GitLab アプリケーションへのメッセージングレイヤーの導入
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| proposed | ankitbhatnagar
arun.sori | andrewn | dennis | group platform insights | 2025-02-26 |
概要
このドキュメントでは、GitLab スケールでのデータメッセージングとキューイングのニーズをサポートするための メッセージングレイヤー の採用・使用に関する設計、アーキテクチャ、およびロールアウトロードマップを提案します。
Data Insights Platform の構築や Project Siphon などの最近のイニシアチブから、大量のデータを取り込み・処理するためにテクノロジースタック内にスケーラブルで信頼性の高いキューイングシステムが必要であることが明らかになっています。この点に関する複数の議論 を経て、選択肢を NATS の使用 に絞り込みました。その理由はこのドキュメントの後半で説明します。
動機
テックスタック内にスケーラブルなメッセージングレイヤーを持つ主な動機は、特に分析データや監視データなど、大量のデータを取り込む能力を構築することです。データをデータベースに直接永続化することは可能ですが、スケーラビリティの課題が伴います。例えば、ClickHouse にデータを取り込む場合、そのアーキテクチャ上、多数の小さな書き込みを取り込むよりも、少数の書き込みで大きなバッチのデータを取り込む方がパフォーマンスが大幅に向上します。この点に関する過去の経験も参考にしてください。
もう 1 つの主要な要件は、データがデータベースに格納される前に受信データを 処理 できることです。最低限、以下の操作を実行できる必要があります:
- 他のシステムやデータカタログのメタデータで受信データを動的にエンリッチする
- 取り込まれたデータに機密情報が含まれていないことを確認し、必要に応じてデータを匿名化・仮名化・削除する
- 特定の(論理的な)条件が満たされる間、メインストレージ外でデータをバッチ処理する
- 取り込み・処理済みデータを複数の宛先にファンアウトする
アーキテクチャの観点から、永続ストアの上流に データバッファ があると、取り込まれたデータの大きなスパイクを吸収することで下流のリソース負荷を軽減するのに役立ちます。これは、データの生成・収集量が増えるにつれて非常に頻繁に発生する可能性があります。このようなアブストラクションを構築することのその他の重要なメリットについては後述します。
将来を見据えたユースケースを考慮すると、GitLab インスタンスのすべてのデプロイメントモデル(GitLab.com、Cells、Dedicated またはセルフマネージド)において、このようなシステムを 常に利用可能 にする必要があります。これにより、製品全体で生成されるデータストリームの処理方法を統一できます。このような大規模なデプロイメント環境では、信頼性、スケーラビリティを確保しつつ GitLab スケールでのパフォーマンスを発揮できるよう、そのようなシステムの配布・運用の複雑さを最小化することが重要です。
後述するように、NATS はその最小フットプリント、配布の容易さ、製品への組み込み可能性と必要に応じたクラスターへのスケールアウト能力において際立っています。
ゴール
- 最初のアダプター(Siphon、Data Insights Platform)向けのスケーラブルで信頼性の高いデータキューイングインフラを確立する。
- メッセージングレイヤーに取り込まれたすべてのデータへの認証・認可されたアクセスを提供する。
- 開発者がメッセージングレイヤーと対話できるようにするための必要なドキュメントを提供する。
- 前述のユースケースを有効にするために、既存の GitLab インフラとメッセージングレイヤーの実装を統合する。
非ゴール
- まだすべてのキューイング・イベンティングニーズのための汎用イベントバスを構築することを目指さない。むしろ、このブループリントは将来の包括的なイベントバスの基盤を築くことを目的としており、将来より広範なアプリケーションやユースケースとの互換性を保つ設計上の決定を行います。
- メッセージングレイヤーのコンテキスト内でアプリケーション固有の実装詳細はカバーしない。
提案
この提案の核心は、テックスタック内に 基盤となるメッセージングコンポーネントを確立 し、GitLab インストールとうまく統合された必要なインフラを構築することです。
この最初のイテレーションでは、すべての GitLab サービスやアプリケーションがこのメッセージングレイヤーと直接対話することは期待しません。現時点で計画されている使用は以下の通りです:
Siphon が PostgreSQL レプリケーションイベントを ClickHouse に格納する前にバッファリングするため。
イベントインストルメンテーションレイヤーを通じて Snowplow インストルメント済みイベントを Data Insights Platform に送信するアプリケーション。これらのイベントは動的にエンリッチされ、ClickHouse と AWS S3 に格納されます。
将来を見据えて
前述のメッセージングレイヤーが一般公開されたら、製品内のより汎用的なイベントベースのデータプラットフォームのデータキューイングバックボーンとして位置づけることを目指します。その存在は、GitLab のさまざまなクロスプラットフォームデータ関連機能の信頼性とスケーラビリティを確保します。
GitLab 内にイベントベースのプラットフォームを構築するメリット
製品内に集中型イベントベースのデータプラットフォームを持つことは、GitLab の論理アーキテクチャとその長期的なスケールアップ能力の向上に役立ちます。このようなアーキテクチャを構築・採用し続けることで、以下の主要なメリットが得られます:
- GitLab 全体のデータプロデューサーとコンシューマー間の 疎結合 を実現し、互いに独立してスケールできるようにする。
- 参加するシステム間で 非同期通信パターン を促進し、増加するトラフィックに対するスケーラビリティを向上させる。
- 既存データの新しいコンシューマーを最小限の時間・労力で追加できる 拡張可能な アーキテクチャを実現する。
- 製品のさまざまな部分にわたる統合に有用なデータを共有するための 集中型の共通アーキテクチャ を提供する。これにより、時間をかけて重要なデータの単一の信頼できる情報源を構築し、製品データの一貫性をもたらす。
以下のディスカッションも、GitLab の現在のスケールでイベントベースの抽象化を構築することが重要な理由を説明しています:
なお、集中型データ共有プラットフォームの存在はインフラの他の部分(特にデータベース)のスケーラビリティと信頼性の懸念を軽減するのに役立ちますが、このようなシステムが論理アーキテクチャにとって価値があることを確保するために、クライアントの認可、データの効率的なルーティング、モノリスからの分離など、いくつかの他の懸念点も解消する必要があります。
特定されたユースケース
以下は、製品内の集中型データプラットフォームの存在から恩恵を受けるユースケースの詳細なセットです。
| チーム・領域 | ユースケース | 想定スケール |
|---|---|---|
| エンタープライズデータ・インフラ | Postgres からのデータの論理レプリケーション。 | 毎時約 100GB の新しいデータを Postgres から取り込む。Cells アーキテクチャにも対応する必要がある。 |
| Platform Insights | 大量の分析データをリアルタイムで取り込み・処理し、ClickHouse に永続化する。 | 製品利用データ: 毎秒 1200 イベント(1 日 1 億件)、毎時 ~15GB。インストルメンテーションの増加と顧客ドメインからのイベントレベルのデータ収集(1 日約 3 億件)の追求で 2.5 倍になる見込み。 |
| 機械学習 | ML モデルのトレーニング・テストデータセットを大規模に作成するために GitLab データからイベント・フィーチャーを抽出・処理する。 | |
| セキュリティ・コンプライアンス | GitLab データから監査イベントなどのイベントをほぼリアルタイムで抽出・アクション化する。 | 1 日あたりデータベースに保存される監査イベント数(ストリーミング専用の監査イベントを除く)- 1 日あたり約 60 万件のレコードが作成される(Postgres への負荷により監査イベントのカバレッジが停滞しており、これがイベントパイプラインに移行すると増加する可能性が高い) 1 日あたり生成されるストリーミング専用の監査イベント数(DB に保存される監査イベントを除く)- 1 日あたり約 3,500 万件のストリーミング専用イベントが生成される。 合計見積もりは 1 日あたり約 4,000 万件 となる。Kibana ダッシュボード(社内) を参照。 |
| 製品 | データ、イベント、タスクを非同期で処理するための汎用イベントプラットフォーム。Webhook をサービスとして使用した外部データの取り込み・処理。 | |
| 製品 | 分析データベース(ClickHouse)上にリアルタイム分析機能を実装する(主に Optimize チームが関与するが、他の製品チームも貢献する可能性がある)。 | データ量: PostgreSQL データベースで観測される量と同様か少ない。ClickHouse にレプリケート(Siphon)するテーブル数による。エンキューされたイベント数: CDC イベントをパッケージにバッチ処理するため、大幅に少なくなる。 |
| Plan | JIRA 競合戦略 |
検討した代替案
前述のユースケースの潜在的なソリューションとして、いくつかの人気のあるバックエンドがディスカッションを通じて検討されました。以下の比較マトリックスは、GitLab 内のメッセージングニーズに対するさまざまなバックエンドの評価に役立ちます。
なお、潜在的なソリューションを評価する際に、以下の 4 つのデプロイメントターゲット(GitLab 向け)を考慮しました:
- GitLab.com SaaS: マルチテナントインスタンス。
- GitLab Dedicated: インスタンスごとに専用リソースのシングルテナント。
- クラウド上のセルフマネージド: この環境では、GCP 環境は GCP リソースの使用を優先し、AWS 環境は AWS リソースの使用を優先するなど、デプロイメントの均質性を前提とします。
- オンプレミスのセルフマネージド: この環境では、顧客に代わって他の前提を立てないよう、すべての環境がエアギャップであることを前提とします。
| 評価軸 / ソリューション | Apache Kafka | RabbitMQ | Google PubSub | AWS Kinesis | NATS | 該当する評価軸での推奨ソリューション |
|---|---|---|---|---|---|---|
| 配布: システムのパッケージングと配布の複雑さの評価。 | JVM ベースのアプリケーションとして提供され、対象とするほぼすべての環境向けに事前パッケージ化されている。 スコア: 6/10 | 対象とするほぼすべての環境向けに事前パッケージ化されているが、Erlang をランタイムとしてサポートするため、Go や Java と比べて配布が複雑。 スコア: 5/10 | 外部管理のクラウドソリューションで、Google Cloud Project で利用可能。 スコア: 10/10 | 外部管理のクラウドソリューションで、Amazon Web Services で利用可能。GCP での .com SaaS ホスティングとの緊密な統合を考慮すると、GCP よりわずかに低い。 スコア: 9/10 | Golang で開発されたコンパイル済みの軽量なシングルバイナリとして提供される。NATS は GitLab インスタンスを実行するすべての環境にパッケージ化・デプロイ可能。 スコア: 8/10 | セルフホスティングの課題を考慮した場合、NATS またはクラウドマネージドサービス。 |
| 運用複雑性: 以下の環境でのこのソリューションの管理の考慮: GitLab.com SaaS(マルチテナント)。 GitLab Dedicated(シングルテナント)。 クラウド上のセルフマネージド(SM)。 オンプレミスのセルフマネージド(SM)。 | Kafka は一般的に運用が複雑になりがち。 .com SaaS: 非常に大きなストレージフットプリントで追加・サポートが複雑になる可能性あり。🔴 Dedicated: 追加・サポートが複雑になる可能性があるが、ストレージフットプリントは管理可能かもしれない。🟡 クラウド SM: 追加・サポートは容易なはずだが、小規模なリファレンスアーキテクチャでもコストが高い。過去のディスカッション [1]、[2] を参照。 オンプレミス SM: 環境内で既に利用可能でない限り、初期資本・運用コストが高い。🔴 スコア: 5/10 | RabbitMQ も一般的に運用が複雑になりがち。 .com SaaS: 大きなストレージフットプリントで追加・サポートが複雑になる可能性あり。🔴 Dedicated: 追加・サポートが複雑になる可能性があるが、ストレージフットプリントは管理可能なはず。🟡 クラウド SM: サポートの追加は容易だが、小規模なリファレンスアーキテクチャでもコストが高い。🔴 オンプレミス SM: 環境内で既に利用可能でない限り、初期資本・運用コストが高い。🔴 スコア: 4/10 | Google PubSub は外部管理のクラウドソリューションとしてほぼゼロの運用複雑性。 .com SaaS: 追加・サポートが容易なはず。🟢 Dedicated: GCP で Dedicated 環境を構築する必要がある場合、追加・サポートが容易なはず。🟡 クラウド SM: 追加・サポートが容易なはず。🟢 オンプレミス SM: エアギャップ環境を前提として使用の可能性を除外。🔴 スコア: 8/10 | Amazon Kinesis は外部管理のクラウドソリューションとしてほぼゼロの運用複雑性。 .com SaaS: 追加・サポートが容易なはず。🟢 Dedicated: Dedicated 環境が既に AWS 上に存在することを考慮すると、追加・サポートが容易なはず。🟢 クラウド SM: 追加・サポートが容易なはず。🟢 オンプレミス SM: エアギャップ環境を前提として使用の可能性を除外。🔴 Dedicated がログ集約に Kinesis を使用しており、パフォーマンス問題が頻繁に発生していることも注目に値する。詳細はこれらの Issue を参照。 スコア: 7/10 | NATS はそのアーキテクチャにより、比較的運用が容易。 .com SaaS: 追加・サポートが容易なはずで、ストレージフットプリントはユースケースごとに管理可能。🟢 Dedicated: 追加・サポートが容易なはずで、ストレージフットプリントはユースケースごとに管理可能。🟢 クラウド SM: 主要なハイパークラウドではサポートされていないが、Synadia Cloud を通じて利用可能。🟡 オンプレミス SM: 追加・サポートが難しくない可能性があり、ストレージフットプリントはユースケースごとに管理可能。🟡 スコア: 8/10 | セルフホスティングの課題を考慮した場合、NATS またはクラウドマネージドサービス。オンプレミスのセルフマネージドインストールの大部分では、NATS が有力なソリューションとして際立っている。 |
| マネージドサービスとしての利用可能性: AWS、Google Cloud、Azure はマネージドサービスを提供しているか? | AWS マネージド Kafka (MSK) GCP マネージド Kafka サービス Azure メッセージングサービス または Canonical がサポートする Azure 上のホスト型 Kafka。 スコア: 10/10 | Amazon MQ CloudAMQP がサポートする Azure 上のホスト型 RabbitMQ。 スコア: 6/10 | マネージドサービス。 スコア: 10/10 | マネージドサービス。 スコア: 9/10 | 主要なハイパークラウドでは直接利用できないが、Synadia Cloud を通じたマネージドクラウドソリューションとして利用可能。 スコア: 6/10 | デプロイ先の環境に応じて Google PubSub または AWS Kinesis。 Synadia Cloud との統合は検討中。 |
| 一貫性・成熟度: Jepsen レポートや一貫性に関するその他の懸念事項? | Kafka の Jepsen テストが実施済みで、通常の分散システム以外の一貫性の懸念なし。 スコア: 9/10 | RabbitMQ の Jepsen テストが実施済みで、通常の分散システム以外の一貫性の懸念なし。 スコア: 9/10 | 懸念なし。 スコア: 10/10 | 懸念なし。 スコア: 10/10 | Jepsen テストはまだ実施されていないが、NATS はアダプター間でかなりの本番実績がある。 スコア: 8/10 | 検討したシステムに対する明らかなブロッカーはなし。 |
| クラウドネイティブサポート: Kubernetes でサービスを実行する複雑さは? | はい、Strimzi などの Kubernetes Operator を通じて一般的にデプロイされる。 スコア: 5/10 | はい、RabbitMQ チームが公式にサポートする Kubernetes オペレーターを通じてもデプロイ可能。 スコア: 5/10 | マネージドサービス、統合のみ。 スコア: 10/10 | マネージドサービス、統合のみ。 スコア: 10/10 | はい、Helm チャートを通じてデプロイ可能。 スコア: 9/10 | セルフホスティングの課題を考慮した場合、NATS またはクラウドマネージドサービス。 |
| ライセンス互換性: 検討中のシステムは GitLab とライセンス互換性があるか?ライセンス変更の可能性も考慮した。 | Kafka は Apache Version 2.0 でライセンスされており、オープンソースとして利用可能。 スコア: 10/10 | RabbitMQ は Apache License 2.0 と Mozilla Public License 2 のデュアルライセンス。自由に使用・変更できる。 スコア: 10/10 | マネージド、商業ライセンス。 スコア: 10/10 | マネージド、商業ライセンス。 スコア: 10/10 | NATS は Apache Version 2.0 でライセンスされている。元々 Synadia が開発し、CNCF に寄贈され、現在インキュベーション中。 スコア: 10/10 | 懸念なし。ほとんどのシステムは適切にライセンスされている。 |
| テクノロジースタックとの互換性: 技術スタックは私たちの経験と互換性があるか? | JVM ベースのシステム。 スコア: 2/10 | RabbitMQ はサポートされた Erlang バージョンを提供する任意のプラットフォームで実行可能(マルチコアノードとクラウドベースのデプロイメントから組み込みシステムまで)。 スコア: 1/10 | GitLab でのシステムや統合へのアプローチと特に互換性が高い。 スコア: 10/10 | GitLab でのシステムや統合へのアプローチと高い互換性がある。GCP 上での既存プレゼンスを考慮すると PubSub よりわずかに低い。 スコア: 9/10 | Golang で開発されており、テックスタックと合理的に互換性がある。シングルバイナリにコンパイルされるため、最小限の労力でデプロイメント環境全体のホストマシン上でネイティブに実行できる。 スコア: 9/10 | セルフホスティングの課題を考慮した場合、NATS またはクラウドマネージドサービス。 |
| クライアント・言語サポート: 特に Golang、Ruby、Python について、クライアント・言語サポートの質は? | librdkafka ラッパーを通じて他の言語もサポートされており、主要言語全体にわたって広くサポートされている。Golang: ✅ Ruby: ✅ Python: ✅ スコア: 9/10 | 言語を超えて広くサポートされている。 Golang: ✅ Ruby: ✅ Python: ✅ スコア: 10/10 | 公式サポートのクライアントを通じて主要言語をサポートしている。 Golang: ✅ Ruby: ✅ Python: ✅ スコア: 10/10 | Amazon Kinesis Data Streams からのデータ消費・処理プロセスを簡略化するために設計されたスタンドアロン Java ソフトウェアライブラリである Kinesis Client Library(KCL)を提供している。他の言語については言語固有の SDK や KCL ラッパーを使用する必要がある。 Golang: ✅ Ruby: ✅ Python: ✅ スコア: 8/10 | 言語を超えて広くサポートされている Golang: ✅ Ruby: ✅ Python: ✅ スコア: 10/10 | 明確な優勝者なし。検討したすべてのソリューションは、3 つの必要な言語に対してそれなりのクライアントサポートを持ち、他の言語へのサポートレベルはさまざまです。 |
| 依存関係: この依存関係を含めることでどの程度のサプライチェーンリスクが生じるか?このプロジェクトの依存関係グラフはどの程度大きく・深いか? | クラスター調整のために Zookeeper または KRaft が必要で、Kafka ブローカー自体の実行も必要。ZK はホストマシン上でネイティブに実行でき、KRaft は Kafka(ブローカー)プロセスの内部部分として実行される。 スコア: 5/10 | Erlang ランタイムのサポートが必要で、コードは Erlang で開発されている。依存関係グラフはほぼ未知の技術。 スコア: 4/10 | マネージドのクローズドソースシステム。このシステムの依存関係グラフを積極的に管理していない。 スコア: 9/10 | マネージドのクローズドソースシステム。このシステムの依存関係グラフを積極的に管理していない。 スコア: 9/10 | 外部依存関係のないシングル Golang バイナリで、ホストマシン上でネイティブに実行される。 スコア: 8/10 | セルフホスティングの課題を考慮した場合、NATS またはクラウドマネージドサービス。 |
| FIPS 準拠: FIPS 140-3 の対応状況や AWS GovCloud マネージドサービスのオプションを評価する。 | Kafka 自体は FIPS 準拠をサポートしていないが、検証済みの JDK/OpenSSL セットアップを使用してランタイムで設定できる。 スコア: 6/10 | Kafka と同様に、RabbitMQ は FIPS 準拠の OpenSSL ライブラリや依存関係で実行する必要がある。 スコア: 6/10 | はい、Google の FIPS 準拠の暗号化による暗黙的なサポート。 スコア: 10/10 | はい、デプロイメントは AWS FIPS エンドポイントの背後で保護する必要がある。 スコア: 9/10 | Go の暗号実装は FIPS に対応していないが、NATS デプロイメントは OpenSSL を使用した FIPS 準拠の TLS 実装を通じて保護できる。 GitLab のパートナーである Chainguard は NATS の FIPS イメージを提供している。 スコア: 6/10 | セルフホスティングの課題を考慮した場合、NATS またはクラウドマネージドサービス。 |
| エクスプロイトと CVE: 過去 2 年間でどれくらいの重大な CVE を経験したか? | ||||||
| コミュニティ採用: システムはどれくらい広く採用されているか?複数の組織からの貢献など。 | 広く採用されている。 スコア: 10/10 | 広く採用されている。 スコア: 9/10 | 広く採用されている。 スコア: 10/10 | 広く採用されている。 スコア: 10/10 | 広く採用されている。 スコア: 9/10 | 明確な優勝者なし。検討したすべてのソリューションは、ユーザーごとに異なる評価軸に応じてそれなりのフットプリントを持っています。 |
| 運用コスト: 特に私たちのスケールでシステムを採用・実行するコストはどれくらいか? 注: 使用したリファレンスアーキテクチャと基盤となるサイジングを含むコストとその内訳の詳細分析はこのドキュメントの後半を参照。 | NATS や RabbitMQ と比較して、Kafka はレプリケーションオーバーヘッドにより計算とストレージの両面でよりリソース集約的になりがち。ZK を使用する場合はより多くの計算ノードが必要で、KRaft の場合はブローカープロセスと同じ JVM で動作するためより多くの vCPU が必要。 スコア: 6/10 | RabbitMQ は確認メカニズムにより NATS よりも計算集約的で、よりトランザクション指向のストリーミングワークロードに適している。その他の運用コストは NATS と概ね同様。 スコア: 7/10 | データの転送コストが大きな割合を占めるマネージドソリューション。また、GCP では AWS よりも長期間データを保持するコストが高い。 スコア: 4/10 | データの転送コストが大きな割合を占めるマネージドソリューション。 スコア: 5/10 | 分析した中で最も計算コストが低く、ストレージのフットプリントも最小限。セルフホスティングの課題を無視できると仮定した場合、大きなオーバーヘッドを発生させることなくリファレンスアーキテクチャに合わせて水平スケール可能。 スコア: 9/10 | スケール時のコストを考慮した場合、クラウドのマネージドサービスはオーダーオブマグニチュードでコストが高いため、NATS が最小フットプリントと少ないオーバーヘッドで明らかに際立っている。 |
| 合計スコア | 83 | 76 | 111 | 105 | 100 | - |
| Apache Kafka | RabbitMQ | Google PubSub | AWS Kinesis | NATS | - |
コスト見積もりと分析
さまざまなシステムの比較可能な分析を確保するために、各分析システムにホストする必要があるデータ量についていくつかの前提を設けました。
例えば、.com SaaS から生成されるすべての Snowplow インストルメント済みデータを考慮すると、1 日あたり 500GB のイベントデータを生成すると推定されます。このデータを 1 週間保持する場合、どの時点でも基盤インフラ上にホストする必要があるデータが約 3.5TB 蓄積されます。データライフサイクルポリシーが適切に機能し、これが最大ストレージフットプリントになると仮定できます。
- 1 日あたりのデータ生成量: 500GB
- 保持期間: 7 日
- 最大格納データ: 500GB * 7 日 = 3.5TB
以下は、そのデータ量での各バックエンドの状況です。
| システム / コンポーネント | デプロイターゲット | 計算 | ストレージ | ネットワーク | サポート・運用 | 合計見積もり |
|---|---|---|---|---|---|---|
| Apache Kafka 3 ブローカーで構成される最もシンプルなアーキテクチャで見積もり。各ブローカーは 4 vCPU + 16GB RAM を使用し、それぞれに 1TB の標準永続ディスクを接続。 Zookeeper を Kafka ブローカーと同じ場所に配置するか、KRaft を使用することも想定。Zookeeper ノードをスタンドアロンでデプロイする場合、それらのノードのコストは追加になる。 使用するトピック・パーティションのレプリケーションは設定しないことも想定。HA のための追加レプリケーションはストレージフットプリントをレプリケーション係数 n 倍に増やす。 | .com SaaS | GCP n4-standard-4(4 vCPU と 16 GB RAM)@ $0.1895/時間。VM あたりの月額: $0.1895/時間 * 730 時間/月 = $138.34 3 VM 合計: 3 * $138.34 = $415.02。 | GCP 標準永続ディスク @ $0.04/GB/月。 1 TB ディスクあたりのコスト: 1,024 GB * $0.04/GB = $40.96 3 ディスク合計: 3 * $40.96 = $122.88。 | GCP クラスターのセットアップ方法によって、以下のネットワーク料金規則が適用される。 ゾーン内・ゾーン間のデータ転送コストが適用される場合がある。同じ Google Cloud リージョンの異なるゾーンにソースと宛先 VM がある場合、使用帯域幅 GiB あたり $0.01。 通信を効率的に保つために、サーバーとクライアントを同じリージョンに配置することを推奨。そうでない場合、使用された各 GiB 帯域幅にリージョン間転送コストが適用される。 | GCP 月額見積もり: $415.02(計算)+ $122.88(ストレージ)= $537.90 | |
AWS t3a.xlarge(4 vCPU と 16 GB RAM)@ $0.0832/時間。インスタンスあたりの月額: $0.0832/時間 * 730 時間/月 = $60.74 3 インスタンス合計: 3 * $60.74 = $182.22。 | AWS 汎用 SSD gp2 ボリューム @ $0.10/GB/月。1 TB ボリュームあたりのコスト: 1,024 GB * $0.10/GB = $102.40 3 ボリューム合計: 3 * $102.40 = $307.20。 | AWS 月額見積もり: $182.22(計算)+ $307.20(ストレージ)= $489.42 | ||||
| Dedicated | (上記と同じ) | (上記と同じ) | (上記と同じ) | |||
| クラウド SM | (上記と同じ) | (上記と同じ) | (上記と同じ) | |||
| オンプレミス SM | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | |||
| RabbitMQ | .com SaaS | |||||
| Dedicated | ||||||
| クラウド SM | ||||||
| オンプレミス SM | ||||||
| NATS 3 つの NATS サーバーで構成される最もシンプルなアーキテクチャで見積もり。各サーバーは 4 vCPU + 16GB RAM を使用し、それぞれに 1TB の標準永続ディスクを接続。他の依存関係は不要。 | .com SaaS | GCP n4-standard-4(4 vCPU と 16 GB RAM)@ $0.1895/時間VM あたりの月額: $0.1895/時間 * 730 時間/月 = $138.34 3 VM 合計: 3 * $138.34 = $415.02。 | GCP 標準永続ディスク @ $0.04/GB/月。 1 TB ディスクあたりのコスト: 1,024 GB * $0.04/GB = $40.96 3 ディスク合計: 3 * $40.96 = $122.88。 | GCP 月額見積もり: $415.02(計算)+ $122.88(ストレージ)= $537.90 | ||
AWS t3a.xlarge(4 vCPU と 16 GB RAM)@ $0.0832/時間。インスタンスあたりの月額: $0.0832/時間 * 730 時間/月 = $60.74 3 インスタンス合計: 3 * $60.74 = $182.22。 | AWS 汎用 SSD gp2 ボリューム @ $0.10/GB/月。1 TB ボリュームあたりのコスト: 1,024 GB * $0.10/GB = $102.40 3 ボリューム合計: 3 * $102.40 = $307.20。 | AWS 月額見積もり: $182.22(計算)+ $307.20(ストレージ)= $489.42 | ||||
| Dedicated | (上記と同じ) | (上記と同じ) | (上記と同じ) | |||
| クラウド SM | (上記と同じ) | (上記と同じ) | (上記と同じ) | |||
| オンプレミス SM | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | |||
| Google PubSub PubSub のコストには 3 つの主なコンポーネントがある: スループットコスト: メッセージ発行と配信のため。 データ転送コスト: クラウドゾーンまたはリージョン境界を越えるスループットに関連。 ストレージコスト。 また: ゾーンデータ転送料金なし。他のクラウド・プライベート DC からの発行時のインバウンドデータ転送料金不要。 | .com SaaS | Message Delivery Basic SKU @ $40/TiB。 | ストレージ @ $0.27/GiB/月。 | データ転送コストは VPC ネットワーク料金で見積もり。スタンダード帯域幅料金を使用して $0.045/GiB/月。 | 容量見積もりを踏まえると: スループット: 500GB*30*$0.04 = $600/月。 ストレージ: 3.5TB*1024*0.27 = $968/月。 配信: 500GB*30*3*$0.045 = $1800/月 月額見積もり: ~ $3400 | |
| Dedicated | (上記と同じ) | (上記と同じ) | (上記と同じ) | (上記と同じ) | ||
| クラウド SM | (上記と同じ) | (上記と同じ) | (上記と同じ) | (上記と同じ) | ||
| オンプレミス SM | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | ||
| Amazon Kinesis | .com SaaS | シャード: $0.015/シャード/時間 | ストレージ(24 時間超): $0.023/GB/月。 | インバウンドデータ: $0.08/GB アウトバウンドデータ: $0.04/GB | 容量見積もりを踏まえると: 取り込み: 500GB*30*$0.08 = $1200/月。 配信: 500GB*30*$0.04 = $1800/月 ストレージ: 3.5TB*1024*$0.023 = $82/月 シャード: 500GB == 5.8MB/s == 6 6*24*30*$0.015 = $65 月額見積もり: ~ $3200 | |
| Dedicated | (上記と同じ) | (上記と同じ) | (上記と同じ) | (上記と同じ) | ||
| クラウド SM | (上記と同じ) | (上記と同じ) | (上記と同じ) | (上記と同じ) | ||
| オンプレミス SM | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 | リファレンスアーキテクチャで見積もり。 |
GitLab リファレンスアーキテクチャに関するコスト分析
詳細については: https://docs.gitlab.com/administration/reference_architectures/ を参照してください。
リソースを見積もる前に、異なるリファレンスアーキテクチャ全体でのメッセージトラフィックの指標が必要です:
- メッセージ量: 毎秒のメッセージ数の見積もり。
- メッセージサイズ: バイト単位のメッセージペイロードサイズの見積もり。
- パブリッシャー・コンシューマーの数
- 永続化・ストレージ: どの程度のデータをどの期間保存・保持する必要があるか。
| リファレンスアーキテクチャ / システム | Kafka | RabbitMQ | PubSub | Kinesis | NATS |
|---|---|---|---|---|---|
| 概要、サイジング制約。 | NATS や RabbitMQ と比較して、Kafka はレプリケーションオーバーヘッドにより計算とストレージの両面でよりリソース集約的になりがち。ZK を使用する場合はより多くの計算ノードが必要で、KRaft の場合はブローカープロセスと同じ JVM で動作するためより多くの vCPU が必要。 | RabbitMQ は確認メカニズムにより NATS より計算集約的で、より多くのトランザクション指向のストリーミングワークロードに適している。 | 見積もりコスト: メッセージ取り込み: $40/TB ($0.04/GB) メッセージ配信: $40/TB ストレージ保持: $0.27/GB/月 データ転送: 標準 GCP エグレス料金。 | 見積もりコスト: シャード(計算): $0.015/シャード/時間 取り込み(書き込み): $0.036/百万レコード データ保持: $0.02/GB/日 データ転送: 標準 AWS エグレス料金。 | トラフィック見積もりでサイジングした単純な 3 ノードクラスターで十分なはず。 |
| スモール(~2,000 ユーザー) | NATS と概ね同様。 | サイジング: 毎秒 5,000 メッセージ。 取り込みコスト: $520 配信コスト: $520 ストレージコスト: $2,700 月額見積もり: 最低 $3,700。 | サイジング: 毎秒 5,000 メッセージ、3 シャードが必要。 シャードコスト: $32.40 取り込みコスト: $3.60 ストレージコスト: $6,000 月額見積もり: 最低 $6,000 | サイジング: 4vCPU、8GB RAM、100GB SSD、合計 1TB データ転送。 インスタンス数: 3 | |
AWS t3.xlarge @ $0.16/時間 = $120/月。100 GB EBS gp3 SSD = $10/月。 帯域幅: 1TB @ $0.09/GB = $90 月額見積もり: 最低 $480。 | |||||
GCP e2-standard-4 = $108/月。永続 SSD(100GB)= ~$17/月。 帯域幅: 1TB @ $0.08/GB = $80 月額見積もり: 最低 $450。 | |||||
| ミディアム(~5,000 ユーザー) | NATS と概ね同様。 | サイジング: 毎秒 10,000 メッセージ。 取り込みコスト: $1,040 配信コスト: $1,040 ストレージコスト: $2,700 月額見積もり: 最低 $4,700。 | サイジング: 毎秒 10,000 メッセージ、5 シャードが必要。 シャードコスト: $54 取り込みコスト: $7.20 ストレージコスト: $6,000 月額見積もり: 最低 $6,000 | サイジング: 8vCPU、16GB RAM、100GB SSD、合計 2TB データ転送。 インスタンス数: 3 | |
AWS m6i.2xlarge @ $0.38/時間 = $280/月。100 GB EBS gp3 SSD = $10/月。 帯域幅: 2TB @ $0.09/GB = $180 月額見積もり: $1,050 | |||||
GCP n2-standard-8= $240/月。永続 SSD(100GB)= ~$17/月 帯域幅: 2TB @ $0.08/GB = $160 月額見積もり: 最低 $940。 | |||||
| ラージ(~10,000 ユーザー) | NATS と概ね同様。 | サイジング: 毎秒 50,000 メッセージ。 取り込みコスト: $5,200 配信コスト: $5,200 ストレージコスト: $2,700 月額見積もり: 最低 $13,000。 | サイジング: 毎秒 50,000 メッセージ、10 シャードが必要。 シャードコスト: $110 取り込みコスト: $36 ストレージコスト: $6,000 月額見積もり: 最低 $6,200 | サイジング: 8vCPU、32GB RAM、500GB SSD、合計 5TB データ転送。 インスタンス数: 5 | |
AWS m6i.4xlarge @ $0.76/時間 = $560/月。500 GB EBS gp3 SSD = $50/月。 帯域幅: 5TB @ $0.09/GB = $450 月額見積もり: $3,500 | |||||
GCP n2-standard-16= $480/月。永続 SSD(500GB)= ~$85/月。 帯域幅 5TB @ $0.08/GB = $400 月額見積もり: 最低 $3,225。 | |||||
| エクストララージ(~25,000 ユーザー) | NATS と概ね同様。 | サイジング: 毎秒 250,000 メッセージ。 取り込みコスト: $25,000 配信コスト: $25,000 ストレージコスト: $2,700 月額見積もり: 最低 $52,700。 | サイジング: 毎秒 250,000 メッセージ、25 シャードが必要。 シャードコスト: $500 取り込みコスト: $360 ストレージコスト: $6,000 月額見積もり: 最低 $7,000 | サイジング: 16vCPU、64GB RAM、1TB SSD、合計 10TB データ転送 インスタンス数: 5 以上 | |
AWS c6i.8xlarge @ $1.53/時間 = $1,120/月。1TB EBS gp3 SSD = $100/月。 帯域幅: 10TB @ $0.09/GB = $900 月額見積もり: 最低 $7,000。 | |||||
GCP n2-highcpu-32= $1,000/月。永続 SSD(1TB)= ~$130/月。 帯域幅: 10TB @ $0.08/GB = $800 月額見積もり: 最低 $6,450。 |
機能とコストの観点からの結論
- これらのバックエンドを分析して注目すべき重要な要素は、特に GitLab をクラウドネイティブデプロイメントに移行する中で、セルフマネージドなどの非ホスト環境でそれらを実行したり利用可能にすることを期待したりする際の、高い運用・配布・サポートオーバーヘッドです。
- すべてを考慮すると、NATS はシングル Go バイナリとして配布され、外部依存関係ゼロでユーザーサービス・アプリケーションに隣接してインストールできることから、分析したすべてのバックエンドの中で 最もコストが低い ように見えます。必要に応じて、実行するリファレンスアーキテクチャに応じて複数のサーバー・クラスターにシャード・スケールアウトできます。
- マネージドクラウドソリューションを支持する唯一の要因は、関連するサポートコストですが、その運用コストは特に使用量・採用量が私たちのスケールで増えるにつれて、得られるメリットを上回るように見えます。
このドキュメントの残りは、GitLab インスタンス内のメッセージングソリューションとして NATS を使用する提案の構築に焦点を当てています。
コンポーネント
- 1 つ以上の JetStream 有効化 NATS サーバー
- デプロイされた各 NATS サーバー向けの永続ボリューム(SSD が望ましい)
- 分散認証コールアウトサーバー(長期的のみ): 認証・認可については、当初は NATS 内のハードコードされたロールとクレデンシャル(集中型)を活用することから始めますが、長期的には受信トラフィックの認証に分散型サーバーサイド認証コールアウト実装を使用することを想定しています。
デプロイメント
NATS をすべての GitLab インストールで利用可能にすることを意図して、以下のデプロイメントモデルに必要なサポートを構築することを目指します:
| デプロイメントタイプ | 提案されるトポロジー |
|---|---|
| GDK | インストールにローカルで実行 |
| .com | 1 つ以上の専用クラスター |
| Cells | Cells トポロジーに応じた 1 つ以上のクラスター |
| Dedicated | インスタンスごとに 1 つの専用クラスター |
| セルフマネージド | 配布・インスタンスサイジングに応じたスタンドアロンクラスター |
テナンシー
すべてのデプロイメントタイプについて、特定の NATS クラスターはマルチテナント であることを想定します。つまり、デプロイメント上でホストされている複数のユーザー・サービスが、メッセージングニーズに対して同じ基盤 NATS インフラを共有します。
ロールアウトロードマップ
| 成果物 | タイムライン |
|---|---|
| プレステージング・テスト | FY26Q1 |
| ステージング | TBD |
| 本番: .com | TBD |
| Dedicated への段階的ロールアウト | TBD |
| セルフマネージドへの段階的ロールアウト | TBD |
設計と実装
アーキテクチャ
以下のダイアグラムは、専用の永続ボリュームを持つ StatefulSet としてデプロイされた単純な 3 ノード NATS クラスターを示しています。アプリケーションはサービスを以下の方法で検出できます:
- ヘッドレスサービスを使用する、または
nats.default.svc.cluster.local
- Pod に直接アドレスする
nats-0.nats.default.svc.cluster.local
nats-1.nats.default.svc.cluster.local
nats-2.nats.default.svc.cluster.local
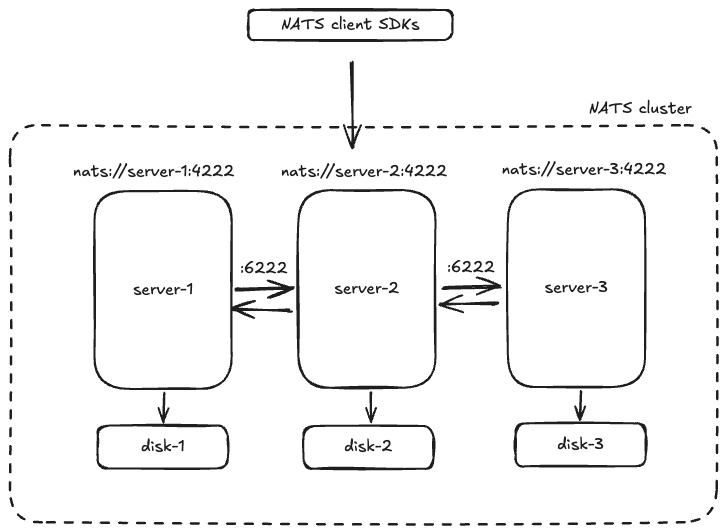
セットアップ
- データ量と保持期間に応じた N ノードクラスターのセットアップ。
- NATS JetStream を通じたデータ永続化の有効化。
- 必要に応じてサブジェクトのストリームレプリケーションの設定。
接続性
NATS はプレーンテキストと TLS 接続の両方をサポートしています。すべての受信トラフィックの認証に役立てるために、TLS 有効化接続を使用することを意図しています。
NATS サービスへのアクセスは内部ネットワーククライアントのみに利用可能です。外部クライアントは NATS サービスに接続できません。
したがって外部ロードバランシングは不要であり、強く推奨されません。特定のクラスター内の各 NATS サーバーは、ロードバランシングをすべて NATS 自体に委ねることで個別に到達可能でなければなりません。
Cells ベースのインストールの場合、必要に応じてクラスターを接続するために NATS Gateways の使用を活用できますが、アプリケーションの大部分について各 Cell が独立してサービス提供できることを期待しています。NATS Gateways が将来的に相互接続に役立つと考えていますが、この機能はこのイテレーションのブループリントでは スコープ外 です。
トポロジー
すべてのデプロイメントタイプについて、NATS は Redis や Sidekiq と同様に リージョンローカルのみ でデプロイされ、Postgres のように Geo レプリケーションされません。NATS クラスターをメッシュ化する機能は可能ですが、この機能はこのイテレーションのブループリントでは スコープ外 です。
GitLab.comについては、以下の潜在的なオーバーヘッドが適切に管理できるという前提で、Kubernetes 上でクラウドネイティブに NATS クラスターをセットアップ・実行することを意図しています:- Kubernetes 内でのステートフルワークロードの実行。
- Kubernetes サービス内でのトラフィックルーティングのパフォーマンスオーバーヘッド。
- Kubernetes サービストポロジーを通じたトラフィックのロードバランシング。
運用の観点から、新しいサービスを Kubernetes ベースで構築することを優先しているため、同じ設定を GitLab.com、Dedicated、Cells、およびセルフマネージドに使用することも容易になります。
クラウドネイティブに実行することがオーバーヘッドをもたらす場合、基盤ハードウェアの利用率向上と運用複雑性の軽減のために、同じ VPC・ネットワーク境界内の VM 上で NATS を直接実行することも可能です。
両方のデプロイメントモデルもプロトタイプを作成済みです:
データ永続化
- NATS はすべての取り込みデータをメモリに保存するか、ディスクに永続化することができます。
- 取り込んだすべてのデータを永続的に保存するために NATS JetStream を活用することを意図しています。
- すべての読み書き操作のパフォーマンスを向上させるために SSD を使用することを想定しています。
- 特にリテンションニーズを徐々に調整していく中で、基盤ストレージを十分な余裕を持ってプロビジョニングし、取り込みデータの保持ポリシーを適用することを意図しています。運用の観点から、必要に応じて基盤ストレージを容易に増加できる能力が必要です。
- ストレージフットプリントをさらに削減するためにデータ圧縮を有効にすることを想定しています。
GitLab との統合
- 前述の NATS 接続文字列をインスタンス設定に追加してサービス・アプリケーションが使用できるようにすることができます。例:
/etc/gitlab/gitlab.rbにnats['address'] = 'nats://nats.default.svc.cluster.local:4222'を追加する、またはgitlab.ymlでNATS_URL=nats://nats.default.svc.cluster.local:4222を上書きする。
セキュリティ
認証・認可
- NATS は TLS で暗号化された接続のための組み込みサポートを持っています。
- JWT/NKEYS を通じた集中型認証サポートも備えています。
- プロデューサー・コンシューマーなど特定のストリームのような、異なるシステム間で別々のプリンシパル(ユーザー・アカウント)の使用を推進することを想定しています。
- NATS は
accountsを使用したクライアントとサブジェクトスペースのグループ化を提供します。
認証・認可の設定例
ここでは Siphon をユースケースの例として取り上げ、以下をカバーします:
- クライアントを分離するためのアカウントの作成。
- 利用可能なサブジェクトに対する特定の権限を持つユーザーをこれらのアカウントに追加。認証は nkeys を通じて行われます。
- プロデューサーとコンシューマーはそれぞれ独自のユーザーと権限を持ちます。
- プロデューサー・コンシューマーの
nkeysは、現在データベースシークレットに対して行っているのと同じセキュリティプラクティスで扱います。
authorization.conf の例
listen: 127.0.0.1:4222
jetstream: enabled
producer_permissions = {
publish = ">"
subscribe = ">"
}
consumer_permissions = {
publish = {
deny = ">"
}
subscribe = ">"
}
accounts: {
siphon: {
users: [
{nkey: Uxx, permissions: $producer_permissions},
{nkey: Uxx, permissions: $consumer_permissions}
]
}
}
上記の設定では、プロデューサーは siphon アカウントのすべてのサブジェクトスペースで発行およびサブスクライブが許可されており、コンシューマーは利用可能なサブジェクトへのサブスクライブのみが許可されています。
必要に応じてサブジェクトスペースにさらなる細かさを適用することもできます。permissions マップの使用により、このような細かい制御が可能です。
この設定の使用例:
func TestServerConfiguration(t *testing.T) {
server, _ := RunServerWithConfig("authorization.conf")
t.Logf(server.ClientURL())
// producer_nkey.txt holds the nkey seed
opt, err := nats.NkeyOptionFromSeed("producer_nkey.txt")
if err != nil {
t.Error(err)
return
}
nc, err := nats.Connect(server.ClientURL(), opt)
if err != nil {
t.Error(err)
return
}
js, err := nc.JetStream()
if err != nil {
t.Error(err)
return
}
_ = js.Streams()
defer nc.Close()
}
暗号化
NATS は静止状態での暗号化をサポートしていますが、利用可能な場合はファイルシステム暗号化の使用を推奨しています。
デプロイターゲットを考慮すると、追加の顧客管理キーオプションをサポートする GCP と AWS の両方で利用可能なディスク暗号化を使用することを意図しています。
監査・ロギング
- 監査・監視目的を有効にするために、必要な NATS ログを集中型ロギングインフラに送信することを意図しています。
運用
スケーラビリティ
NATS は非常に軽量で、サブミリ秒レイテンシで大量のメッセージを取り込み・消化することをサポートします。そのアーキテクチャにより、バックプレッシャーの処理とトラフィック量に応じたフロー制御にも最適化されています。
3 サーバーの Kubernetes ベース NATS クラスターに対して以下の予備テストを実施しました。各サーバー(Pod)は c2d-standard-16 GKE ノード上で実行され、データストレージ用の 100GB pd-balanced SSD 永続ボリュームが接続されています。
注: 基盤となる GKE クラスターは 3 つの異なる AZ にクラスターノードが分散されたリージョナルクラスターです。NATS サーバー(Pod)はテスト中常に 3 つの AZ に慎重に分散されました。
主要な洞察
- CPU 使用率は、非同期パブリッシャーが短時間に非常に多くのイベントを生成する場合の大きなスパイクを伴い、クラスターの使用量に直接比例する。
- メモリ使用量は取り込まれたイベントの量に関わらず安定していた。
- クロス AZ レプリケーションはクラスタースループットに影響するが、全体的なパフォーマンスは即時のニーズを大幅に超えたまま維持される。
ストリームレプリケーションを使用した同期パブリッシャー
CPU 使用率は一貫して低く維持されながら、書き込みスループットは顕著に低下する。
➜ platform-pre-stg kubectl -n nats exec -it nats-box-6888bbc55c-kd6tm -- nats --server=nats://nats.nats.svc.cluster.local:4222 bench foobar --pub 1 --sub 5 --msgs=1000000 --js --maxbytes 20GB --purge --replicas=2 --syncpub
10:55:59 JetStream ephemeral ordered push consumer mode, subscribers will not acknowledge the consumption of messages
10:55:59 Starting JetStream benchmark [subject=foobar, multisubject=false, multisubjectmax=100000, js=true, msgs=1,000,000, msgsize=128 B, pubs=1, subs=5, stream=benchstream, maxbytes=20 GiB, storage=file, syncpub=true, pubbatch=100, jstimeout=30s, pull=false, consumerbatch=100, push=false, consumername=natscli-bench, replicas=2, purge=true, pubsleep=0s, subsleep=0s, dedup=false, dedupwindow=2m0s]
NATS Pub/Sub stats: 7,957 msgs/sec ~ 994.75 KB/sec
Pub stats: 1,326 msgs/sec ~ 165.81 KB/sec
Sub stats: 6,631 msgs/sec ~ 828.96 KB/sec
[1] 1,326 msgs/sec ~ 165.80 KB/sec (1000000 msgs)
[2] 1,326 msgs/sec ~ 165.80 KB/sec (1000000 msgs)
[3] 1,326 msgs/sec ~ 165.80 KB/sec (1000000 msgs)
[4] 1,326 msgs/sec ~ 165.79 KB/sec (1000000 msgs)
[5] 1,326 msgs/sec ~ 165.81 KB/sec (1000000 msgs)
min 1,326 | avg 1,326 | max 1,326 | stddev 0 msgs
ストリームレプリケーションを使用した非同期パブリッシャー、バッチサイズ 100、1000、10000 でのテスト
CPU 使用率はバッチサイズに比例し、中程度のバッチサイズでは書き込みスループットが向上する。
➜ platform-pre-stg kubectl -n nats exec -it nats-box-6888bbc55c-kd6tm -- nats --server=nats://nats.nats.svc.cluster.local:4222 bench foobar --pub 1 --sub 5 --msgs=1000000 --js --maxbytes 20GB --purge --replicas=2
11:13:02 JetStream ephemeral ordered push consumer mode, subscribers will not acknowledge the consumption of messages
11:13:02 Starting JetStream benchmark [subject=foobar, multisubject=false, multisubjectmax=100000, js=true, msgs=1,000,000, msgsize=128 B, pubs=1, subs=5, stream=benchstream, maxbytes=20 GiB, storage=file, syncpub=false, pubbatch=100, jstimeout=30s, pull=false, consumerbatch=100, push=false, consumername=natscli-bench, replicas=2, purge=true, pubsleep=0s, subsleep=0s, dedup=false, dedupwindow=2m0s]
NATS Pub/Sub stats: 274,880 msgs/sec ~ 33.55 MB/sec
Pub stats: 46,073 msgs/sec ~ 5.62 MB/sec
Sub stats: 229,066 msgs/sec ~ 27.96 MB/sec
[1] 46,021 msgs/sec ~ 5.62 MB/sec (1000000 msgs)
[2] 45,866 msgs/sec ~ 5.60 MB/sec (1000000 msgs)
[3] 45,901 msgs/sec ~ 5.60 MB/sec (1000000 msgs)
[4] 45,813 msgs/sec ~ 5.59 MB/sec (1000000 msgs)
[5] 45,986 msgs/sec ~ 5.61 MB/sec (1000000 msgs)
min 45,813 | avg 45,917 | max 46,021 | stddev 76 msgs
➜ platform-pre-stg kubectl -n nats exec -it nats-box-6888bbc55c-kd6tm -- nats --server=nats://nats.nats.svc.cluster.local:4222 bench foobar --pub 1 --sub 5 --msgs=1000000 --js --maxbytes 20GB --purge --replicas=2 --no-progress --pubbatch=1000
11:17:38 JetStream ephemeral ordered push consumer mode, subscribers will not acknowledge the consumption of messages
11:17:38 Starting JetStream benchmark [subject=foobar, multisubject=false, multisubjectmax=100000, js=true, msgs=1,000,000, msgsize=128 B, pubs=1, subs=5, stream=benchstream, maxbytes=20 GiB, storage=file, syncpub=false, pubbatch=1,000, jstimeout=30s, pull=false, consumerbatch=100, push=false, consumername=natscli-bench, replicas=2, purge=true, pubsleep=0s, subsleep=0s, dedup=false, dedupwindow=2m0s]
NATS Pub/Sub stats: 524,251 msgs/sec ~ 64.00 MB/sec
Pub stats: 152,262 msgs/sec ~ 18.59 MB/sec
Sub stats: 436,876 msgs/sec ~ 53.33 MB/sec
[1] 100,985 msgs/sec ~ 12.33 MB/sec (1000000 msgs)
[2] 88,393 msgs/sec ~ 10.79 MB/sec (1000000 msgs)
[3] 88,367 msgs/sec ~ 10.79 MB/sec (1000000 msgs)
[4] 87,896 msgs/sec ~ 10.73 MB/sec (1000000 msgs)
[5] 87,375 msgs/sec ~ 10.67 MB/sec (1000000 msgs)
min 87,375 | avg 90,603 | max 100,985 | stddev 5,204 msgs
➜ platform-pre-stg kubectl -n nats exec -it nats-box-6888bbc55c-kd6tm -- nats --server=nats://nats.nats.svc.cluster.local:4222 bench foobar --pub 1 --sub 5 --msgs=1000000 --js --maxbytes 20GB --purge --replicas=2 --no-progress --pubbatch=10000
11:17:57 JetStream ephemeral ordered push consumer mode, subscribers will not acknowledge the consumption of messages
11:17:57 Starting JetStream benchmark [subject=foobar, multisubject=false, multisubjectmax=100000, js=true, msgs=1,000,000, msgsize=128 B, pubs=1, subs=5, stream=benchstream, maxbytes=20 GiB, storage=file, syncpub=false, pubbatch=10,000, jstimeout=30s, pull=false, consumerbatch=100, push=false, consumername=natscli-bench, replicas=2, purge=true, pubsleep=0s, subsleep=0s, dedup=false, dedupwindow=2m0s]
NATS Pub/Sub stats: 424,064 msgs/sec ~ 51.77 MB/sec
Pub stats: 70,985 msgs/sec ~ 8.67 MB/sec
Sub stats: 353,386 msgs/sec ~ 43.14 MB/sec
[1] 71,156 msgs/sec ~ 8.69 MB/sec (1000000 msgs)
[2] 70,899 msgs/sec ~ 8.65 MB/sec (1000000 msgs)
[3] 70,757 msgs/sec ~ 8.64 MB/sec (1000000 msgs)
[4] 70,887 msgs/sec ~ 8.65 MB/sec (1000000 msgs)
[5] 70,812 msgs/sec ~ 8.64 MB/sec (1000000 msgs)
min 70,757 | avg 70,902 | max 71,156 | stddev 137 msgs
非同期パブリッシャー、プル vs プッシュコンシューマーのテスト
CPU 使用率については特筆すべきことはなく、プルコンシューマーはプッシュコンシューマーよりも優れたパフォーマンスを示す。
➜ platform-pre-stg kubectl -n nats exec -it nats-box-6888bbc55c-kd6tm -- nats --server=nats://nats.nats.svc.cluster.local:4222 bench foobar --pub 1 --sub 5 --msgs=1000000 --js --maxbytes 20GB --purge --replicas=2 --no-progress --pubbatch=100 --push
11:24:53 JetStream durable push consumer mode, subscriber(s) will explicitly acknowledge the consumption of messages
11:24:53 JetStream ephemeral ordered push consumer mode, subscribers will not acknowledge the consumption of messages
11:24:53 Starting JetStream benchmark [subject=foobar, multisubject=false, multisubjectmax=100000, js=true, msgs=1,000,000, msgsize=128 B, pubs=1, subs=5, stream=benchstream, maxbytes=20 GiB, storage=file, syncpub=false, pubbatch=100, jstimeout=30s, pull=false, consumerbatch=100, push=true, consumername=natscli-bench, replicas=2, purge=true, pubsleep=0s, subsleep=0s, dedup=false, dedupwindow=2m0s]
NATS Pub/Sub stats: 65,697 msgs/sec ~ 8.02 MB/sec
Pub stats: 32,912 msgs/sec ~ 4.02 MB/sec
Sub stats: 32,848 msgs/sec ~ 4.01 MB/sec
[1] 6,581 msgs/sec ~ 822.69 KB/sec (200000 msgs)
[2] 6,586 msgs/sec ~ 823.28 KB/sec (200000 msgs)
[3] 6,574 msgs/sec ~ 821.78 KB/sec (200000 msgs)
[4] 6,575 msgs/sec ~ 821.90 KB/sec (200000 msgs)
[5] 6,579 msgs/sec ~ 822.48 KB/sec (200000 msgs)
min 6,574 | avg 6,579 | max 6,586 | stddev 4 msgs
➜ platform-pre-stg kubectl -n nats exec -it nats-box-6888bbc55c-kd6tm -- nats --server=nats://nats.nats.svc.cluster.local:4222 bench foobar --pub 1 --sub 5 --msgs=1000000 --js --maxbytes 20GB --purge --replicas=2 --no-progress --pubbatch=100 --pull
11:25:56 JetStream durable pull consumer mode, subscriber(s) will explicitly acknowledge the consumption of messages
11:25:56 Starting JetStream benchmark [subject=foobar, multisubject=false, multisubjectmax=100000, js=true, msgs=1,000,000, msgsize=128 B, pubs=1, subs=5, stream=benchstream, maxbytes=20 GiB, storage=file, syncpub=false, pubbatch=100, jstimeout=30s, pull=true, consumerbatch=100, push=false, consumername=natscli-bench, replicas=2, purge=true, pubsleep=0s, subsleep=0s, dedup=false, dedupwindow=2m0s]
NATS Pub/Sub stats: 95,057 msgs/sec ~ 11.60 MB/sec
Pub stats: 47,747 msgs/sec ~ 5.83 MB/sec
Sub stats: 47,528 msgs/sec ~ 5.80 MB/sec
[1] 15,410 msgs/sec ~ 1.88 MB/sec (200000 msgs)
[2] 12,056 msgs/sec ~ 1.47 MB/sec (200000 msgs)
[3] 11,976 msgs/sec ~ 1.46 MB/sec (200000 msgs)
[4] 9,556 msgs/sec ~ 1.17 MB/sec (200000 msgs)
[5] 9,530 msgs/sec ~ 1.16 MB/sec (200000 msgs)
min 9,530 | avg 11,705 | max 15,410 | stddev 2,157 msgs
監視
- Prometheus メトリクスとして公開される組み込み監視。詳細はこちら。
クラスターアップグレード
NATS はマルチノードクラスターをプロビジョニングして段階的なローリングリスタートを実行できる限り、クラスターのアップグレードに関する十分に文書化されたパスを提供します。
Kubernetes 上の Statefulset を通じて NATS を実行する場合、
.spec.updateStrategyをRollingUpdateに設定することにより、基盤となる Kubernetes Statefulset コントローラーによってアップデートの増分ロールアウトが一度に 1 つの Pod に自動的に処理できます。ベア VM 上で NATS を実行する場合、クラスターのセットアップ方法によって、オペレーターが手動またはツールを使用してクラスターのローリングアップグレードを実行する必要があります。
障害シナリオ
NATS のサービスが完全に利用不能になった場合、特に NATS が受信データを最初に格納する場所であるシナリオでは、データの損失が発生する可能性があります。
特定の NATS クラスター内の 1 つ以上のノードが失われた場合、他のストリームレプリカが設定されており、影響を受けたストリームの新しいリーダーシップを引き受けられる限り、クライアントは新しいイベントをプッシュし続けることができます。メッセージの損失を許容できないクライアントについては、ストリームレプリケーションが強く推奨されます。これにより、クラスターの劣化が改善されると同時に影響を受けたストリームが回復することが確保されます。
ストリームレプリケーションは取り込まれたデータの冗長性を確保しますが、非同期書き込みはデータの損失につながる可能性があります。データの損失を最小限に抑えるために、クライアントは同期書き込みを優先するべきです。これにより、すべての取り込まれたデータが書き込みが確認される前に永続的にレプリケートされることが確保されますが、同期書き込みは全体的な書き込みパフォーマンスを低下させるというトレードオフがあります。
注 NATS パブリッシャーまたはコンシューマーの設計方法の詳細はこのブループリントのスコープ外です。NATS アプリケーション構築のためのすべてのユーザー向けドキュメントは別途開発されます。
- 取り込まれたすべてのデータは NATS JetStream を通じて永続的に保存されます。ただし、回復不能なメッセージが発生した場合は、以下を含む明示的なディザスターリカバリーセットアップを使用してデータを回復できます:
- レプリケートされたストリームの無傷のクォーラムノードが存在する場合の自動回復、または
- 定期的なストリームバックアップからの手動回復。
注 保存されたすべてのデータが回復可能であることを確保するために、すべての GitLab デプロイメントタイプを考慮した上で、NATS のためのディザスターリカバリープロシージャを GitLab の一般的な DR 計画・ツールに統合する必要があります。
注: Siphon の特定のケースでは、NATS 内でバッファリングされた ClickHouse にエクスポート予定のすべてのデータは、Postgres にも 引き続き 存在します。Siphon が NATS への接続に失敗したり NATS でデータ損失が発生したりした場合、Siphon は完全な再同期を実行して Postgres と ClickHouse 間のデータ一貫性を再び確保できます。これが不可能な他のユースケースについては、上記のようにバックアップから失われたデータを自動または手動で回復することに依存する必要があります。
- 集中型モデルを使用してデプロイ時に NATS 内でユーザー・アカウントをセットアップする場合、認証失敗は想定していませんが、外部認証コールアウトサービスの導入はシステムへの追加の障害ドメインをもたらす可能性があります。依存関係として、外部認証サーバーの実装における信頼性 SLO を NATS サービス自体と同等かそれ以上に保証する必要があります。このような抽象化の開発はこのイテレーションのブループリントでは スコープ外 です。
追加コンテキスト
なぜ Kafka を選ばないのか?
データを永続的にキュー・バッファリングするニーズを考えると、Apache Kafka が明らかな最初の選択肢として浮かびます。しかし、GitLab をクラウドネイティブデプロイメントとして実行することに焦点を移す中で、特に Kafka の運用と配布の複雑さを考えると、私たちの目的には あまり適していない ことになります。以下は、Kafka がもたらす課題に関する過去のディスカッションです:
- デプロイメント環境全体での Kafka のサポートが存在しない。
- Kafka はスケールに関わらずコスト的に問題になりうる。
- Kafka は運用が集約的になりうる。
- 現在の使用方法を置き換えるための重要な努力。
Kafka と NATS を比較する際の主要な考慮事項
| 機能 | 比較 |
|---|---|
| アーキテクチャ | Kafka はより大きな分散イベントストリーミングシステムであり、NATS は比較的軽量で高パフォーマンスなメッセージングシステムです。Kafka はパブリッシュ・サブスクライブの使用に最適化されていますが、NATS はパブリッシュ・サブスクライブ、リクエスト・リプライ、データキューイングのすべてのパターンを許可します。 |
| 運用 | Kafka はパーティション・トピック・ブローカー間の調整のために Zookeeper/KRaft が必要ですが、NATS は外部依存関係のないシングルバイナリとして配布されます。Kafka クラスターの拡張はブローカー間のパーティションの再バランスが必要ですが、NATS はよりシームレスにノードを水平追加できます。Kafka は JVM での実行も必要ですが、NATS はホスト上でネイティブに実行できます。 |
| デプロイメント | Kafka は Kubernetes 上でクラウドネイティブに実行できますが、NATS と比較してよりリソース集約的で、運用するコンポーネントが少ない NATS と比べてサポートオーバーヘッドが大きくなります。 |
| 可用性と配布 | Kafka がすべてのデプロイメント環境で利用可能であることを確保することは、特に Kafka のコスト的な問題のある性質を考えると、小規模なクラスタートポロジーでも困難な作業です。一方 NATS は最小限のオーバーヘッドで実行でき、GitLab インストールに近接してデプロイでき、配布の労力も大幅に少なくて済みます。 |
c955a93f)