Siphon
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| ongoing | ahegyi | andrewn
abrandl | dennis | devops monitor | 2024-11-20 |
概要
このドキュメントは、PostgreSQL 論理レプリケーションストリームからキューイングシステムへシリアル化された CDC(change data capture)データを配信する Siphon の MVP バージョンのアーキテクチャを説明します。キューイングシステムから、コンシューマーがデータを処理して他のデータベースシステム(ClickHouse、Snowflake など)に取り込むことができます。
プロジェクトの目標
- PostgreSQL データベースからデータを取り出す標準的な方法を提供することで、既存のデータ同期ツールを置き換える。
- pub-sub を通じて PostgreSQL データベースからのデータ変更イベントを非同期でストリーミングする。
- 既存のテーブルから一貫した方法でデータを抽出する可能性。
- GitLab.com、Dedicated、Cloud-Native GitLab Charts(および Omnibus)を通じたセルフマネージドで、Kubernetes 環境にデプロイされることを意図している。
- このツールは Rails アプリケーションに変更を加えるアプリケーション開発者にとってほぼ透明です。
- PostgreSQL クラスターの可用性に対してゼロまたは最小限の影響。
- PostgreSQL バージョン 14 以上のセルフマネージド Postgres クラスター(Patroni あり・なし)をサポートする必要があります。さらに、Amazon RDS および Google CloudSQL を通じたクラウドマネージド Postgres クラスターをサポートし、これらのマネージドサービスで利用可能な機能と拡張機能のみを使用する必要があります。
プロジェクトの非目標
- システムは PostgreSQL レプリケーションのみをサポートします。Redis や Git の変更などの他のタイプのデータ変更は Siphon アプリケーションを通じません。そのような変更のキューイングシステムは同じかもしれません。
- システムはアプリケーションがカスタムイベントを発行することを許可しません。すべてのイベントは論理レプリケーションイベントまたは初期データスナップショットプロセスからの行データである Siphon プロデューサーから発生します。データの起源は常に PostgreSQL データベースです。
主要コンポーネント
Siphon の主要コンポーネントは以下の通りです。
- プロデューサーアプリケーション(シングルバイナリアプリケーション):
- PostgreSQL パブリケーションを管理する。
- レプリケーションスロットからデータを読み取る。
- 既存のテーブルからの初期データスナップショットを調整する。
- CDC イベントをシリアル化してエンキューする。
- プラグイン可能なキューイング/PubSub システム(TBD、NATS を評価中)
- 永続的なデータストア。
- 少なくとも 1 回の配信保証を提供する(完全に 1 回の配信保証が必要かどうかを検証する必要あり)
- 大きなテーブル(2〜3 テラバイト)の保存/バッファリングが可能。
- 異なるキューイングシステムのサポートの可能性を持つプラグイン可能な設定。
- コンシューマーアプリケーション(シングルバイナリアプリケーション):
- ターゲットデータベースシステムに接続する。
- キューから CDC イベントを読み取る。
- イベントを再フォーマットしてターゲットデータベースシステムにデータをプッシュする。
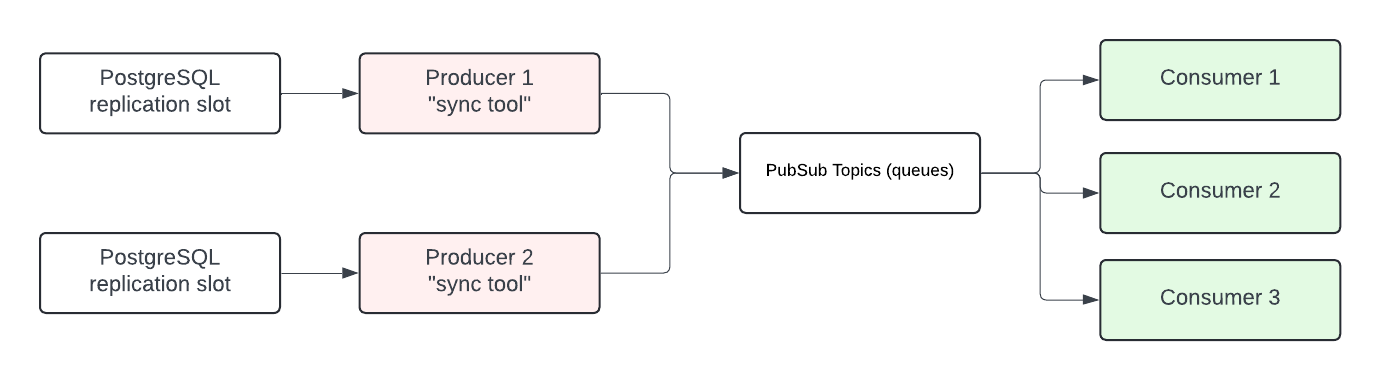
動機
gitlab-rails の PostgreSQL データベースは分析ワークロード向けに最適化されていません。長年にわたり、チーム(Optimize、Analytics)はスケーラブルな分析機能を設計する際にいくつかの課題に直面してきました。これらの機能は動作しますが、バックグラウンドの集計・非正規化など相当なエンジニアリング投資を必要とし、チームの速度に大きく影響し、多くの場合 OLTP データベースに特化した最適化につながり、データ分析を提供する能力よりも優先されます。
さらに、OLTP データベースでの分析ワークロードの実行は長年にわたって多くの本番インシデントを引き起こし、本番の負荷に不必要に追加されます。
ClickHouse 分析データベースを採用することで、GitLab 内の既存の分析機能をサポートするスケーラブルなソリューションができました。主な課題はデータ同期です。現在、PostgreSQL から ClickHouse にデータを同期する少なくとも 3 つの異なる方法があります。これらのソリューションは特定の問題に合わせて調整されることが多く、汎化が難しいです(データを送信するための定期的なワーカー、データの一貫性を確保するための一貫性ワーカー)。これらの同期戦略の一部は GitLab.com 向けに特に実装されています。PostgreSQL から他のデータベースシステムにデータを転送するための統一されたアプローチを確立することで、データ同期プロセスが大幅に簡素化・合理化され、断片化が減少し、全体的な効率が向上します。
Siphon のようなツールを使用することで、最小限の遅延で PostgreSQL データベーステーブルを他のデータベースシステムで効率的に利用可能にできます。
Siphon の他の可能なユースケース:
- PostgreSQL データベースからのすべてのデータ同期実装を統合することで、データ統合の取り組みに貢献する。
- データチームのために本番データベースを Snowflake にレプリケートする。
- Optimize と Platform Insights を超えたすべての GitLab 機能の高度な分析機能を実装する。
- Trust and Safety チームの Omamori プロジェクトによるリアルタイムの脅威と不正使用の検出。
- データベースの変更に非同期で反応できる GitLab 機能の構築。
- お客様にデータ変更をストリーミングする方法を提供する。
代替オプション
以下のツールを検討しました。
- PeerDB
- 最近 ClickHouse に買収され、他のデータウェアハウスへの注力が減少または無くなっています。
- Debezium
- Debezium は Kafka が必要で(セルフマネージドインスタンスには問題になる可能性あり)、多くの新しい依存関係をもたらします。
- Airbyte
- スキーマ変更のサポートなしなど、重大な制限があります。
初期データスナップショット機能を持つ PostgreSQL パブリケーションに一度に 1 テーブルずつ段階的に追加することをサポートするツールは見つかりませんでした。PoC フェーズ中に、少なくとも 1 回の配信保証(重複したイベントを許容)を前提として、最終的に一貫した方法でこれを実現する手順を見つけました。
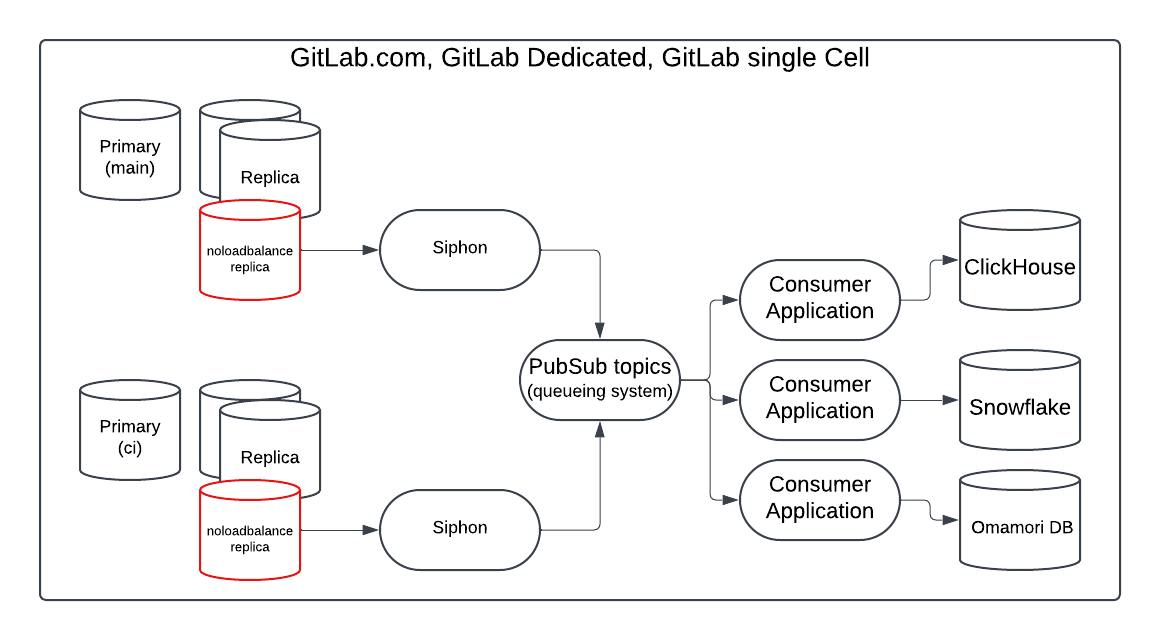
インフラダイアグラム
このダイアグラムは、1 つのコンシューマーアプリケーションが ClickHouse にデータを取り込む GitLab.com のデプロイを示しています。MVP には Snowflake にデータを取り込む別のコンシューマーアプリケーションも含まれます。
将来の状態: 複数のセル
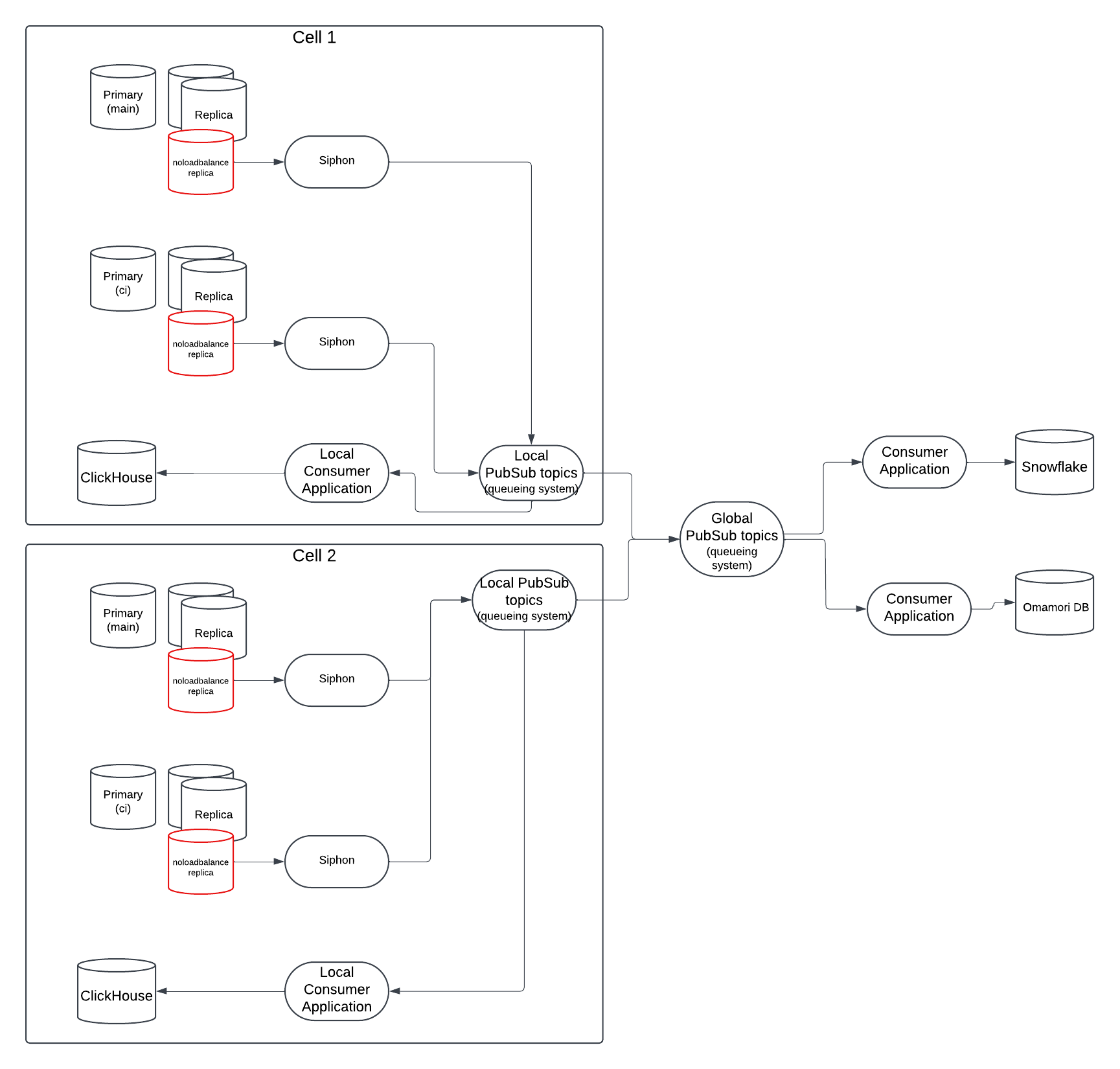
マルチセル環境では 2 種類のコンシューマーがあります。
- グローバルコンシューマー: すべてのセルからデータを受信できる。
- ローカルコンシューマー: デプロイされているセルのキューのみ読み取れる。
注意: セットアップには、特別なコンシューマーがセルローカルのキューイングシステムからグローバルキューイングシステムにデータをプッシュするセルローカルのキューイングシステムも含まれる場合があります(GitLab.com のみ)。
プロデューサーアプリケーションのコンポーネント
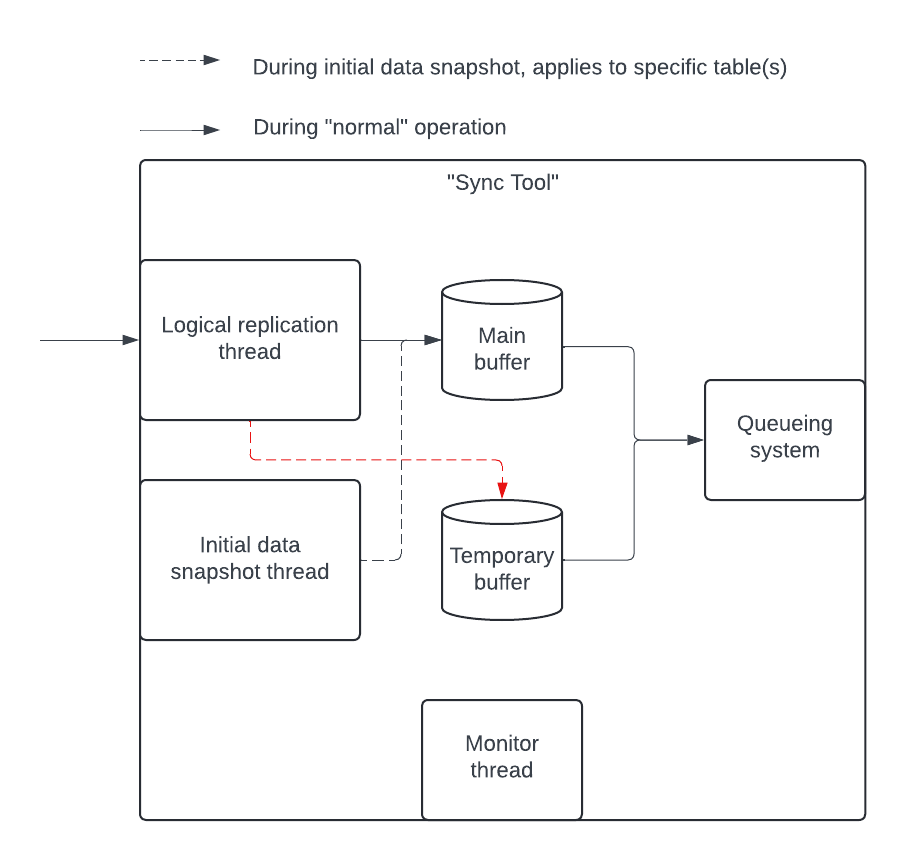
- Lock ゴルーチン: 指定されたアプリケーション ID(設定)で PostgreSQL DB に接続されているアプリケーションのインスタンスが 1 つのみであることを確保します。アドバイザリーロックを使用します(関連 Issue)。
- 論理レプリケーション ゴルーチン: 論理レプリケーションストリームを読み取り、メインバッファにデータをプッシュします。
- 初期データスナップショット ゴルーチン: 既存のテーブルからデータをキャプチャします。このゴルーチンは初期データスナップショット完了後はほぼアイドル状態です。
- モニター ゴルーチン: 定期的に統計を収集します。
初期データスナップショット手順
パブリケーションを初めて作成する際、最初のステップとしてアプリケーションはデータベーステーブルから既存のデータを読み取る必要があります。これには PostgreSQL への 1 つ以上の追加接続が必要です。 1 つのテーブルの初期データスナップショットの高レベルなプロセスは以下の通りです。
- 初期データスナップショット用に設定された PostgreSQL サーバーが、
PUBLICATIONを変更した LSN(テーブルが追加された)に追いついていることを確認する。 - テーブルサイズと使用するブロック数を検査・決定する。
- ブロック数を使用して、N スレッドで処理できる N 範囲を決定できます(設定可能)。
- バッチでデータを読み取り、シリアル化してキューイングシステムにペイロードを送信する。効率的な TID 範囲スキャンを使用する。
2 番目の物理スタンバイサーバーを初期データスナップショットに使用する場合の一貫性を確保するために、最初のステップが重要です。
初期データスナップショット中、すべてのレコードは INSERT 文になります。キューイングシステムにバッチを送信する順序は重要ではありません。初期データスナップショットが取得されている間、該当するテーブルの論理レプリケーションストリームからのデータをエンキューしてはなりません。
PostgreSQL データベースから一貫したスナップショットを取得するには、スナップショットをエクスポートし、スレッドがデータをエクスポートしている間、スナップショットをエクスポートした接続を開いたままにする必要があります。非常に大きなテーブルの場合、このプロセスは非常に長い時間(時間単位)かかる場合があり、アプリケーションエラーや接続が閉じられた場合にスナップショットプロセスを再起動する必要があります。これは重要なプロセスで、通常よりも長い期間ロックを保持する可能性があります(hot_standby_feedback=off レプリカから呼び出されない場合)。このためデータスナップショットプロセスをできる限り迅速にすべきです。
スナップショットのエクスポート:
BEGIN;
SELECT pg_export_snapshot(); -- '00000006-00053166-1'
-- 接続を開いたままにする
データをテーブルから読み取るすべての接続に対してこれを行います:
BEGIN TRANSACTION ISOLATION LEVEL REPEATABLE READ;
SET TRANSACTION SNAPSHOT '00000006-00053166-1'; -- エクスポートされたスナップショットを使用
SELECT ... -- テーブルをクエリする
データシリアル化
スペース使用量が少なく、シリアル化パフォーマンスが高いため、シリアル化フォーマットとして protobuf を使用する予定です。PostgreSQL のデフォルト論理デコード出力プラグイン(pgoutput)から移植性のために読み取りながら、Siphon は受信したデータを protobuf フォーマットに変換します。
protobuf スキーマはカラムリストを配列として表現し、アプリケーションを再構築・再デプロイせずにデータベーススキーマの変更を処理するのに役立ちます。これはコンシューマーアプリケーションにデータベースカラム変更を処理する追加の複雑さが必要になることを意味します。
キューイングシステムにプッシュされる可能性のある 1 つの「パッケージ」の JSON 表現の例:
{
"table": "issues",
"schema": "public",
"application_identifier": "prd.cell1.main.1",
"events": [
{
"operation": "INSERT",
"timestamp": "2018-12-10T13:45:00.000Z",
"columns": [
{
"name": "id",
"int64_value": 12
},
{
"name": "title",
"string_value": "My issue"
}
],
},
{
"operation": "DELETE",
"timestamp": "2018-12-10T13:45:30.000Z",
"columns": [
{
"name": "id",
"int64_value": 15
}
]
}
]
}
上記のパッケージには 2 つのイベントが含まれています。キューイングシステムの過負荷を防ぐため、アプリケーションはイベントを一定の制限(サイズと時間制限)までバッファリングし、テーブルごとに 1 つのパッケージとしてイベントをシリアル化します。例えば、3 秒のウィンドウ(設定可能)で issues に 30 のイベント、projects に 15 のイベントを受信した場合、アプリケーションはキューイングシステムに 2 つのパッケージをプッシュします。
スケーリング
潜在的なボトルネック:
- PostgreSQL 論理レプリケーションスロットが WAL データを十分に速くデコードできない。
- Siphon が論理レプリケーションストリームを読み取り、データを十分に速くシリアル化できない。
これらはどちらも、異なるテーブル設定で複数の Siphon プロデューサーアプリケーションを実行することで水平スケーリングによって対処できます。Siphon インスタンスは異なる PostgreSQL レプリカに接続できます。例えば:
- アプリケーション 1 がメイン DB をレプリケート:
issues、users、merge_requestsテーブル。 - アプリケーション 2 がメイン DB をレプリケート:
events、audit_eventsテーブル。 - アプリケーション 3 が CI DB をレプリケート:
ci_buildsテーブル。
注意: デプロイされた 1 つの Siphon アプリケーションは、最も忙しいテーブル(またはテーブルパーティション)を処理するのに十分なパフォーマンスを発揮するはずです。「最悪のケース」のシナリオでは、1 つのテーブル専用のアプリケーションが必要になる場合があります(可能性は低い)。
注意: 1 つの PostgreSQL データベースは異なる論理レプリケーションスロットを使用して複数の Siphon アプリケーションをサポートできます(デフォルトは 10 スロット、この設定の変更には再起動が必要)。
データボリューム
PoC フェーズ中に初期の論理レプリケーションイベントボリューム計算が行われました。
現在、データベース(main、ci)ごとに 1 秒あたり 15k〜25k の論理レプリケーションイベント(INSERT、UPDATE、DELETE)が見られます。Siphon がすべてのテーブルから論理レプリケーションイベントを読み取らないと仮定すると、1 つの Siphon アプリケーションが 10k〜15k の論理レプリケーションイベント(読み取り、解析、シリアル化、キューへのプッシュ)を処理できると期待されます。
いくつかのテーブルを選択して行サイズをサンプリングすることでデータボリュームを概算できます。例:
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from issues t where id in (select id from issues TABLESAMPLE SYSTEM (0.001));
avg_row_size
-----------------------
1609.6599190283400810
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from projects t where id in (select id from projects TABLESAMPLE SYSTEM (0.001));
avg_row_size
-----------------------
376.8530259365994236
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from users t where id in (select id from users TABLESAMPLE SYSTEM (0.001));
avg_row_size
----------------------
458.2028985507246377
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from todos t where id in (select id from todos TABLESAMPLE SYSTEM (0.001));
avg_row_size
---------------------
97.5580929487179487
SELECT AVG(pg_column_size(t.*)) AS avg_row_size from notes t where id in (select id from notes TABLESAMPLE SYSTEM (0.001));
avg_row_size
----------------------
895.0119381293470362
悲観的なケースとして平均イベントサイズが 1 キロバイトと仮定すると、Siphon は PostgreSQL からの受信ネットワークトラフィックを 1 秒あたり約 10〜15 メガバイト処理します。データをシリアル化・圧縮することで、ペイロードサイズを 20〜40% 削減できます。その結果、キューイングシステムは 1 秒あたりいくつかの(パッケージ化された)イベントを処理し(設定されたテーブルに対して 3 秒ごとにイベントが送信されると仮定)、総ペイロードサイズは数メガバイトになります。
データベーススキーマの変更
ツールの MVP バージョンでは、データベーススキーマの変更を導入する際に ClickHouse と Snowflake データベースを管理するチームとの調整が必要になる場合があります。PostgreSQL とダウンストリームのデータベースシステム間の偶発的なスキーマの乖離リスクを軽減するために、一貫性を確保するためのツールを実装します。さらに、GitLab アプリケーションリポジトリにCI テストを追加して、そのようなイベントが発生したときに通知を受け取る予定です。
MVP では以下のデータベーステーブル(メインデータベースのみ)を特定しました。
namespacesprojectseventsissuesmerge_requestsnamespace_detailsbulk_import_entitiesmilestonesnotes
最終的にはデータベーススキーマの変更を自動的に処理できるようになります。いくつかのアイデアはこの Issueに記載されています。
今のところ、データベーステーブルスキーマの同期を保つ方法は以下の通りです。
- カラムの追加/削除: CI テストが変更を通知する。
- ClickHouse: ClickHouse テーブルスキーマを更新するための追加マイグレーションを追加する(自動化可能)。
- Snowflake: TBD
- カラムの変更(名前変更、精度変更など):
- ClickHouse: 複雑さによっては、カスタムマイグレーションが必要。
- Snowflake: TBD
- テーブルの切り詰め: サポートされていない
- ClickHouse: 手動で切り詰めるか、追加のマイグレーションを追加する可能性が高い。
- Snowflake: TBD
ClickHouse DB は PostgreSQL と同様のマイグレーションツールがあるため、一般的にメンテナンスが容易です。マイグレーションツールはすでにデプロイプロセスの一部です。
コンシューマーアプリケーション
データベーススキーマが古くなっていないことを確認するために、これらのアプリケーションに検出と再試行メカニズムを実装する予定です。
- アプリケーション起動時に、すべてのデータベーステーブルスキーマをリクエストする。
- pub-sub システムから特定のテーブルのイベントパッケージを受信したとき、受信したカラムリストと比較する。
- カラムリストが異なる場合、テーブルスキーマを再度リクエストする(バックオフ付き再試行)
- カラムリストが一致する場合、続行する。
- カラム値を含む
INSERT INTO文を構築する。 INSERT INTO文を実行する。- pub-sub システムのイベント/アイテムを処理済みとしてマークする。
カラムリストが異なり、タイムアウトに達した場合、イベントデータの処理を停止します。アラートと手動介入が必要になります。
カスタムコンシューマーアプリケーション開発
MVP フェーズ中は、コンシューマーアプリケーション開発のサポートを意図していません。ClickHouse と Snowflake データベース向けに 2 つのアプリケーションを開発する予定です。
認可とデータアクセス
特定のキューへのアクセス制御は、キューイングシステムによって処理されます(例えば NATS には高度な認可設定オプションがあります)。
データフィルタリング
ハッシュやキーなどの機密データは、プロデューサーレベルでフィルタリングする必要があります。Siphon の設定により、論理レプリケーションストリームからスキップするカラムを指定できるようにします。
データベースカラムのリストは、既知の監査済みシステム(例えばデータカタログ)から取得されます。
レッドデータの処理
レッドデータの処理と、ターゲットデータベースシステムに挿入する前に特定のカラムをフィルタリングすることは、コンシューマーの責任です。コンシューマーは外部ソース(例えばデータカタログ)から特定のデータベースカラムのデータ分類に関するメタデータをリクエストする場合があります。
プロジェクト管理
作業は Siphon プロジェクトで追跡されます。MVP にはエピックがあります。
言語: Golang
以下のライブラリを使用して Golang で実装する予定です。
- 論理レプリケーションストリームの読み取り:
pglogrepl - PostgreSQL データベースへの接続:
pgx - キューイングシステムへの接続:
nats.go(NATS はまだ評価中) - データシリアル化ライブラリ:
protobuf - 圧縮ライブラリ: TBD(
zstdを使用する予定)
監視
アプリケーションは Prometheus によるメトリクスデータの消費のための HTTP エンドポイントを公開します(セットアップ Issue、メトリクス追加 Issue):
- 処理されたデータに関する統計(テーブルごとの
INSERT、DELETE、UPDATEイベント数)。 - 各処理ステップ(解析、シリアル化)のタイミング。
- バッファサイズ。
- メモリ使用量。
- レプリケーション遅延に関する情報(PostgreSQL 側)。レプリケーションスロットからの未消費データボリュームを追跡する。
このデータの一部は、アプリケーションをログシステム(Kibana)と統合するためにログに記録される必要があります。
暗号化
データベースと pub-sub(キューイング)システムへの接続は、転送中のデータセキュリティを確保するために安全な TLS 接続を使用します。
pub-sub システムを実行するコンピュートノードにフルディスク暗号化が有効になっている場合、Siphon アプリケーション内でのメッセージの暗号化・復号化は必要ありません。
要件:
- 以下への TLS/SSL 接続:
- PostgreSQL
- ClickHouse
- Snowflake
- pub-sub システム
- pub-sub システムのストレージのフルディスク暗号化。
NOTE: 詳細については、ディスカッション Issue を参照してください。
障害シナリオ
PostgreSQL 接続が閉じられた場合
アプリケーションは数回再試行してから終了します。
初期データスナップショット接続が閉じられた場合、スナップショットプロセス全体をクリーンアップする必要があります。このエラーは回復不可能で、スナップショットプロセスを最初から再起動する必要があります(エクスポートされたすべてのデータを削除)。
キューイングシステムが利用できない場合
アプリケーションは数回再試行してから終了します。
トピック/キューが利用できないためキューイングシステムがペイロードを拒否した場合
再試行メカニズムを使用します。
アプリケーションがクラッシュした場合
環境はアプリケーションが再起動されることを確認する必要があります。
Siphon ポッドが終了した場合
環境はこれを検出して新しいインスタンスを起動する必要があります。プロデューサーアプリケーションはローカルディスクにデータを永続化しません。
ランタイムリスク
PostgreSQL データベースサーバー上の論理レプリケーションは、かなりの量のリソースを消費する可能性があります。プライマリデータベースへの影響を最小限にするために、レプリカを使用して論理レプリケーションストリームを読み取り、初期データスナップショットを取ることを計画しています。
Issue と軽減策
Siphon がダウンしているか WAL データを消費していない場合
- 問題: レプリカへの WAL ファイルの蓄積、高ディスク使用量につながる。
- 軽減策:
- レプリケーション遅延と WAL ファイル数を監視する。
- 必要に応じてレプリケーションスロットを削除するための閾値(「ポイントオブノーリターン」)を定義する。
データベースレプリカが失われた、またはレプリケーションスロットが削除された場合
- 問題: 一貫した方法でレプリケーションを再開できない。
- 軽減策:
- データの完全な再同期(初期データスナップショット)を実行する。
- コンシューマーとダウンストリームシステムが、必要なクリーンアップステップを含めて最初からの同期プロセスを再構築/再起動できることを確認する。
PostgreSQL のパフォーマンス問題
- 問題: 論理デコード遅延の増大 - 書き込みレートに追いつけない。
- 軽減策:
- 水平スケーリング、異なるレプリカサーバーを使用した複数の Siphon アプリケーションの使用。
一貫性
- 問題: バグまたはスイッチオーバー/フェイルオーバーによる WAL レコードの欠落。
- 軽減策:
- ターゲットデータベースシステムへの影響を評価し、データベースの再同期が必要かどうかを決定する。
将来の考慮事項
PostgreSQL 17 では論理レプリケーションスロットの同期機能が導入される予定です。この機能により、完全なデータ再同期を必要とする障害を防ぎ、論理レプリケーションがより堅牢になります。
デプロイ
外部依存関係
プロデューサーアプリケーション:
- 論理レプリケーション用に設定された PostgreSQL サーバーへの接続(PostgreSQL v14+)。
- キューイングシステムへの接続。
コンシューマーアプリケーション:
- キューイングシステム(例: NATS)への接続。
- ターゲットシステム(例: ClickHouse、Snowflake)への接続。
PostgreSQL サーバー
PostgreSQL 16 では、データベースレプリカ上で論理レプリケーションを設定できます。これにより Siphon はプライマリデータベースや GitLab メインアプリケーションが使用する他の読み取り専用レプリカに影響を与えることなく、PostgreSQL からデータを低レイテンシーで抽出できます。
オプションとして、スナップショットプロセスに異なる PostgreSQL サーバーを使用できます。これは大規模な GitLab インスタンス(GitLab.com)にとって特に重要です。GitLab.com では、hot_standby_feedback 設定を無効にしたストリーミングレプリケーションで動作する物理スタンバイを使用する予定です。
これにより、クラスターに影響を与えることなく(長いトランザクション、ブロッキング vacuum)初期データスナップショットを取得できます。
インフラニーズ:
- プロデューサーアプリケーションを実行するための 1 つのノード(MVP 後は複数のアプリケーションを実行します)。
- コンシューマーアプリケーションを実行するための 1 つ以上のノード(ターゲットデータベースごとに 1 アプリケーション)。
- キューイングシステムを実行するためのクラスター(TBD)。
ロールアウト
ツールは設定ファイルを通じてテーブルを段階的に追加できるように構築されます。新しいテーブルが追加されると、システムは最初のステップとして初期データスナップショットを取り、その後論理レプリケーションストリームを通じてキャプチャされた変更を続けます。
MVP 後のステップ
- GitLab アプリケーションからの自動スキーマ検出。
- 複数のアプリケーションインスタンスの実行(CI、Main、Sec データベース)。
- プロデューサー設定を動的に変更するコーディネーターアプリケーション。
- Dedicated、セルフマネージドサポート。
c955a93f)