GitLab オブザーバビリティ - ロギング
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| proposed | vespian_gl | mappelman | sguyon
nicholasklick | monitor observability | 2023-10-29 |
概要
この設計ドキュメントでは、トレーシングとメトリクスと共に GitLab Observability Backend(GOB)の一部となるログを格納・クエリするためのシステムを説明します。 システムの中核は、データインジェストに OpenTelemetry ロギング仕様を、ストレージに ClickHouse データベースを活用しています。 ユーザーは GitLab UI を通じてデータとやり取りします。 システム自体はマルチテナントで、ユーザーがアプリケーションログを格納・クエリし、将来のイテレーションでは他のオブザーバビリティシグナル(トレース、エラー、メトリクス等)と相関付ける方法を提供します。
動機
トレーシングとメトリクスに続き、ロギングは完全なオブザーバビリティソリューションをユーザーに提供するためにサポートする必要がある最後のオブザーバビリティシグナルです。
ロギング自体は最も重要なオブザーバビリティシグナルでもあると言えます。非常に普及しているためです。 アプリケーションオブザーバビリティの歴史においてメトリクスとトレーシングより前に存在し、通常は開発の最初のうちに実装されます。
ロギングサポートがなければ、ユーザーがプラットフォームを使って開発するアプリケーションのパフォーマンスと操作を完全に理解することが非常に困難、または不可能になります。
目標
- マルチテナント: 各ユーザーとそのデータは、プラットフォームを使用する他のユーザーから分離されているべきです。 ユーザーはプラットフォームに送信したデータのみをクエリできます。
- OpenTelemetry 標準に従う: ログのインジェストは OpenTelemetry プロトコルに従うべきです。 OpenTelemetry プロトコルのために開発されたツールとノウハウを再利用できるほか、ワイヤプロトコルとデータストレージ形式については車輪の再発明をする必要がありません。
- データストレージバックエンドとして ClickHouse を使用する: ClickHouse は GitLab でのオブザーバビリティデータの定番ソリューションになっています。 トレーシングとメトリクスのソリューションはすでに ClickHouse を使用しているため、ロギングもそれと一貫性を持ち、新しい依存関係を導入しないようにするべきです。
- ユーザーが合理的に複雑なクエリを使ってデータをクエリできる: ログを格納するだけでは、ユーザーにとってあまり価値がありません。
非目標
- 複雑なクエリサポートとログ分析 - 少なくとも最初のイテレーションでは、ユーザーが定量的なログ分析に使用したい
GROUP BYクエリなど、複雑なクエリのサポートは計画していません。 これをサポートするのは簡単ではなく、クエリ言語構文の領域でのさらなる研究と作業が必要です。 - 高度なデータ保持 - ログはトレースやメトリクスと法的要件の面で異なります。 当局は進行中の調査の一環として保存されているログを要求する場合があります。 最初のイテレーションでは、例えばアクセスログを保存する予定がある場合には現時点ではシステムはそれに対応していないため、セカンダリシステムが必要であることをユーザーに警告する必要があります。 このユースケースに対応するには、ログ/データの整合性と長期ストレージポリシーに関してさらに多くの作業が必要です。
- データ削除 - データが事前に定義されたストレージ期間の後に単純に期限切れになるケースを除き、ユーザーによる個々のログの削除のサポートは計画していません。 これは後のイテレーションに残します。
- ログとトレースのリンク - 少なくとも最初のイテレーションでは、UI でのログとトレースのリンクのサポートは意図していません。
- ログのサンプリング - トレースについては、クォータ/制限の実施にのみ集中しながら、ユーザーがデータを送信前にサンプリングすることを期待します。 ログもこのパターンに従うべきです。 ログのサンプリング実装はまだ未成熟のようです - ログサンプラーは OTEL Collector で実装されていますが、トレースのサンプリングと一緒に機能するかどうかは不明で、公式仕様もありません(Issue、プルリクエスト)。
提案
ログインジェストのアーキテクチャは、トレーシングとメトリクスの提案で説明されているパターンに従います:
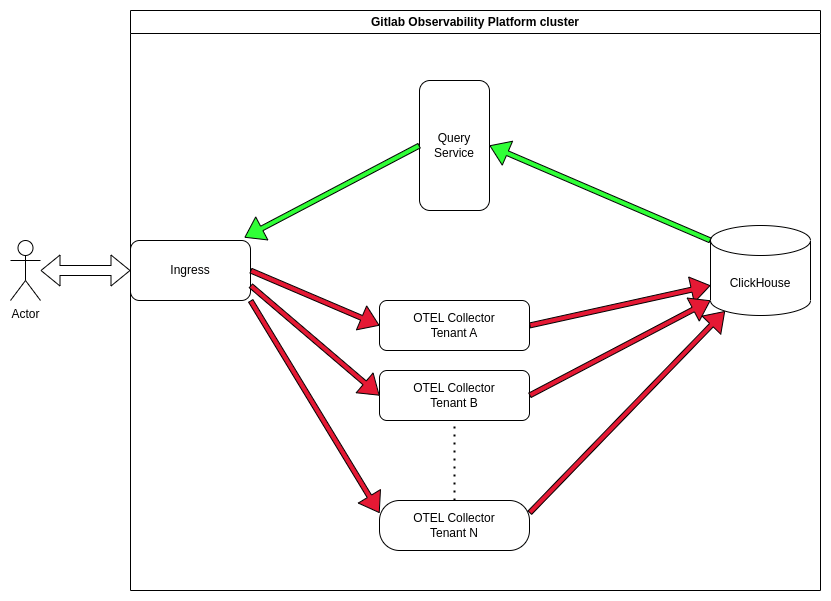
これらの提案で導入されたコンポーネントを再利用するため、新しいサービスは追加されません。 各トップレベルの GitLab ネームスペースには独自の OTEL コレクターがあり、クラスター全体の Ingress によってインジェストリクエストがそこに振り向けられます。 一方、ユーザーからのクエリを処理する単一のクラスター全体のクエリサービスがあります。 クエリサービスはテナントを認識します。 ユーザーリクエストのレート制限は Ingress レベルで行われます。 クラスター全体の Ingress は現在 Traefik を使用しており、クラスター内の他のすべてのサービスと共有されています。
インジェストパス
顧客から HTTP を介して JSON 形式でログオブジェクトを受信します。 リクエストはクラスター全体の Ingress に到着し、適切な OTEL コレクターにルーティングされます。 コレクターはそのリクエストを処理し、Clickhouse に対して INSERT 文を実行します。
読み取りパス
GOB は HTTP/JSON API を公開しており、例えば GitLab UI はこれを使用してログをクエリし、レンダリングします。 クラスター全体の Ingress は、クエリサービスにリクエストをルーティングし、クエリサービスは API リクエストを解析して ClickHouse に対して SQL クエリを実行します。 結果は JSON レスポンスにフォーマットされてクライアントに送り返されます。
設計と実装の詳細
レガシーコード
ロギングシグナルの処理は、トレースやメトリクスのシグナルとは異なり、サポートする必要のある大量のレガシーコードによって大きく影響を受けます。 メトリクスとトレーシングでは、OpenTelemetry 仕様が活用できる新しい API と SDK を定義しています。 ログでは、OpenTelemetry はよりブリッジとして機能し、レガシーのライブラリ/コードがデータを送信できるようにします。
ユーザーは filelogreceiver または fluentd を使用して、プレーンなログファイルからログシグナルを作成できます。 既存のログライブラリは Log Bridge API を使用して、OTEL プロトコルを使ってログを送信できます。 時間の経過とともにエコシステムはおそらく発展し、オプションの数も増えるでしょう。 ログが_どのように_インジェストされるかはユーザー次第という前提があります。
したがって、OTEL 形式でログを受け付ける HTTP エンドポイントのみを公開し、ログがすでに適切に解析・フォーマットされていることを前提とします。
ログ、イベント、スパンイベント
ログメッセージは OTEL 仕様に従って3つの異なるオブジェクトを使用して送信できます:
少なくとも最初のイテレーションでは、ログ、イベント、またはスパンイベントのいずれかのみをサポートできます。
スパンイベントは送信できません。様々な理由でトレーシングを実装できない、または実装しない多くのレガシーコードが存在するためです。
イベントは内部的に同じデータモデルを使用していますが、そのセマンティクスは異なります。
ログには第一級パラメーターとして必須の重大度レベルがありますが、イベントにはその必要はありません。イベントにはログレコードの Attributes フィールドに必須の event.name とオプションの event.domain キーがあります。
さらに、ログは通常文字列形式のメッセージを持ち、イベントはキー値ペアの形式でデータを持ちます。
Log と Event の API を分離する議論があります。
これら2つの違いの詳細についてはこちらを参照してください。
開発者/潜在的なユーザーの観点から見ると、イベントを明示的に送信する代わりにログレコードとしてモデル化できないロギングのユースケースはないようです。 コミュニティが例として挙げるもの(例えばこちらやこちら)は十分に説得力がなく、単純にログレコードとしてモデル化できます。
したがって、ログオブジェクトのみをサポートするという決定はシンプルで退屈なソリューションのようです。
レート制限
トレースと同様に、ロギングデータのインジェストは Ingress レベルで行われます。 forward-auth フローの一部として、Traefik はリクエストを Gatekeeper に転送し、Gatekeeper は Redis を活用してカウントします。 これは現在インジェストパスに対してのみ行われています。 詳細については MR の説明を確認してください。 読み取りパスのレート制限の実装はこちらで追跡されています。
データベーススキーマ
OpenTelemetry 仕様は実装が必要なフィールドのセットを定義しています。 ドキュメント化されたスキーマと protobuf 定義との間にはいくつかの小さな不一致があります。例えば TraceFlags はドキュメントでは8ビットフィールドとして定義されていますが、proto 定義では32ビット幅のフィールドです。 残りの24ビットは予約されています。 ログメッセージ本体は任意のオブジェクトであることができ、レコードのサイズ制限はありません。 この設計ドキュメントの目的のために、長さ制限なしのプレーンテキストまたは JSON などの任意の文字列になると仮定します。
データフィルタリング
スキーマはブルームフィルターを広範囲に使用しています。
偽陰性を防ぎますが、偽陽性は依然として可能です。したがって、ユーザーに != クエリを提供することはできません。
Body フィールドは特別なケースで、tokenbf_v1 トークン化ブルームフィルターを使用します。
tokenbf_v1 スキッピングインデックスは ngrambf_v1 インデックスよりシンプルで軽量なアプローチに見えます。
以下の非常に予備的なベンチマークに基づくと、ngrambf_v1 インデックスはチューニングも大幅に困難になります。
ただし制限として、ユーザーは今のところ完全な単語のみ検索できます。
特定のグラニュール内に最大 10,000 の異なる単語があると見積もり(推定)、偽陽性の確率 0.1% を目標としています。
このツールを使用してフィルターの最適サイズを 143776 ビット、10 のハッシュ関数と計算しました。
スキッピングインデックス、==、!=、LIKE 演算子
スキッピングインデックスはスキャンするグラニュールの検索のみを最適化します。
== と LIKE クエリは期待通りに機能しますが、!= はブルームフィルターの制限によりフルスキャンになります。
少なくとも最初のイテレーションでは、!= 演算子をユーザーに提供しません。
データに基づくと、最初のイテレーションでは tokenbf_v1 フィルターを ngrambf_v1 より簡単にチューニングできます。ngrambf_v1 の場合、合理的に大きなデータセットに対するクエリはほぼ常にフルスキャンになります。
その理由は、インデックス内の ngram の数がトークンより多く、高いカーディナリティの単語/記号を持つデータではマッチがより頻繁に発生するためです。
これらの前提を検証するために非常に予備的なベンチマークが実施されました。
テストデータとして、以下のテーブルスキーマとインサート/関数を使用しました。
単一テナントをシミュレートします。Body フィールドのみに集中したいためです。
通常、プライマリインデックスにより、特定のテナントのデータがないグラニュールをスキップできます。
tokenbf_v1 バージョンのテーブル:
CREATE TABLE tbl2
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Duration` UInt8 CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
INDEX idx_body Body TYPE tokenbf_v1(143776, 10, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
SETTINGS index_granularity = 8192
ngrambf_v1 バージョンのテーブル:
CREATE TABLE tbl3
(
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` String CODEC(ZSTD(1)),
`ServiceName` LowCardinality(String) CODEC(ZSTD(1)),
`Duration` UInt8 CODEC(ZSTD(1)),
`SpanName` LowCardinality(String) CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
INDEX idx_body Body TYPE ngrambf_v1(4,143776, 10, 0) GRANULARITY 1
)
ENGINE = MergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ServiceName, SpanName, toUnixTimestamp(Timestamp), TraceId)
SETTINGS index_granularity = 8192
両方の場合で、Body フィールドは JSON マップオブジェクトをシミュレートするデータで埋められました:
CREATE FUNCTION genmap AS (n) -> arrayMap (x-> (x::String, (x*(rand()%40000+1))::String), range(1, n));
INSERT INTO tbl(2|3)
SELECT
now() - randUniform(1, 1_000_000) as Timestamp,
randomPrintableASCII(2) as TraceId,
randomPrintableASCII(2) as ServiceName,
rand32() as Duration,
randomPrintableASCII(2) as SpanName,
toJSONString(genmap(rand()%40+1)::Map(String, String)) as Body
FROM numbers(10_000_000);
tokenbf_v1 テーブルの場合:
==等値比較が機能し、スキッピングインデックスにより 224/1264 グラニュールがスキャンされました:
zara.engel.vespian.net :) explain indexes=1 select count(*) from tbl2 where Body == '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
EXPLAIN indexes = 1
SELECT count(*)
FROM tbl2
WHERE Body = '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
Query id: 60827945-a9b0-42f9-86a8-dfe77758a6b1
┌─explain───────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ ReadFromMergeTree (logging.tbl2) │
│ Indexes: │
│ MinMax │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ Partition │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ PrimaryKey │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ Skip │
│ Name: idx_body │
│ Description: tokenbf_v1 GRANULARITY 1 │
│ Parts: 62/69 │
│ Granules: 224/1264 │
└───────────────────────────────────────────────────┘
23 rows in set. Elapsed: 0.019 sec.
!=不等比較も機能しますが、フルテキストスキャンになります - すべてのグラニュールがスキャンされました:
zara.engel.vespian.net :) explain indexes=1 select count(*) from tbl2 where Body != '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
EXPLAIN indexes = 1
SELECT count(*)
FROM tbl2
WHERE Body != '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
Query id: 01584696-30d8-4711-8469-44d4f2629c98
┌─explain───────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ ReadFromMergeTree (logging.tbl2) │
│ Indexes: │
│ MinMax │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ Partition │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ PrimaryKey │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ Skip │
│ Name: idx_body │
│ Description: tokenbf_v1 GRANULARITY 1 │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
└───────────────────────────────────────────────────┘
23 rows in set. Elapsed: 0.017 sec.
LIKEクエリが機能し、271/1264 グラニュールがスキャンされました:
zara.engel.vespian.net :) explain indexes=1 select * from tbl2 where Body like '%"11":"162052"%';
EXPLAIN indexes = 1
SELECT *
FROM tbl2
WHERE Body LIKE '%"11":"162052"%'
Query id: 86e99d7a-6567-4000-badc-d0b8b2dc8936
┌─explain─────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ ReadFromMergeTree (logging.tbl2) │
│ Indexes: │
│ MinMax │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ Partition │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ PrimaryKey │
│ Condition: true │
│ Parts: 69/69 │
│ Granules: 1264/1264 │
│ Skip │
│ Name: idx_body │
│ Description: tokenbf_v1 GRANULARITY 1 │
│ Parts: 64/69 │
│ Granules: 271/1264 │
└─────────────────────────────────────────────┘
20 rows in set. Elapsed: 0.047 sec.
ngrambf_v1 トークナイザーはチューニングと使用がはるかに困難です:
- n-gram インデックスを使用した等値比較も機能しますが、ブルームフィルター内のトークンの高い粒度のため、多くのグラニュールをスキップできていません:
zara.engel.vespian.net :) explain indexes=1 select count(*) from tbl3 where Body == '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
EXPLAIN indexes = 1
SELECT count(*)
FROM tbl3
WHERE Body = '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
Query id: 22836e2d-5e49-4f51-b23c-facf5a3102c2
┌─explain───────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ ReadFromMergeTree (logging.tbl3) │
│ Indexes: │
│ MinMax │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ Partition │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ PrimaryKey │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ Skip │
│ Name: idx_body │
│ Description: ngrambf_v1 GRANULARITY 1 │
│ Parts: 60/60 │
│ Granules: 1239/1257 │
└───────────────────────────────────────────────────┘
23 rows in set. Elapsed: 0.025 sec.
- こちらの不等比較もフルスキャンになります:
zara.engel.vespian.net :) explain indexes=1 select count(*) from tbl3 where Body != '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
EXPLAIN indexes = 1
SELECT count(*)
FROM tbl3
WHERE Body != '{"1":"14732","2":"29464","3":"44196","4":"58928","5":"73660","6":"88392","7":"103124","8":"117856","9":"132588","10":"147320","11":"162052"}'
Query id: 2378c885-65b0-4be0-9564-fa7ba7c79172
┌─explain───────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ ReadFromMergeTree (logging.tbl3) │
│ Indexes: │
│ MinMax │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ Partition │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ PrimaryKey │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ Skip │
│ Name: idx_body │
│ Description: ngrambf_v1 GRANULARITY 1 │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
└───────────────────────────────────────────────────┘
23 rows in set. Elapsed: 0.022 sec.
- LIKE 文は機能しますが、ngram がすべてのグラニュールに一致するためフルスキャンになります:
zara.engel.vespian.net :) explain indexes=1 select * from tbl3 where Body like '%"11":"162052"%';
EXPLAIN indexes = 1
SELECT *
FROM tbl3
WHERE Body LIKE '%"11":"162052"%'
Query id: 957d8c98-819e-4487-93ac-868ffe0485ec
┌─explain─────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ ReadFromMergeTree (logging.tbl3) │
│ Indexes: │
│ MinMax │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ Partition │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ PrimaryKey │
│ Condition: true │
│ Parts: 60/60 │
│ Granules: 1257/1257 │
│ Skip │
│ Name: idx_body │
│ Description: ngrambf_v1 GRANULARITY 1 │
│ Parts: 60/60 │
│ Granules: 1251/1257 │
└─────────────────────────────────────────────┘
20 rows in set. Elapsed: 0.023 sec.
データの重複排除
ユーザーにコスト効率の良いサービスを提供するために、ユーザーから受け取るデータの重複排除を考える必要があります。
ClickHouse の ReplacingMergeTree はプライマリキーに基づいて自動的にデータを重複排除します。
プライマリキーにすべての関連する Log エントリフィールドを含めることはできないため、フィンガープリントをプライマリキーの最後の部分として使用するアイデアがあります。
通常はインデックスには使用せず、ユニークなレコードがガベージコレクションされないようにするためだけに使用します。
フィンガープリント計算アルゴリズムと長さはまだ選択されていません。metrics がフィンガープリント計算に使用しているものと同じものを使用するかもしれません。
今のところ、128 ビット幅(16個の8ビット文字)であると仮定します。
フィンガープリント計算に使用するカラムは、プライマリキーに存在しないカラムです: Body、ResourceAttributes、LogAttributes。
フィンガープリントは非常に高いカーディナリティのため、プライマリインデックスの最後の位置に配置する必要があります。
データ保持
ログをどのくらいの期間保存する必要があるか、また個別のログの削除(例えばプライベートデータや調査に関連するデータの漏洩のため)を許可するかどうかについて法的な問題があります。
一部の法域では、ログを数年間保持しなければならず、削除する方法があってはなりません。
これは、フィンガープリントに ObservedTimestamp を含めない限り、重複排除に影響します。
Non-Goals セクションで指摘したように、これは将来のイテレーションで取り組む問題です。
インジェスト時のフィールド
セマンティック規約フィールドを別のカラムに引き出さないことを意図的に選択しています。ユーザーは無数のログフォーマットを使用しており、カラムになる価値のあるプロパティを特定することはおそらく不可能です。
ObservedTimestamp フィールドはインジェスト中にコレクターによって設定されます。
ユーザーは Timestamp フィールドでクエリし、ログのプルーニングは ObservedTimestamp フィールドによって駆動されます。
このアプローチのデメリットは、プライマリインデックスと TTL カラムが異なるため、TTL DELETE がパーツを早めに削除できない場合があることです。データが局在していないかもしれません。
これは良いトレードオフのようです。
ユーザーにはインジェストから始まる定義済みのストレージ期間を提供します。
ユーザーが未来または過去のタイムスタンプを持つログをインジェストする場合、古いログのプルーニングが早すぎるか遅すぎる可能性があります。
ユーザーは主張したログのタイムスタンプを悪用してプルーニングを遅延させることもできます。
ObservedTimestamp アプローチにはこれらの問題がありません。
インジェスト中、SeverityText フィールドは SeverityNumber フィールドが設定されていない場合、SeverityNumber に解析されます。
クエリはプレーンテキストよりも効率的で高い粒度を提供するため、SeverityNumber フィールドを使用します。
DROP TABLE if exists logs;
CREATE TABLE logs
(
`ProjectId` String CODEC(ZSTD(1)),
`Fingerprint` FixedString(16) CODEC(ZSTD(1)),
`Timestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`ObservedTimestamp` DateTime64(9) CODEC(Delta(8), ZSTD(1)),
`TraceId` FixedString(16) CODEC(ZSTD(1)),
`SpanId` FixedString(8) CODEC(ZSTD(1)),
`TraceFlags` UInt32 CODEC(ZSTD(1)),
`SeverityText` LowCardinality(String) CODEC(ZSTD(1)),
`SeverityNumber` UInt8 CODEC(ZSTD(1)),
`ServiceName` String CODEC(ZSTD(1)),
`Body` String CODEC(ZSTD(1)),
`ResourceAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
`LogAttributes` Map(LowCardinality(String), String) CODEC(ZSTD(1)),
INDEX idx_trace_id TraceId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_span_id SpanId TYPE bloom_filter(0.001) GRANULARITY 1,
INDEX idx_trace_flags TraceFlags TYPE set(2) GRANULARITY 1,
INDEX idx_res_attr_key mapKeys(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_res_attr_value mapValues(ResourceAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_key mapKeys(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_log_attr_value mapValues(LogAttributes) TYPE bloom_filter(0.01) GRANULARITY 1,
INDEX idx_body Body TYPE tokenbf_v1(143776, 10, 0) GRANULARITY 1
)
ENGINE = ReplacingMergeTree
PARTITION BY toDate(Timestamp)
ORDER BY (ProjectId, ServiceName, SeverityNumber, toUnixTimestamp(Timestamp), TraceId, Fingerprint)
TTL toDateTime(ObservedTimestamp) + toIntervalDay(30)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1;
クエリ API、クエリ UI
この提案で導入されるクエリ API/ワークフローの背後にある主なアイデアは、クエリの複雑さとクエリのリソース使用量/実行時間の両方に制限を設けながら、ユーザーにクエリの自由を与えることです。 ユーザーがどのようにデータをクエリするか、またはデータがどのように見えるかを正確に予測することはできません。属性を使用する人もいれば、単純にログレベルに集中する人もいます。
Clickhouse では、個々のクエリに設定が含まれることがあり、クエリの複雑さの設定が含まれます。 クエリ制限は、SQL 文を構築する際にクエリサービスによって各クエリに自動的に追加されます。
ログエントリの Body フィールドのフルテキストクエリも、ClickHouse が LIKE クエリを BloomFilters を使用して最適化し、検索語をトークン化することで、クエリサービスによって透過的に処理されます。
将来のイテレーションでは n-gram トークン化を検討するかもしれませんが、今のところクエリは完全な単語のみに制限されます。
ユーザーが重複をインジェストした場合、UI でログエントリを重複排除するかどうかは議論の余地があります。
ReplacingMergeTree の最終的な重複排除が開始されるまでの間、重複したエントリを避けるために max(ObservedTimestamp) 関数を使用できます。
ただし最初のイテレーションでは確実に実施しません。
クエリサービスは、クエリを構築する際に SeverityText 属性を SeverityNumber に透過的に変換します。
クエリサービス API スキーマ
ユーザーが SQL クエリを直接送信できるようにすると、システムを悪用される可能性があるため、これを許可することはできません。 また、ユーザーが SQL クエリ言語の完全な柔軟性を与えられた場合に考えつくすべてのユースケースをサポートすることもできません。 そのため、ユーザーをガイドするシンプルなクリエーター的エクスペリエンスを UI が提供するというアイデアがあります。 GitLab が MR と Issue を検索するために現在持っているものと非常に似ています。 UI コードはユーザーが考案したクエリを JSON に変換し、処理のためにクエリサービスに送信します。 受信した JSON に基づいて、クエリサービスは上述のクエリ制限とともに SQL クエリをテンプレート化します。
今のところ、UI と JSON API は特定のフィールドに対する基本的な操作セットのみをサポートします:
- Timestamp:
>、<、== - TraceId:
==、後のイテレーションでin - SpanId:
==、後のイテレーションでin - TraceFlags:
==、!=、後のイテレーション:in、notIn - SeverityText:
==、!=、後のイテレーション:in、notIn - SeverityNumber:
<、>、==、!=、後のイテレーション:in、notIn - ServiceName:
==、!=、後のイテレーション:in、notIn - Body:
==、CONTAINS - ResourceAttributes:
key==value、mapContains(key) - LogAttributes:
key==value、mapContains(key)
中間 JSON のフォーマットは次のようになります:
{
"query": [
{ "type": "()|AND|OR",
"operands": {
[...]
},
{
"type": "==|!=|<|>|CONTAINS",
"column": "...",
"val": "..."
}
]
}
==|!=|<|>|CONTAINS はネストしない被演算子で、具体的なカラムで操作し、クエリサービスによって処理された後に WHEN 条件になります。
()|AND|OR はネストする被演算子で、他のネストしない被演算子のみを含めることができます。
ネストする被演算子の実装は後のイテレーションに延期するかもしれません。
クエリ構造のトップレベルで被演算子間には暗黙の AND があります。
クエリスキーマは、メトリクス提案で使用されているものと比較して意図的にシンプルに保たれています。
必要が生じた後のイテレーションで QueryContext、BackendContext などのフィールドを追加するかもしれません。
今のところ、スキーマをできるだけシンプルに保ち、将来簡単に変更できるよう API がバージョン管理されていることを確認するだけです。
未解決の質問
ロギング SDK の成熟度
OTEL 標準は、トレーシングなどと同様にロギングのためのスタンドアロン SDK を提供することを意図していません。 独自のロギングライブラリを持たないプログラミング言語(かなりまれなはず)に対してのみ、そうすることを検討するかもしれません。 既存のロギングライブラリはすべて、代わりに bridge API を使用して OTEL コレクターとやり取りしたり OTEL ログ標準でログを送信したりするべきです。
ほとんどの言語は必要な調整を行っていますが、Go は例外です。 Go に対するサポートは最小限です(リポジトリ、リポジトリ)。 公式の Uber Zap リポジトリにはスパンでイベントを送信することについてのIssueがかろうじてあります。 OpenTelemetry のステータスページは Go のサポートがまだ実装されていないと述べています。
Go でのネイティブ OTEL SDK サポートの欠如は、ロギングをドッグフーディングしたい場合に問題になる可能性があります。 filelogreceiver または fluentd を使用してログファイルを解析することで、これらの制限の多くを回避できます。 OTEL での Go のサポートに貢献して改善することも有効なオプションです。
将来の作業
クエリでの != 演算子のサポート
スキーマで使用しているブルームフィルターは、特定のタームがログエントリの本文/属性に存在しないかどうかをテストできません。 これは小さいですが有効なユースケースです。 これに対する解決策は逆インデックスかもしれませんが、これはまだ実験的な機能です。
ドキュメント
ドキュメント化作業の一環として、エラートラッキングのように、異なる言語(uber-zap、logrus、log4j 等)でどのように GOB にデータを送信できるかの例を提供したい場合があります。 一部のアプリケーション(例: systemd/journald)は簡単に変更してデータを送信できないため、filelogreceiver または fluentd を使用したログテーリング/解析が必要です。 インフラをインストルメントし、ドキュメントからコードへのリンクを提供することで、上記の両方のケースに対処できる可能性があります。 このようにして、ソリューションをドッグフーディングし、GCE ロギングソリューションはかなり高価なためコストを節約し、インフラをインストルメントする実際の例をユーザーに提供できます。 これは実装が完了した後のフォローアップタスクの1つになる可能性があります。
ユーザークエリのリソース使用量モニタリング
長期的には、制限の実施により失敗したユーザークエリの数とリソース使用量全般を監視する方法が必要になります。クエリ制限を微調整し、ユーザーが過度に制限されていないことを確認するためです。
イテレーション
最新情報については、Observability グループ計画エピックとそのリンクされた Issue を参照してください。
c955a93f)