可用性
あなたのシステムは必ず障害が発生します。可用性とは、障害が発生した際の影響を最小化するプラクティスです。このページでは以下を提供します:
- 信頼性の高いシステムを構築・運用するためのベストプラクティス
- インシデント時にトレードオフを判断するためのフレームワーク
可用性の柱
システムが圧力下に置かれているとき、私たちは何を守るべきかに集中します。この4つの柱は相互依存しており、一方を犠牲にするのではなく、バランスを調整します。
| 柱 | フォーカス | 重要な理由 |
|---|---|---|
| データ整合性 | データの保護 | データが破損している場合、可用性は無意味です。フェイルオーバー中でもデータは正確で一貫性を保つ必要があります。 |
| システム回復力 | 安定性とスケール | トラフィックの急増、ハードウェア障害などのショックを全面的な崩壊なく吸収する能力。セルフヒーリングと負荷削減を含みます。 |
| エクスペリエンス検証 | 顧客体験 | 「システムは動いているか?」だけでなく「フィーチャーは機能的でパフォーマンスは十分か?」 |
| 制御された変更 | 進化の安全性 | ほとんどの停止は変更によって引き起こされます。安全なロールアウト、フィーチャーフラグ、高速ロールバックにより変更が危機になることを防ぎます。 |
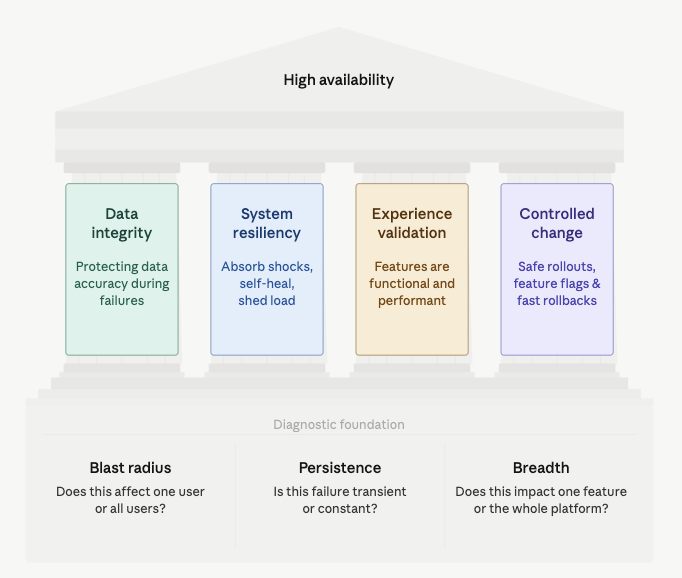
深刻度の測定
インシデント中にこれらの柱がどれだけの重みを負担しなければならないかを定義する3つの質問があります:
- ブラストラジアス(範囲): これは1人のユーザーに影響するか、それともすべてのユーザーに影響するか?
- 持続性(継続時間): この障害は一時的で自己修復するか、それとも永続的で手動介入が必要か?
- 範囲(広がり): これは1つのフィーチャーに影響するか、それともプラットフォーム全体に影響するか?
可用性のベストプラクティス
このセクションでは、経験を通じて長年にわたって集められた可用性のベストプラクティスを収集しています。これらは信頼性の高いシステムを体系的な方法で構築・運用するために適用するガイドラインであり、ルールではありません。
### 障害は避けられない{.availability-practice}
あなたのシステムは障害が発生します。100%の可用性を目標とするのは決して正しくありません。
なぜ
すべてのシステムには障害モードがあります。ハードウェアは劣化し、ソフトウェアにはバグがあり、ネットワークは分断され、クラウドプロバイダーには停止が発生します。これらの多くはあなたのコントロール外です。この現実を受け入れ、それを前提に設計することが利用可能なシステムを構築する基盤です。100%の可用性目標を設定することは、無限のコストとゼロの変更を意味するため、決して正しくありません。どちらも達成可能でも望ましくもありません。
詳細については SRE ブック: リスクの受け入れを参照してください。
どのように
サービスの重要度を反映したエラーバジェットを定義してください。そのエラーバジェットを使用して、変更のペースと障害コストに関する情報に基づいた意思決定を行ってください。オペレーターとユーザーの両方が情報に基づいた選択ができるよう、システムに公開された可用性目標があることを確認してください。
例
GitLab.com は99.95%の可用性を目標としており、月あたり約22分のダウンタイムが許容されます。このバジェットにより、デプロイメント、メンテナンス、そして予期せぬ障害のための空間が生まれ、軽微な中断をすべて危機として扱わなくても済みます。Gitaly や CI ランナーなどのサービスは、それぞれGitLab.com SaaS 可用性ダッシュボードでトラッキングされた独自のエラーバジェットを持っています。
### インタラクティブトラフィックを優先する{.availability-practice}
システムが圧力下にあるとき、ユーザーが積極的に待っているトラフィックを保護してください。
なぜ
インタラクティブトラフィックはリアルタイムでユーザー体験に直接影響します。ページの読み込みや Git のプッシュが完了するのを待っているユーザーは、劣化の影響を即座に感じます。バックグラウンド処理、Webhook、非同期ジョブはユーザーに気づかれることなく遅延を許容できます。
どのように
インタラクティブトラフィックとバックグラウンドトラフィックを区別するサービス品質メカニズムを実装してください。飽和が発生したとき、まずバックグラウンドの作業を削減してください。可能な限り別のリソースプールを使用して、バックグラウンド処理がインタラクティブなリクエストをリソース枯渇させないようにしてください。
例
GitLab.com では、Sidekiq ジョブは緊急度によって分類されています。データベース負荷が高い期間中、プロジェクトエクスポートやパイプラインアーティファクトの有効期限切れなどの低優先度バックグラウンドジョブを延期しながら、Rails アプリケーションへのウェブリクエストと API 呼び出しは引き続き処理されます。別の Sidekiq シャード設定により、重要でないキューをスロットルまたは一時停止して、ユーザー向けエクスペリエンスへの影響を最小化できます。
### 優雅な障害のための設計{.availability-practice}
コンポーネントが障害を起こした場合、システムは崩壊するのではなく、劣化すべきです。
なぜ
ハードな障害はカスケードします。1つの依存関係がダウンするとアプリケーション全体が落ちる場合、チェーンの中で最も信頼性の低いコンポーネントに可用性を依存させていることになります。優雅な障害はブラストラジアスを小さく保ち、まだ機能しているシステムの部分を保護します。
どのように
各依存関係が利用不可能になった場合に何が起こるかを考慮してください。フォールバックパスを設計してください: キャッシュされたデータを提供する、重要でないフィーチャーを無効にする、または部分的な結果を返す。障害モードをアーキテクチャで明示的にして、テストや分析ができるようにしてください。
例
GitLab の高度な検索をバックアップする Elasticsearch クラスターが利用不可能になった場合、検索結果はエラーを返すのではなく、基本的なデータベースベースの検索にフォールバックできます。同様に、外部オブジェクトストレージプロバイダーがレイテンシを経験した場合、アプリケーションはページ全体の読み込みをタイムアウトさせるのではなく、添付ファイルのプレースホルダーコンテンツを表示することで劣化できます。
### レイテンシは障害の一部{.availability-practice}
ユーザーの観点から、遅いシステムは壊れたシステムです。
なぜ
ユーザーは失敗したリクエストと諦めるほど時間がかかるリクエストを区別しません。過度のレイテンシはバックプレッシャーも生み出します: 接続が積み上がり、ワーカープールが飽和し、遅さから始まったものが完全な停止になります。レイテンシはしばしば差し迫った障害の最初の症状です。
どのように
可用性目標と並行してレイテンシ目標を設定してください。p50、p95、p99 のレイテンシを監視し、持続的なレイテンシの増加を可用性インシデントとして扱ってください。Apdex スコアを使用してレスポンス時間に対するユーザー満足度を定量化してください: Apdex はリクエストが許容可能な閾値内で完了しているかどうかを測定する標準化された方法を提供し、Apdex スコアの低下は可用性劣化の早期警告です。タイムアウトとサーキットブレーカーを使用して、遅い依存関係がリソースを無制限に消費しないようにしてください。
例
GitLab.com では、30ミリ秒の代わりに30秒かかる遅い Postgres クエリは、1人のユーザーにのみ影響するわけではありません。それはその期間中データベース接続と Puma ワーカースレッドを保持し、他のすべてのリクエストのキャパシティを削減します。
Sidekiq のデータベースクエリや Sidekiq ジョブ自体など多くのケースでは、ヒストグラムバケットのカーディナリティが高すぎてコストがかかりすぎるため、従来のパーセンタイルレイテンシ(p50、p95、p99)の監視は実用的ではありません。代わりに、リクエストを許容可能、許容可能、不良として分類し、それを Apdex スコアに変換することで、オブザーバビリティコストをかけずにユーザー向けレイテンシの健全性についての明確なシグナルを得ます。
### 冗長性のための設計{.availability-practice}
単一のコンポーネントが単一障害点であってはなりません。
なぜ
ハードウェアは故障し、ソフトウェアはクラッシュし、アベイラビリティゾーン全体がオフラインになります。システムがいずれかのコンポーネントの単一インスタンスに依存している場合、そのコンポーネントの障害がシステムの障害になります。冗長性は、ユーザーへの影響なしに個別の障害を乗り越える能力を提供します。
どのように
ステートレスサービスには、ロードバランサーの背後で複数のインスタンスを実行し、障害ドメイン(ゾーンまたはリージョン)全体に分散させてください。ステートフルシステムには、自動フェイルオーバーを備えたレプリケーションを使用してください。冗長コンポーネントが真に独立していることを確認してください: 同時に障害が発生する可能性がある基礎インフラを共有すべきではありません。
例
GitLab.com は複数の GCP ゾーンにまたがってステートレスアプリケーションワークロードを実行しているため、単一ゾーンの損失は停止を引き起こしません。Postgres は Patroni による自動フェイルオーバーを備えた同期レプリケーションを使用しています。Redis Cluster はキャッシュとセッションストレージの冗長性を提供します。しかし、Gitaly は完全な冗長性が欠けている部分です: リポジトリデータはシームレスなフェイルオーバーを可能にする方法でまだレプリケートされておらず、Gitaly ノードの障害は手動介入を必要とする既知の可用性リスクとなっています。
### ネットワークは難しい{.availability-practice}
ネットワーク障害は最も一般的で予測が難しい停止の原因の1つです。
なぜ
常に DNS の問題です(まあ、常にではありませんが、よくあります)。またはパケットロス、非対称ルーティング、設定ミスのファイアウォールルール、または証明書の期限切れです。ネットワークは分散システムの結合組織であり、その障害モードは多様でしばしば微妙です。ネットワークコンポーネント間の距離はハードウェアを追加しても排除できないレイテンシをもたらします。
どのように
ネットワークは信頼できないものと仮定してください。バックオフとジッターを使用したリトライのための設計。クリティカルパスでのネットワークホップ数を最小化してください。ネットワーク状態が悪化したときに検出できるよう、アプリケーション層でサービス間レイテンシを計測してください。ネットワークトポロジーを可能な限りシンプルに保ってください。
例
GitLab.com は GCP インフラに到達する前に、ほとんどのトラフィックを Cloudflare 経由でルーティングしています。DNS レコード、Cloudflare ルール、GCP ロードバランサーのヘルスチェックなど、どのレイヤーでも設定ミスがサイト全体をダウンさせる可能性があります。証明書の更新と DNS の TTL は、これらのクリティカルパスでのヒューマンエラーの可能性を減らすために監視・自動化されています。
### 一方向ドアの障害を避ける{.availability-practice}
不可逆なアクションには最高レベルの精査が必要です。
なぜ
ロールバックできる障害は不便です。ロールバックできない障害は危機です。データの削除、カラムを削除するスキーマ移行、元に戻すことができない設定変更はすべて一方向のドアです。これらの障害は回復に不釣り合いに高いコストがかかり、しばしばデータ損失や長期的な停止につながります。
どのように
可能な限りソフト削除を使用してください。破壊的な操作の前に確認チェックと遅延を追加してください。データベース移行が可逆であるか、テストされたロールバックパスを持つことを確認してください。データを永続的に変更するあらゆる操作を極端に慎重に扱ってください。
例
GitLab.com でのデータベース移行の標準的なプラクティスは、コードから削除されたのと同じリリースでカラムを削除しないようにすること、つまり常にロールバックが可能であることを確保することです。行数が比較的少ないまたはデータが最小限のテーブルのカラムについては、データを全く削除しないことを検討してください: クリーンなスキーマのコストはリスクに見合わない可能性があります。Rails の ignore_columns を使用すると、実際の削除をメジャーアップグレード、または無期限に延期しながら、コード上でカラムを放棄できます。プロジェクトやグループの削除などの破壊的な操作は慎重にゲートされ検証される必要があります。移行やデータ変更を逆転できない場合、障害の可能性を考慮した明確なロールバック計画とともに追加のレビューが必要です。
### 共有リソースはコストがかかる{.availability-practice}
共有リソースは独立したシステム間の結合を生み出します。
なぜ
共有リソースはすべてあなたのものではありません。すべての共有データベース接続、CPU サイクル、ネットワークソケットは誰かのコストになります。あなた、別のチームのサービス、またはあなたの顧客です。共有リソースが飽和すると、すべてのコンシューマーが同時に影響を受けます。リソース消費を理解することは、他の誰かの停止の原因にならないための第一歩です。
どのように
共有リソースの消費を測定・監視してください。1つのコンシューマーがプールを枯渇させないよう制限とクォータを設定してください。可能な限り、クリティカルなワークロードを専用リソースに分離してください。良いご近所さんになってください。
例
GitLab.com のメイン Postgres データベースは、アプリケーションのすべてのフィーチャーが消費する共有リソースです。1つのフィーチャーからの単一の最適化されていないクエリがデータベース接続を飽和させ、他のすべてのフィーチャーに影響を与える可能性があります。これが、サービスごとの接続制限を設け、接続プーリングに PgBouncer を使用し、過剰な使用を特定して対処するためにフィーチャーごとのデータベースリソース消費をトラッキングする理由です。
### 顧客からの予期しない行動を想定する{.availability-practice}
顧客はあなたが予期しなかった方法でシステムを使用します。
なぜ
誰かに足を撃つ銃を手渡せば、彼らはそれを使います。顧客は数百万のファイルを持つリポジトリ、数千のジョブを持つパイプライン、毎秒ポーリングする API 統合を作成します。これは悪意のあるものではなく、柔軟なツールを構築することの自然な結果です。システムが予期しない使用パターンを処理できない場合、それはシステムの問題であり、顧客の問題ではありません。
どのように
すべての入力フィールド、API エンドポイント、ユーザー設定可能なパラメーターは最終的に極端な値を受け取ると仮定してください。レートリミット、キーセットページネーション、リソースキャップを後から追加するのではなく、初期設計の一部として実装してください。現実的でアドバーサリアルなワークロードでテストしてください。
例
GitLab.com では、ある顧客の CI パイプライン設定が数千の子パイプラインを生成し、重大な Sidekiq キューの飽和を引き起こしたことがあります。設定は API に従って完全に有効でした。システムは単にそのスケールのパイプラインファンアウトのために設計されていませんでした。パイプライン制限の追加とキューの分離改善が、プラットフォームを保護するために必要でした。
### レートリミットは両刃の剣{.availability-practice}
レートリミットはプラットフォームを保護しますが、遅くに有効化するとすべての人に痛みをもたらします。
なぜ
レートリミットは、悪用や暴走したワークロードから共有インフラを保護するために不可欠です。しかし、顧客がすでにそれらの制限を超える統合やワークフローを構築した後にレートリミットを導入すると、悪いエクスペリエンスが生まれます: 顧客は数ヶ月または数年間行ってきたことを突然ブロックされます。レートリミットの有効化が遅れるほど、より破壊的になります。
どのように
顧客が無制限アクセスへの依存関係を発展させる前に、保守的な閾値で早期にレートリミットを有効化してください。制限を引き上げることは、制限を導入することよりもはるかに容易です。既存の機能にレートリミットを追加する必要がある場合は、積極的に伝達し、施行が始まる前に顧客が自分の使用状況を理解するためのツールを提供してください。
例
GitLab.com では、レートリミットなしで立ち上げられた API エンドポイントは、制限が最終的に追加されたとき、慎重で段階的なロールアウトが必要でした。正当な大量統合を持つ顧客が影響を受け、例外、コミュニケーション、緩和のためのエンジニアリング作業が必要でした。対照的に、最初からレートリミットと共に出荷される新しいフィーチャーはほとんど不満を生みません。顧客は最初からそれらの制約内で統合を設計するためです。
### 悪用から守る{.availability-practice}
悪用は定数です。システムはそれに対して回復力を持つ必要があります。
なぜ
悪意のあるトラフィックに対しては、正当な顧客の行動よりもさらにコントロールできません。攻撃者、スクレイパー、仮想通貨マイナーは保護されていないサーフェスを見つけて悪用します。システムに防御が整っていない場合、悪用は正当なユーザーのためのリソースを消費します。
どのように
複数のレイヤーでレートリミットを実装してください。Web アプリケーションファイアウォールとボット検出を使用してください。コードのデプロイメントを待たずに迅速に有効化できる悪用緩和策を設計してください。1つのフィーチャーの悪用が無関係なフィーチャーの可用性を低下させないことを確保してください。
例
GitLab.com は DDoS 保護のために Cloudflare を使用し、アプリケーション層のレートリミットも設けています。内部的に、Rack::Attack は Rails アプリケーションでユーザーごとおよび IP ごとのレートリミットを提供します。仮想通貨マイニングのための無料枠 CI 分の使用など、新しい悪用パターンが出現したとき、対応は迅速でなければなりません: コードリリースを待つのではなく、運用ツールを通じてレートリミットを調整し悪意のあるアカウントをブロックします。
### カオスエンジニアリングとテスト{.availability-practice}
障害モードをテストしていない限り、システムの可用性に自信を持つことはできません。
なぜ
システムがどのように障害を起こすかについての仮定はしばしば間違っています。依存関係が利用不可能なとき、ノードが失われたとき、またはトラフィックが急増したときにシステムがどのように動作するかを知る唯一の方法はテストすることです。本番環境に似た環境でのテストは、ユニットテストとコードレビューでは明らかにできない障害モードを明らかにします。
どのように
現実的な障害シナリオをシミュレートするゲームデーを実施してください。ステージングで飽和ポイントを理解するためのロードテストを行ってください。ランブック、アラート、インシデント対応プロセスが期待通りに機能することを確認するための運用テストを実施してください。これを一度限りのイベントではなく、定期的なプラクティスにしてください。
例
GitLab.com インフラチームは、システムの動作を観察し、アラートを検証するために Redis、Postgres レプリカ、Gitaly ノードなどのコンポーネントを意図的に劣化させる定期的なゲームデーを実施しています。現実的なトラフィックプロファイルでステージングでのロードテストにより、接続プールの枯渇など、発見されなければ本番停止を引き起こしていたであろうボトルネックが特定されています。
### ロールアウトは問題{.availability-practice}
本番インシデントの大きな割合は変更によって引き起こされます。
なぜ
デプロイメント、設定変更、フィーチャーフラグのトグル、インフラ変更はインシデントの最も一般的なトリガーです。これは変更をやめる理由ではありません。慎重に変更を行う理由です。変更は飽和と予測できない方法で相互作用します: 1つのボトルネックを取り除くと次のボトルネックが現れることがよくあります。
どのように
変更を段階的にロールアウトしてください。フィーチャーフラグとカナリアデプロイメントを使用してブラストラジアスを制限してください。すべてのロールアウト中とその後に主要なメトリクスを監視してください。すべての変更がすぐにロールバックできることを確認してください。変更管理を管理上の負担ではなく、可用性のプラクティスとして扱ってください。
例
GitLab.com はカナリア、ステージング、そして本番へと段階的に変更をロールアウトする段階的デプロイメントパイプラインを使用しています。フィーチャーフラグにより、完全なロールアウトの前に少数のユーザーに対して新機能を有効化できます。デプロイメントがエラーレートの増加を引き起こした場合、デプロイメントパイプラインを停止し、数分以内に変更を元に戻すことができます。
### ペットではなく牛{.availability-practice}
既知で再現可能なデプロイメントアーキテクチャは可用性の問題を防ぎます。
なぜ
インフラが手作りでユニークな場合、すべての障害は新しいイベントであり、固有の調査と修復が必要です。インフラが再現可能で使い捨て可能な場合、修復するのではなく交換するため回復が速くなります。ペットは単一障害点を作りますが、牛は回復力を生み出します。
どのように
インフラのプロビジョニングを自動化してください。可能な限りイミュータブルなデプロイメントを使用してください。どの単一のノード、コンテナ、またはインスタンスも、影響なしに破壊・再作成できることを確認してください。エフェメラルなコンピューティングリソースにステートを保存しないでください。
例
GitLab.com はアプリケーションワークロードを Kubernetes 上で実行し、ポッドはエフェメラルで、ヘルスチェックに失敗すると自動的に交換されます。インフラは Terraform でプロビジョニングされ、環境を再現可能に作成できます。このアプローチにより、障害が発生したノードは危機ではなく、プラットフォームによって自動的に処理されるルーティンなイベントとなります。
### システムが機能していることを証明する{.availability-practice}
システムが利用可能であることを知るためには、エンドツーエンドで機能していることを証明するテレメトリが必要です。
なぜ
測定できないものは改善できず、見えないものは守れません。オブザーバビリティはシステムがどのように壊れるかを知ることではありません。機能していることを証明できることです。顧客体験を反映するテレメトリは、可用性の測定とアラートの基盤です。
どのように
顧客の観点からエンドツーエンドの成功を測定するためにシステムを計測してください。壊れているときに発火するシグナルだけでなく、システムが機能していることを確認するシグナルに焦点を当ててください。そこから、原因ではなく症状に基づいたアラートを設定してください。SLI と SLO を使用して、サービスにとって「機能している」とは何を意味するかを定義・トラッキングしてください。
例
GitLab.com は、本番環境に対して実際の Git 操作(クローン、プッシュ、プル)と Web インタラクションを継続的に実行する合成監視を使用して、コアユーザーエクスペリエンスが機能していることを継続的に証明しています。Web リクエストの Apdex スコアや API エンドポイントのエラー比率などのサービスレベルインジケーターは、アラートとインシデント対応を促進する顧客中心の可用性ビューを提供します。
c955a93f)