイムレーンとスケールキューブは、障害の分離とスケーラビリティを構造的な方法で管理するために広く採用されているモデルです。
スイムレーン
「スイムレーン」または障害分離ゾーンは障害ドメインです。障害ドメインとは、その境界内でいかなる障害も境界内に封じ込められ、境界外のサービスへ障害が伝播しないかつ影響しないサービスのグループです。
スケールキューブ
スケールキューブはサービスをセグメント化し、定義し、プロダクトをスケールするためのモデルです。また、チームがソリューションを設計する際のスケール関連オプションを議論するための共通言語を作ります。
このモデルでは、軸は以下のスケーラビリティ戦略を表します:
X軸: クローニング- バイアスなしのサービスとデータのクローニング(つまり「同種の」ワーカー、データセット全体の複製)
Y軸: コンポーネント化- データの種類および/または実行される作業に基づく作業責任の分離
Z軸: フェデレーション- 顧客またはリクエスターのバイアスに基づく分離
これらは私たちが直感的に慣れ親しんだよく知られた戦略です。フレームワークを正式に採用する力は、これらの戦略をコンテキスト化し、系統的な方法で複数手先を検討できることにあります。以下の図(出典: https://upload.wikimedia.org/wikipedia/commons/5/5f/Scale_Cube.png)はこれらの軸を示しています:
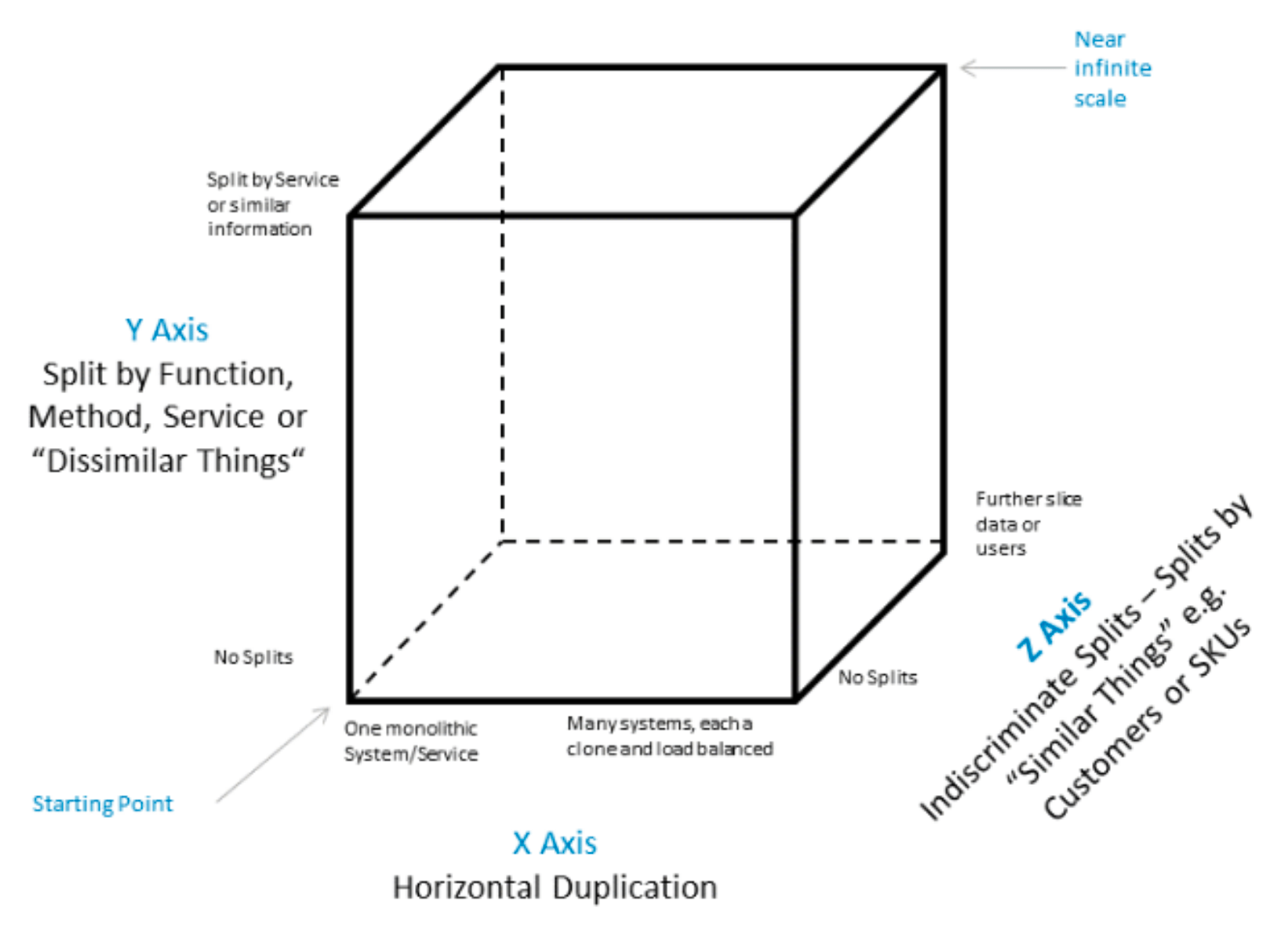
スケールキューブモデルは座標 [0,0,0] から始まり、単一インスタンスが1つのシステム上で実行されます。スケーラビリティはシステムに関連するコンピューティングリソースに完全に依存し、より多くの高速なコンピューティングリソース(CPU、メモリ、ディスク)を追加することでスケールされます。制限要因は利用可能な最大のコンピューティングリソースとなり、コストがすぐに続きます。
スケールキューブはすべてのイテレーションでのすべてのコンポーネントに適用できます。
例: Postgres の現状
GitLab.com は現在 [1,1,0] で稼働しています:
X軸: データベースは N 個の完全にレプリケートされたインスタンス(複数の RO セカンダリを持つプライマリ RW)で構成されており、それぞれがデータセット全体の複製を含んでいます。この設定は、より多くのハードウェアを追加することで RW ワークロードに対して垂直スケール、より多くのレプリカを追加することで RO ワークロードに対して水平スケール(クエリキャパシティの増加)できます。2つの制限要因が役割を果たします:- RW キャパシティはハードウェアキャパシティに直接比例する(垂直スケーリング)
- RO キャパシティは最終的にレプリケーションラグによって課せられる制限に達する(CAP が役割を果たす)
Y軸: サービスを作成せずに、すでに一部のデータ(差分)をコンポーネント化によってデータベースから移行しています
最近の分析によると、データベースキャパシティは12ヶ月の範囲を十分に超えていることが示されています(この見積もりは毎週更新されます)。スケーラビリティオプションを検討する中で、次のイテレーションが [1,2,0] を実装するか [1,1,1] を実装するかという問題があります。現在の提案は本質的に後者の戦略を支持していますが、まったく異なる方向を選択する場合もあります。
スケーラビリティのベストプラクティス
このセクションでは、経験(私たちのものと他者のもの)を通じて長年にわたって集められたスケーラビリティのベストプラクティスを収集しています。これらは認知的なレベルを整えながら、構造的な方法でこれらの問題に取り組むために適用するガイドラインであり、ルールではありません。
[AMF] 常にモノリスファースト
スケーラビリティの第一のルールは… やらないことです。
これはよく知られたテーマのバリエーションです: まず機能性、早すぎる最適化を避ける。常にモノリスから始め、そこから抽出するのは正当な理由がある場合のみにしてください。「正当な理由」は常にデータ駆動の意思決定(KPI 経由)です。そうすることで、それ自体が重大な問題(管理不可能な依存関係、孤立または放置されたサービスなど)であるアプリケーション内の「サービス」の抑制されない増殖を避けることができます。ガードレールとして、アプリケーション内で許可される「サービス」数に厳格な制限を設定でき、その制限を引き上げることは組織的に困難であるべきです。重要なのは、サービスが最適化されておらず、製品の残りの部分と同様にパフォーマンスが高くない可能性があることを含意しています。ユーザーが情報に基づいた選択ができるよう、公開されたエラーバジェットとパフォーマンス目標を持ちながらも信頼性を保つべきです。
ただし、スケーラビリティは戦略的なプラクティスであることを覚えておいてください。スケールキューブを念頭に置いてください: スケーラビリティフレームワーク内で、新しいエンティティによって作られる関係を注意深く検討してください。将来エンティティをコンポーネント化またはフェデレートする必要が生じた場合、何が起こるでしょうか?
[SSI] スケーラビリティイテレーションのシリアル化
2つの軸を同時にスケールしようとしないでください。
[CBF] フェデレーションの前にコンポーネント化。ほとんどの場合
コンポーネント化はシステムを論理的で相互接続されたコンポーネントに分解します。フェデレーションは [TODO: 定義] を指します。
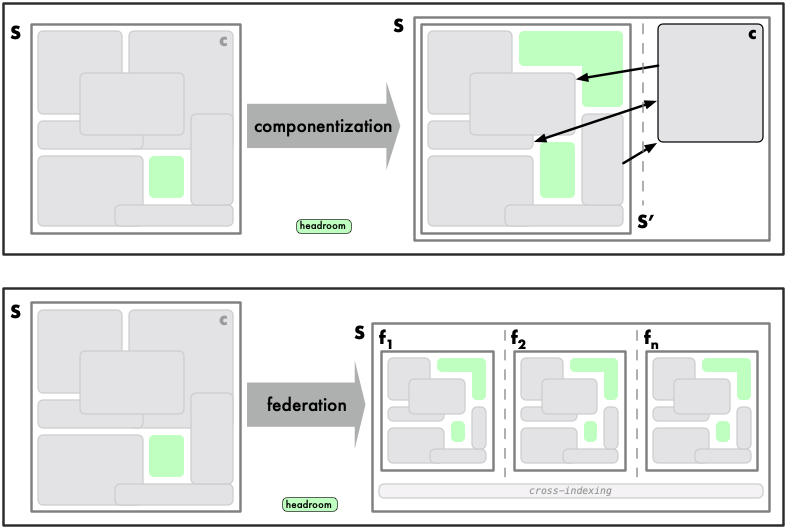
コンポーネント化は、システムから抽出された解放されたリソース全体でヘッドルームを作ることでスケールを提供します。また、他のコンポーネントから比較的独立してスケールでき、個々のコンポーネントを必要に応じてローカルに最適化・スケールできます: 一般的に、ダウンストリーム依存関係を圧倒しないよう適切にスケールすることを心配するだけで済みます。極端な場合には、まったく異なるクラスのデータストアを選択することもあります(例えば、コメントをリレーショナルデータベースよりもドキュメントデータベースに保存する方が効果的であると判断する場合があります。すでに差分を Postgres からオブジェクトストレージに移行することでこれを実施しています)。
コンポーネント化は無料ではありません:
- データは別のサブシステム、つまり別のランタイムスコープから来るため、必要なデータを組み合わせるためのデータマッパーとデータコンポーザーが必要です。アプリケーションは、以前にデータストアに委任されていたこれらの責任の一部を引き受けなければなりません。
- 内部レイテンシが増加するため、キャッシングが方程式に入ります。クロスインデックスが必要になる場合があります
- 障害モードがより分散します: 完全なコンポーネント障害は検出が簡単かもしれませんが、結果が返される場合、その結果が予想される完全な結果セットであるかどうかを確認できる必要があります。または、部分的な結果が返されている場合に理解できる必要があります。
コンポーネント化は効率的なイテレーションに(従うべき)できます。コンポーネント化はリポジトリ(すでにある程度そこにあります: 実際にはハッシュパスによってフェデレートされた Gitaly)、Issue、コメント、パイプラインなどの論理コンポーネントに GitLab を分解することを伴います。許可されるコンポーネント数に合理的な上限を設ける必要があります(AMF)。フェデレーションは垂直軸(例えばテナント)を伴います。
コンポーネント化の前にフェデレートすることの問題の一つは、長期的にはフェデレートされたメンバーを垂直にスケールしようとすることになるということです。場合によってはこれがうまく機能することもありますが、すべてのフェデレートされたメンバーをコンポーネント化する必要がある時点に達する可能性があり、プロセスに複雑さを加える操作になります。
ほとんどの場合
ただし、特に顧客価値を生み出すか将来のイテレーションの基盤を築ける低影響の MVC を提供できる場合など、先にフェデレートすることが理にかなう場合があります。しかし、これらはスコープが最も浅いケース(MVF を参照)に限定されるべきです。
[MVF] 最小可変深度フェデレーション
私たちはイテレーションを効率的に行うため、可能な最小スコープで操作しようとします: 任意のイテレーションでは、スタックの影響を受けるレイヤー数とそのレイヤー間の距離の観点から測定して、最も浅いフェデレーションのみを実装してください。非常に実際的な問題として、フェデレーションは単一のイテレーションでスタック全体を切断することはありません: 理にかなう場所、時間、方法で使用してください。ただし、スコープを最小化してください。可変深度により、適用を選択的にすることができます(これはボーリングソリューションと MVC に沿っています)。
例
フェデレーションは、特定のタイプの顧客に対して GitLab.com への別の DNS エンドポイントを持つのと同じくらいシンプルかもしれません。タイプは任意の数の変数で定義されます: ビジネスエンティティ(例: 会社 Acme)、ジオロケーション(eu.gitlab.com、gitlab.com.de、または gitlab.cn)。その背後にあるものは完全に私たち次第です。
[NFR] 関係のフェデレート禁止
関係をフェデレートしないでください。関係はときにエンティティの形を取ることがありますが、真のエンティティではありません。例えば、名前空間は関係エンティティです: その唯一の機能は関係ブリッジとして機能することです。プロジェクト、ユーザー、Issue などの真のエンティティと比較してください。
[NFE] エンティティのフェデレート禁止
エンティティの属性を主キーとして使用してはならないように、内在的なスイムレーンを作るためにエンティティをフェデレートしてはなりません。つまり、スイムレーン識別子としてエンティティの属性識別子を使用しないでください。複数のエンティティがスイムレーンを共有できるエンティティの属性を使用してフェデレートしてください。極端な場合、N = 1 ですが、エンティティの識別子をスイムレーンの識別子にすることで行うのではありません。
[FCC] フェデレーションは顧客の選択
顧客、特に既存の顧客にフェデレーションを受け入れさせるべきではありません。特に、顧客に最も近い傾向があるエッジレイヤーでのフェデレーション(フロントドアなど)は非常に破壊的になる可能性があります。人々は設定やスクリプトに名前をハードコードする傾向があります。これは私たちにとって非常に当てはまります。何百万人もの人々が GitLab.com を指す Git 設定でリポジトリをクローンしています。
[CTF] フェデレーションによるコンプライアンス
フェデレーションは顧客またはリクエスターのバイアスに基づいているため、特定のフィーチャーを望む顧客に対してそれらの境界に沿ってフィーチャーの有効化が可能になります(地理的にローカライズされたデータ)。規制コンプライアンスはフェデレーションを通じて有効化されます。
[CTL] 時間的局所性によるコンポーネント化
時には、特定のコンポーネントを時間的に分割することが理にかなうことがあります。パイプラインと関連データは、例えば潜在的な時間分割の一例です。おそらく、すべての設定とスケジュールを高速なリレーショナルデータベースに保持しますが、6ヶ月以上前のデータを別の、おそらくより遅いデータベースに移動します。
ワークフロー
パフォーマンス指標
パフォーマンス指標はスケーラビリティに関連する計測であり、コンポーネントとアプリケーションのスケーラビリティの限界を理解できるようにします。現在、Scalability チームによって取り組まれています:
- https://docs.google.com/document/d/1lZ7RKtv7yCkV7MVx-7UfZZMvEB9lzLrrFDUw0oVFxXA/edit#heading=h.ibm29qjhrqeb
- https://gitlab.com/gitlab-com/gl-infra/scalability/-/issues/382
パフォーマンス指標はスケーラビリティ作業の優先順位付けを可能にします。
目標の明示
スケーラビリティ作業に着手する前に、スケーラビリティ目標を明示することが重要です。詳細な仕様である必要はありません: シンプルさが重要であり、目標は時間をかけて洗練させることができます。(注: PI は重要です)ほとんどの場合、特定のスケーラビリティイテレーションの正確な効果を正確に予測することはできません。したがって、見積もりは許容されます(ただし計算を示してください)。
ソリューションのスコープ
目標を満たすソリューションの候補はどれか?スケールキューブとベストプラクティスを使用してスコープを設定し(それらを評価し)、将来のステップがどのようになるかを評価してください(ステップ関数)。アーキテクチャワークフローを通じて関与してください。
c955a93f)
{kind=link}