GitLab 翻訳サービス
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| rejected | rasamhossain | username | product-manager
engineering-manager | 2024-11-08 |
概要
このデザインドキュメントは、自動翻訳ツールと、Argo というローカライゼーションリクエスト管理システムをミドルウェアとして使用して、GitLab リポジトリと翻訳ベンダーが利用する翻訳管理システム(TMS)向けの翻訳を提供するパイプラインのアーキテクチャ設計を説明しています。インテグレーションツールは、イベント駆動型の Java アプリケーションを通じて、GitLab リポジトリ内の指定されたコンテンツの変更に対する翻訳リクエストを自動的に監視・処理するよう設計されています。
このデザインドキュメントの目的は、アプリケーション自体に完全に焦点を当てているわけではなく、むしろ GitLab インフラ内にこのアプリケーションをどのようにデプロイするかに重点を置いています。ただし、両方についてドキュメント全体を通じて説明します。
インテグレーションツール(Java アプリケーション)は、複数のプロジェクト/リポジトリからの大量イベントを処理しながらデータ整合性を維持し、競合状態を防ぐ非同期のキューベース処理システムを実装しています。特定のフォルダー内のファイル変更を検出することから、Argo のリクエスト管理パイプラインを通じてコンテンツをルーティングし、翻訳されたコンテンツを GitLab リポジトリにコミットするまでの翻訳ワークフロー全体をオーケストレーションします。
このツールは GitLab インフラにデプロイされます:
- アプリケーションコードは Localization グループ 配下の GitLab リポジトリでホストされ、GitLab の CI/CD パイプラインを使用してイメージファイルをビルドします。
- 関連するデータベースは Google Cloud でホストされます。
- Runway を使用してデプロイし、PSC(Private Service Connect)と Cloud SQL Auth Proxy を使用して GCP CloudSQL インスタンスに接続します。
動機
この自動化されたローカライゼーションパイプラインの開発は、いくつかの重大な課題に対処しています:
- 手動作業の削減:
- 以前はすべてのローカライゼーションプロセスに手動介入が必要で、大きなボトルネックとなっていました。
- プロジェクトマネージャーは開発チームと翻訳ベンダーの間の調整に過度な時間を費やしていました。
- ファイル処理とバージョン管理における人的ミスの高いリスク。
- 運用効率:
- ソース文字列の検出から翻訳のデプロイまでの完全なワークフローを自動化します。
- システム間での手動ファイル転送の必要性を排除します。
- ソース文字列の更新からローカライズされたコンテンツの利用可能までの時間を大幅に削減します。
- スケーラビリティのメリット:
- 追加リソースの割り当てなしに増加する翻訳リクエストを処理できます。
- 複数のリポジトリとプロジェクトを同時にサポートします。
- 新しい言語要件とベンダーインテグレーションに容易に適応できます。
- 品質保証:
- 一貫したファイル構造と命名規則を維持します。
- 自動化されたコミットプロセスによるバージョン管理の整合性を確保します。
- 翻訳漏れや古いコンテンツのリスクを低減します。
- コスト効率:
- 手動ローカライゼーション管理に関連する運用コストを削減します。
- プロジェクトの遅延やリソース割り当ての問題を最小化します。
- 合理化されたリクエスト管理を通じて翻訳ベンダーの活用を最適化します。
この自動化されたパイプラインは、ローカライゼーションワークフローの近代化における重要な前進を表し、GitLab リポジトリ全体での多言語コンテンツ管理における効率性と精度の両方を確保します。
ゴール
現在のゴール
GitLab の翻訳パイプラインと翻訳ベンダーとの連携を簡素化・自動化します:
- GitLab リポジトリ内の文字列を翻訳するエンドツーエンドの自動ローカライゼーションインフラとパイプラインを導入します。
- 手動による人の介入が不要です — エンジニア、PM、その他の関係するステークホルダーは、GitLab と翻訳ベンダー間の翻訳管理にかかる時間を節約できます。
- ファイル処理の精度を高め、大規模プロジェクトを整理し、ローカライズされたコンテンツの市場投入までの時間を短縮します。
将来のゴール
- Argo 内からファイルを手動で選択して翻訳リクエストを作成し、スケジュールに基づいて自動実行する機能。
- ファイル形式に対する堅牢なエラー処理と自動品質チェックを作成します。
- 一般的なローカライゼーションの問題に対する自動 QA チェックをセットアップします。
- 翻訳の整合性に関する監視を確立し、自動テスト手順をセットアップします。
提案
このドキュメントはツールの機能に触れており、コンテキストを提供するためにその中核機能について簡単に説明しますが、主な焦点は GitLab 環境内でのデプロイアーキテクチャとインフラ実装にあることを強調することが重要です。このアプローチにより、ツールと翻訳パイプラインがより広いインフラエコシステムにどのように適合し、機能するかを明確に理解できます。
提案は 2 つのセクションに分かれています。セクション 1: 翻訳パイプラインの全体的なアーキテクチャフローと、ツール自体の運用メカニズムを説明します。セクション 2: 提案されたソリューションのデプロイアーキテクチャ、インフラ要件、および実装戦略を詳述します。
セクション 1 : ツール
- 継続的な監視とトラッキング: インテグレーションツールは GitLab リポジトリを監視し、それらのリポジトリでクローズされたマージリクエストを検出します。
- ソースファイルの識別: マージされた MR の一部として en-US ソースフォルダーに変更があった場合、ツールはそれを識別し、GitLab API からコンテンツを抽出します。
- 翻訳リクエスト: 抽出されると、翻訳が必要として識別されたファイルの Argo リクエストを自動的に作成します。
- ベンダーパイプライン: Argo は GitLab のローカライゼーション仕様に基づいた設定済みのベンダーインテグレーションを通じて翻訳ワークフローをオーケストレーションします。
- GitLab への翻訳済みファイルのインテグレーション: 翻訳が完了して Argo で利用可能になると、翻訳済みファイルが自動的に GitLab にコミットバックされます。
- 検証、レビュー、マージ: ローカライゼーションエンジニアが翻訳済みファイルを含む Argo のコミットをレビューし、承認してリポジトリにマージバックします。
セクション 2: デプロイアーキテクチャ
- インテグレーションツールは GitLab リポジトリにあり、GitLab の CI/CD パイプラインを使用して Docker ファイルコンテナにビルドされます。
- その後、Docker コンテナは Runway でデプロイされます。
- Runway は現時点で PostgreSQL をサポートしていないため、Google Cloud 上のデータベースサーバーに接続します。
セクション 3: ターゲットリポジトリ
現時点では、このツールは tech-docs と marketing 配下のいくつかのパブリックプロジェクトのみでの使用を想定しています。完全なリストは以下のとおりです:
マーケティング向け
| リポジトリリンク | リポジトリコンテンツ | ブランチ仕様 |
|---|---|---|
| about-gitlab-com | コンテンツ | 翻訳ブランチを使用 |
Tech-docs 向け
最初は tech-docs リポジトリのフォークを使用します。これには https://gitlab.com/gitlab-com/localization/tech-docs-forked-projects にあるすべてのテストおよびプロダクションリポジトリが含まれています。
承認後、近い将来に翻訳ブランチを使用するように移行します。すべてのリポジトリのリストは以下のとおりです:
セクション 4: データベース設定
データベースには機密データは一切保存されないことを注記しておく必要があります。シークレット、トークン、または API キーはデータベースに保存されません。ターゲットリポジトリへの限定的なアクセス権を持つ別の GitLab アカウントを使用します。
データベースに保存されるデータ
- Webhook のボディコンテンツ全体。これには GitLab MR とそれが存在するリポジトリに関するあらゆる種類のメタデータが含まれます。すべてのデータはこちらで確認できます。
- Webhook が受信・処理された日時と、その処理に関するステータス。
- MR の識別子と互いの関係(どの翻訳 MR がどのオリジナル MR に紐付いているか)。
データベースへの将来的な更新の可能性
- イベントに依存せずにアプリケーションが定期的なチェックを行うカデンスベースの翻訳にツールを拡張する可能性があり、それにより保存されるイベント数が増加します。
- 現在、エンジニアがターゲットリポジトリにマージする前に MR を確認しています。マージ自動化を拡張する機能をツールに追加する場合、成功/失敗のトラブルシューティングのためにより多くのログ情報を含める可能性があります。
注: フェーズ 1(以下参照)でデータベースに保存されたデータは、インフラが GitLab 配下の フェーズ 2(以下参照)に移行された時点で Spartan の環境から削除されます。
設計と実装の詳細
Spartan Software, Inc.(“Spartan”)は、リクエスト管理システム Argo と通信するための仲介ツールとして機能する Java アプリケーションの構築を支援しました。
要約すると、このツールの機能は以下のとおりです:
- インテグレーションツールは特定の GitLab プロジェクトまたはリポジトリを継続的に監視します。
- 監視対象プロジェクトでマージリクエストがクローズされると、インテグレーションツールは GitLab API からマージリクエストデータを受信し、en-US ソース言語ファイルのリストを識別するために抽出します。
- ツールは翻訳が必要なファイルの Argo リクエストを作成します。
- Argo は GitLab が割り当てた翻訳ベンダーとの間で翻訳を管理します。
- リクエストに関連するファイルの翻訳が完了すると、Argo はファイルを GitLab にコミットバックしようとします。
- エンジニアが Argo によって作成されたマージリクエストのコミットをレビューし、承認してファイルをリポジトリにマージします。
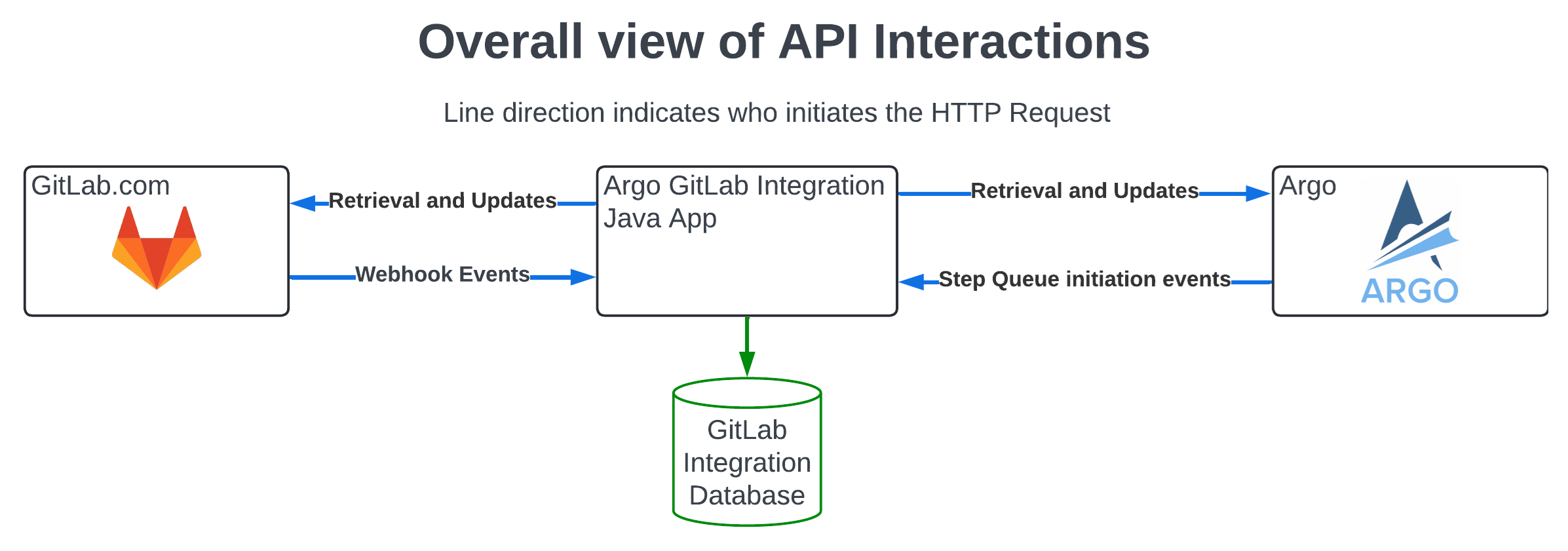 API インタラクションの全体図
API インタラクションの全体図
アクションの範囲
- ブランチおよび MR を含むリポジトリのコンテンツの読み取り
- 新しいブランチの作成と、作成した既存ブランチへの新しいコミットの追加
- 新しいコミットの作成
- リポジトリから自身または他のリポジトリへの MR の作成
前述のとおり、このツールには限定的なアクセス権を持つ別の GitLab アカウントのみが関連付けられます。ユーザートークンは、限定的な有効期限とともに以下の権限のみで作成されます:
- api
- read_repository
- write_repository
ユーザーの認証方法
GitLab の Webhook については、このユーザーのアクセストークンを認証に使用します。
Argo については、同じインスタンスまたはファイアウォール内でホストすることで外部アクセスを防ぎ、インテグレーションを保護しています。これに加えて、現在 Argo ↔ GitLab インテグレーションの認証実装が進行中です。これには、GitLab インテグレーションと通信する際に Argo もトークンを使用するように拡張すること、および GitLab インテグレーションもそのトークンを使用するように拡張することが必要です。
イベントのライフサイクル
アプリケーションはイベント駆動型です。GitLab または Argo がアプリケーションに HTTP リクエストを送信するまで、アプリケーションは休眠状態にあります。その後アプリケーションはイベントを処理し、時に非常に複雑な操作を実行します。
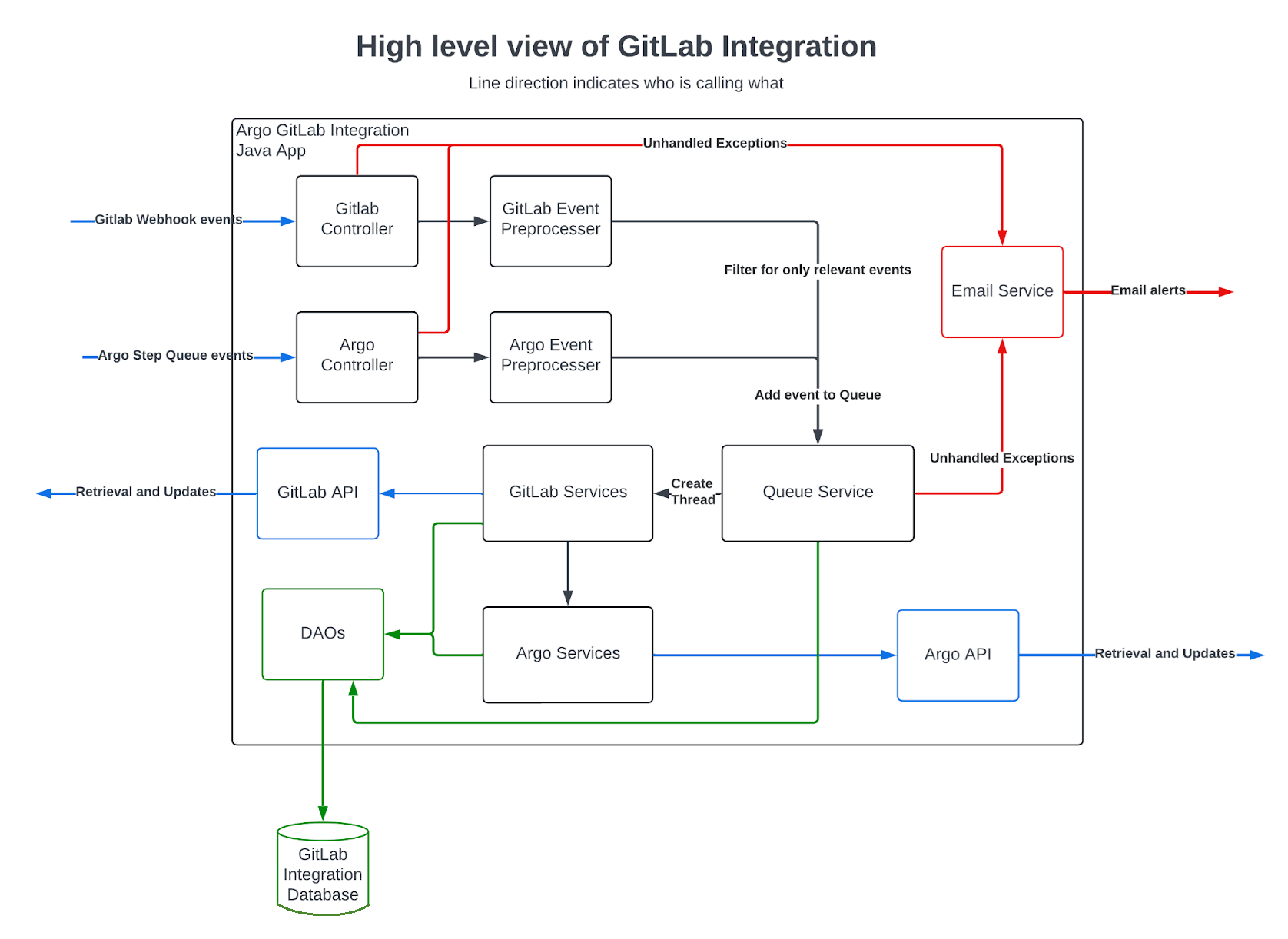 ハイレベルアーキテクチャ
ハイレベルアーキテクチャ
イベントの前処理
キューに投入する前に、大量の HTTP リクエストに対するクイックチェックと処理を行います。
- Argo または GitLab イベントはそれぞれ
ArgoControllerまたはGitLabControllerに受信され、認証がチェックされた後、変更なしで次のサービスに渡されます。- 目的: 内部サービスとのインターフェース、およびリクエストの認証を可能にするシンプルなエンドポイント。
ArgoControllerについて: Argo からイベントを受信します。ソース言語ファイルの翻訳が完了し Argo で準備ができると、Argo は何が完了したかを GitLab インテグレーションに通知する呼び出しを行い、ArgoControllerを通じてそれを受信します。そこから GitLab インテグレーションは翻訳済みファイルを取得し、必要に応じてブランチと MR を作成して、そのブランチにコミットします。
- (GitLab イベント)
GitLabWebhookServiceはイベントを受け取り、データを変換して関連性があるかどうかを確認します。チェックで関連性があると判断された場合、キューに追加されます。- 目的: 不要なイベントのほとんどをフィルタリングし、データをより管理しやすい形式に変換し、イベントを即座に処理し、キューとデータベースが不要なイベントで埋まるのを防ぎます。
- (Argo イベント)
ArgoStepServiceはイベントを受け取り、単純にキューに追加します。- 目的: すべての Argo イベントは関連性があるため、現時点では特に用途はありませんが、将来 GitLab イベントのように前処理が必要になった場合に、便利な場所として機能します。
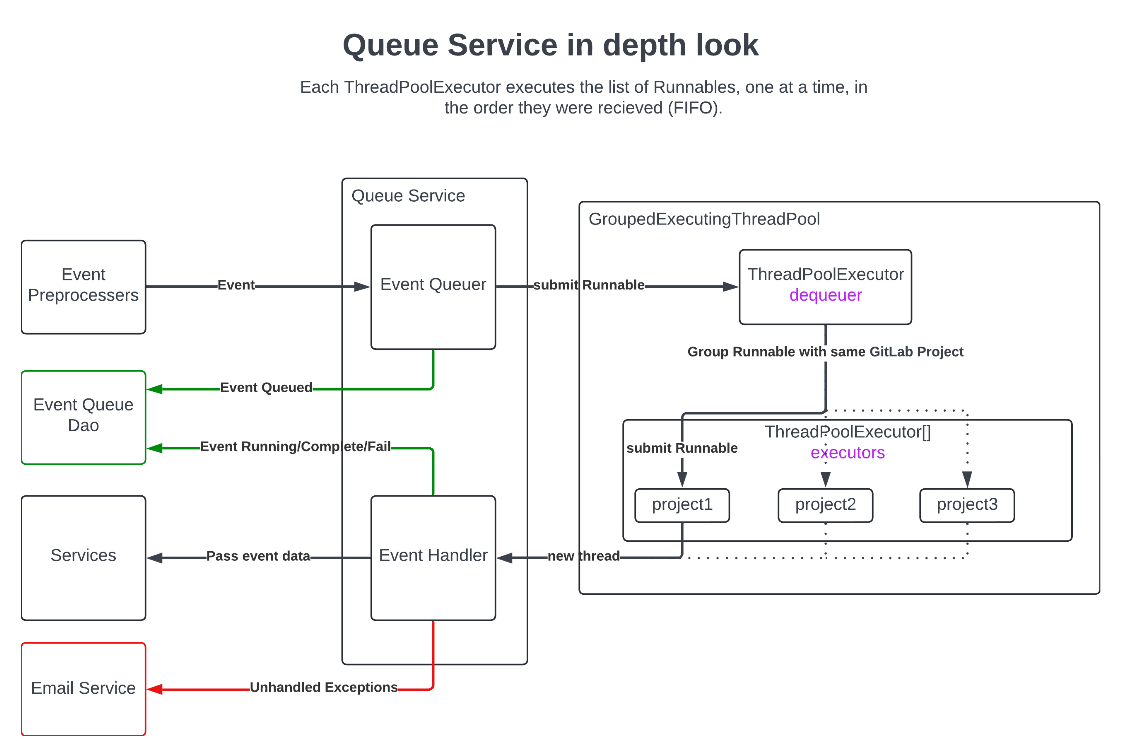 キューサービスの詳細図
キューサービスの詳細図
ArgoController
ArgoController は Argo からイベントを受信します。ソース言語ファイルの翻訳が完了し Argo で準備ができると、Argo は何が完了したかを GitLab インテグレーションに通知する呼び出しを行い、ArgoController を通じてそれを受信します。そこから GitLab インテグレーションは翻訳済みファイルを取得し、必要に応じてブランチと MR を作成して、そのブランチにコミットします。将来の開発では、翻訳 MR がマージされたかどうかを Argo 内で表示するためのクエリなど、Argo がさまざまな呼び出しを行う可能性があります。そのような可能性のある将来の呼び出しは ArgoController に追加されます。
イベントのキューイング
QueueServiceImpl は、プロジェクト固有の FIFO(First-In-First-Out)順序を維持しながら並行処理を処理する、高度なイベントキューイングシステムを実装しています。このシステムは HTTP リクエスト内での初期の前処理後にイベントを処理し、データベースへの永続化とメモリ内キューイングの両方を管理します。
イベントの受信と保存
QueueService でイベントが受信されると:
- イベントデータはログ記録と再試行機能のためにデータベースに保存されます。
EventRunnableオブジェクトが作成され、イベントデータとその実行関数の両方が含まれます。関数は新しいスレッドで実行され、提供されたイベントデータを使用します。EventRunnableはGroupedExecutingThreadPoolに送信されます。
キューイングの実装
システムは 2 レベルのスレッドアプローチを使用しています:
- プライマリ ThreadPoolExecutors(
dequeuer): 初期の FIFO 順序ですべての受信EventRunnableを受け取ります。 - セカンダリ ThreadPoolExecutors(
executors): 各エントリが特定の GitLab プロジェクトのイベントを処理するためだけに使用されるエクゼキューターの配列。
並行処理ルール
- 同一プロジェクト内のイベントは FIFO(First-In-First-Out)順序で同期的に処理する必要があります。
- 異なるプロジェクトは最大 5 プロジェクトまで並行して処理できます。
- 次のキューにあるイベントが(5 プロジェクト制限により)処理できないプロジェクトのものである場合、プロジェクトに関係なくその後のすべてのイベントがブロックされます。
- ブロックされたイベントより前に到着したイベントは正常に処理が継続されます。
イベントステータストラッキング
システムはデータベースで以下のステートを使ってイベントステータスを管理します:
- Queued: イベント受信時の初期ステート
- Running: イベントが現在処理中
- Completed: イベントが正常に処理完了
- Failed: イベント処理中にエラーが発生
実行プロセス
- イベントスレッドは
QueueService#handleEventメソッドで実行を開始します。 - イベントタイプに基づいて、適切なサービスにディスパッチされます:
- GitLab サービス
- Argo サービス
目的とメリット
- 同期処理: 競合状態を防ぐためにプロジェクト内での FIFO 順序を維持します。
- 並行最適化: スループット向上のために異なるプロジェクト間での並行処理を許可します。
- リソース管理: リソースの過剰使用と API レート制限の問題を防ぐために並行プロジェクト処理を制限します。
- 信頼性: データベースへの永続化によりイベントのトラッキングと再試行が可能です。
- スケーラビリティ: ThreadPool アーキテクチャにより効率的なスレッド管理と実行が可能です。
マージリクエストのクローズ
GitLabMergeRequestService#handleClosedEvent 監視対象プロジェクトで MR がクローズされるたびに、このイベントが呼び出されます。
- GitLab API からマージリクエストデータを取得します。
- 目的: 必要なデータのすべてがイベントで提供されるわけではありません。また、イベントが呼び出された後に変更があった場合に最新データを取得します。
- 翻訳が必要なファイルのリストを取得します。
- これは翻訳 MR と MR で変更されたファイルの内容によって異なります。
- それらのファイルの内容を取得します。
- それらのファイルの Argo リクエストを作成します。
- カード(以下の定義参照)を追加してリクエスト内のアセットを割り当てます。
- 目的: リンクなどの追加データを提供し、スケジュールを起動準備済みまたは自動起動できる状態に整理します。
- 例外が発生した場合、不完全にならないよう Argo リクエストを削除します。
クイックノート:
Argo リクエストにはどのようなデータが含まれていますか?
例はこちらで確認できます。 リクエストには GitLab、接続されている TMS、およびコメントや担当者などのリクエストに取り組んだ人に関するデータが含まれます。GitLab インテグレーションから以下の情報がリクエストに含まれます:
- プロジェクト ID とパス
- マージリクエスト ID、タイトル、URL
- コンポーネント
- 翻訳される予定のファイルの名前と内容
「カード」とは何ですか?
リクエストには単一の値を持つフィールドを含めることができます。例えば「プロジェクト ID」などです。カードはデータを保持するだけの小さなテーブル行のようなものです。各カードには単一の値を持つフィールドを含めることができますが、複数のカードをリクエストに追加できます。それらの値はリクエスト内でテーブルに集計され、各行がカード、各列が 1 つのフィールドになります。カードは GitLab インテグレーションで使用され、リクエスト閲覧者がリクエスト画面から MR に移動しやすくするために、すべての関連 URL を一覧表示します。
Argo から GitLab へのコミット
GitLabMergeRequestService#handleCommitToTranslationMREvent 対象ファイルの翻訳が完了するたびに、Argo はファイルを GitLab にコミットバックしようとします。これは 1 ファイルずつ実行されます。
- Argo からリクエストとプランおよびその内容に関する詳細を取得します。
- GitLab からプロジェクトに関する詳細を取得します。
- 翻訳 YAML を取得し、この YAML に基づいてターゲットファイルの配置場所を決定します。
- Argo 翻訳 YAML(フォルダー場所に関する情報を持つ設定ファイル)でソースファイルのファイルパスを検索し、ターゲット言語に再マッピングします。
- ファイルとその内容を翻訳 MR にコミットします。
- ステップが完了したことを Argo に更新します。
デプロイフェーズ
Argo ↔ GitLab インテグレーションのデプロイは2 つのフェーズで処理されます。
フェーズ 1 - Spartan
最初のフェーズでは、アプリケーションの実行とテストのプロセスを迅速化するために、Spartan の環境にアプリケーションをデプロイします。これは最終的にアプリケーションを GitLab の環境にデプロイできるようになるまでの一時的なステップです。
アプリケーションは GitLab の CI/CD パイプラインを使用してビルドされます。アーティファクトはダウンロードされ、Spartan Software のエンジニアによってデプロイされます。
アプリケーションは AWS EC2 上で動作する Rocky Linux 8 OS にデプロイされています。Java 17 と Nginx プロキシで実行されます。Argo アプリケーションと同じインスタンスで実行されます。nginx アプリケーションは、GitLab Webhook イベントのエンドポイントのみがアプリケーションにアクセスできるように設定されています。その他のエンドポイントは localhost 経由でボックス内からのみアクセスできます。データベースは Amazon RDS でホストされており、接続が許可されているのは特定の EC2 インスタンスと VPN 上のエンジニアのみです。この設定のプロダクション版とテスト版の両方があります。つまり、データベースと EC2 インスタンスがそれぞれ 2 つありますが、プロダクションとテストは互いに通信できません。
フェーズ 2 - GitLab
- パイプライン:
- GitLab 環境の準備ができると、同じリポジトリのパイプラインから同じようにビルドが行われます。
- ただし、パイプラインは実行可能 Java(.jar)をビルドし、さらに Java 17 と Nginx をプロキシとして含む Docker コンテナイメージをビルドするために実行されます。
- Google Cloud:
- Argo-GitLab インテグレーションサービスのデータベース部分を設定するには、Google Cloud Sandbox にデータベースサービスをインストールしてデプロイし、Cloud SQL を使用して Runway から接続できます。
- 詳細な実装内容はこちらとこちらに記載されています。
- Runway:
- Runway オンボーディング(オンボーディングの詳細はこちらとこちらに記載)に従って、Docker イメージから Runway でデプロイされます。
- Runway サービスは Runway の GCP プロジェクト外でプライベート IP とプライベートサービスコネクトを使用して CloudSQL インスタンスに接続します。
代替ソリューション
簡単な解決策の 1 つは、Google Cloud に Linux サーバーを構築し、その上に Java アプリケーションと残りのデータベース設定をインストールすることです。これはクラウドまたは GitLab 内のどこかで行われる従来の VM ベースのデプロイと呼ぶことができます:
- Java アプリケーションとデータベースを使用した Google Cloud VM の迅速な初期セットアップ
- 最小限の初期設定が必要
- 初期開発オーバーヘッドが低い
ただし、いくつかの重大な制限があります:
- デプロイの課題:
- 実行可能 JAR の再ビルドを必要とする手動デプロイプロセス
- ゼロダウンタイムデプロイ機能の欠如
- 自動ロールバックメカニズムがない
- 環境間の設定ドリフトのリスク
- 運用上の懸念事項:
- デプロイ中のパイプライン中断
- Argo との通信中のデータ損失の可能性
- 限られたスケーラビリティオプション
- より高いメンテナンスオーバーヘッド
- 監視と復旧:
- 限られた組み込み監視機能
- 複雑なディザスタリカバリ手順
- 自動フェイルオーバーオプションがない
c955a93f)