データインサイトプラットフォーム クエリ API
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| accepted | rob.hunt | ahegyi | lfarina8
nicholasklick | group platform insights | 2025-02-27 |
概要
データインサイトプラットフォーム(DIP)は、GitLab 全体で生成された分析データストリームを取り込み、処理し、永続化してクエリするための統合抽象化であり、製品全体のビジネスインサイトを計算する能力を実現します。
この作業のうち、さらに定義が必要なのは、DIP でデータが処理・永続化されたあとに分析データをクエリできるようにすることです。クエリ API は以下を満たさなければなりません:
- 顧客が使いやすく、異なるデータテーブルとのインタラクションの複雑さを API から遠ざけ、バックエンドサービスに集約する。
- 顧客がどのようなデータが利用可能で、そのデータがどのようなプロパティを持ち、どのように対話できるかを簡単に識別できるよう一貫性を持つ。
これは、GitLab API 全般における現在の混乱のために重要です。私たちが直面している問題は、多くの GitLab GraphQL および REST API が一貫性を欠いており、顧客が GitLab とインタラクションする際の混乱に貢献しているということで、これをさらに複雑化しないようにしなければなりません。
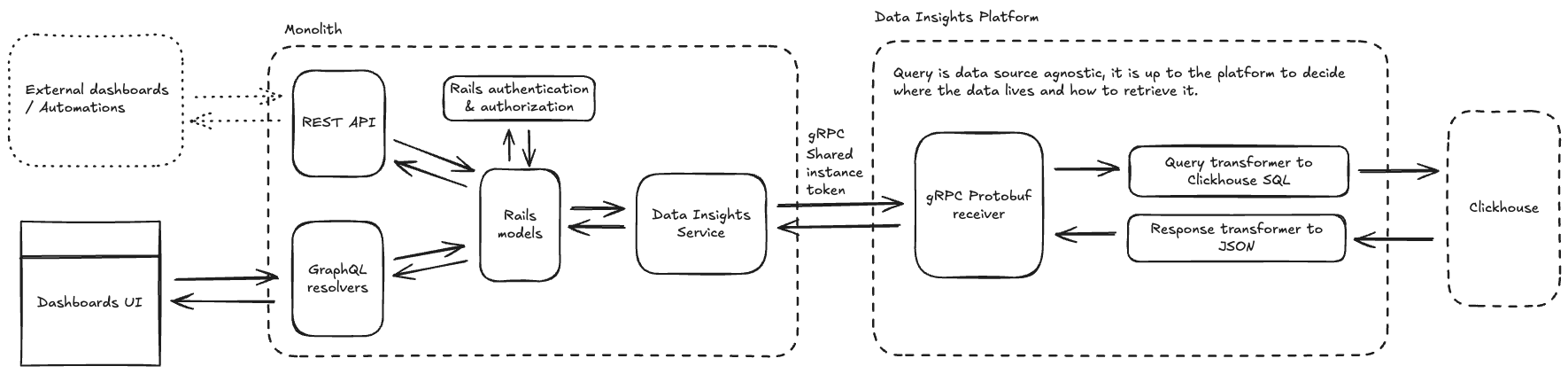
全体的なクエリアーキテクチャには 2 つの側面があります。最初の部分は、既存の GraphQL および REST API を通じた顧客と DIP のコミュニケーションです。2 番目の部分は、GitLab Rails アプリケーション(モノリス)とデータインサイトサービスを通じた DIP とのコミュニケーションです。
この提案は最初の部分を参照していますが、2 番目の部分の実装に焦点を当てています。
目標
- クエリ API は ClickHouse エクスポーターをサポートしなければならない
- 代替エクスポーターをサポートする計画がありますが、コアの最初の目標は Siphon と連携して GitLab データを照合・分析することです。データは ClickHouse テーブルに保存されます。
- 一貫した API インターフェイス
- 過去に API が利用可能なデータの種類とフィルタリングオプションで一貫性を欠くという問題がありました。これによりユーザーエクスペリエンスがより混乱したものになりました。
- 達成は困難ですが、API リクエストの作成や処理方法を大幅に変更することなく、異なるデータ型とフィルタリングオプションを許可する API を開発する必要があります。
- DIP クエリ API に GraphQL および REST API エンドポイントを統合する方法についての、他の GitLab チームへのサポートと明確なドキュメント化された指示を提供します。
- エンドユーザー API から複雑さを遠ざける
- DIP は幅広いデータ型とデータソースを処理し、完全な分析のために 1 つのプラットフォームに収束させます。この複雑さをエンドユーザー API に転嫁したくありません。
- API を使いやすく保つ必要があります。明確なドキュメントがあること。ユーザーは利用可能なデータについて情報を得ることができる必要があります。どのデータベースやテーブルを使用するかを知ることを求められるべきではありません。
- 認証と認可
- DIP が収集するデータにはさまざまなデータプライバシーカテゴリが混在しています。クエリされたデータが正しい認証と認可を持つ者のみがアクセスできるようにする必要があります。リクエスターの権限外のデータはいかなる方法でもアクセスできてはなりません。
- データ分類は Atlan のデータカタログによって決定されます。
対象外
- この初期フェーズでは Snowflake などの他のデータソースのサポートは対象外。
- Monitor/Platform Insights が所有していない ClickHouse を活用するすべての他の GraphQL および REST API 呼び出しの統合は対象外。この作業はドメイン専門知識を持つチームによって最善に実行されます。Monitor/Platform Insights がすべてのチームのためにこれを行うことはスケーラブルではありません。チームが独自のエンドポイントを DIP に統合できるようにサポートとドキュメントが提供されます。
歴史的背景
既存の API
すでに独自の ClickHouse データベース内の分析データを扱うために開発された 3 つの API があります。これらの API は独立して開発されたため、利用可能なデータ、API との対話方法、データのフォーマットの点で互換性がありません。
オブザーバビリティと Cube API はクエリ API の必須部分として計画されていませんが、歴史的な背景と経験から学ぶためにここに記載しています。
オブザーバビリティ API
Go で書かれたオブザーバビリティ API は REST ベースで、GitLab Observability Backend(GOB)からデータを取得するために使用されます。データは別の ClickHouse データベースに保存され、OTel フォーマットで動作するようにフォーマットされています。
API はリクエストの認証に Cloud Connector を使用し、グループ内の複数のプロジェクトにまたがることができず、単一のプロジェクトリクエストに制限されています。
ユーザーは API のさまざまなエンドポイントを通じて GOB に直接データを読み書きできます:
- 読み取り:
get api/v4/projects/[PROJECT_ID]/observability/v1/analyticsget api/v4/projects/[PROJECT_ID]/observability/v1/tracesget api/v4/projects/[PROJECT_ID]/observability/v1/servicesget api/v4/projects/[PROJECT_ID]/observability/v1/metricsget api/v4/projects/[PROJECT_ID]/observability/v1/logs
- 書き込み:
post api/v4/projects/[PROJECT_ID]/observability/v1/tracespost api/v4/projects/[PROJECT_ID]/observability/v1/metricspost api/v4/projects/[PROJECT_ID]/observability/v1/logs
この API は十分にドキュメント化されておらず、期待されるデータと使用可能なパラメーターを理解するには GOB または GitLab 内のコードを読む必要があります。ただし、DIP に取り組んでいる間 O11y が顧客向けサービスとして撤退しているため、これは予想されることです。
Cube API
プロダクトアナリティクスはCubeを使用して、ClickHouse をデータの保存に使用するアナリティクススタックと通信するためのクエリレイヤーとして機能させています。
リクエストは Rails 認証を使用してリクエストを検証し、フロントエンドから Cube への直接 API リクエストを防ぎ、エラーを処理し、必要なデータ変換を行う Cube プロキシに送られます。現在行われている唯一のデータ変換は、指定された日付範囲内の空のデータポイントを埋めることです。この変換は ClickHouse を直接使用して行うことができますが、Cube ではサポートされておらず、サポートを追加する提案は Cube コアチームによって却下されました。
Cube はマルチテナント環境内でセキュリティコンテキストを定義するために JSON Web Tokens(JWT)を使用しており、これがプロキシを使用するもう 1 つの理由です。Rails 認証を使用してリクエスターがプロジェクトの分析データを取得する権限があるかどうかを確認し、正しいプロジェクト権限で JWT を構築します。これによりリクエスターが Cube からデータを取得できます。
Cube プロキシから、Cube は事前定義されたスキーマを使用して ClickHouse クエリを生成してデータを返します。Cube はユーザーがクエリを定義して一貫したフォーマットでデータを返すための一貫したクエリ言語を提供し、多くの事前構築されたフィルターとフォーマットされたデータ型を持っています。
Cube API は次のエンドポイントを持つ読み取り専用の REST API です:
get v1/meta- Cube データソースと連携してデータエクスプローラーで可能なフィールド、データ型、フィルタリングオプションのリストを生成するために使用されます。
post v1/load- 提供されたクエリのデータを取得するために使用されます。データ取得のためのコアエンドポイント。
API はREST API ドキュメント内でドキュメント化されています。Cube 以外の代替アプローチに移行することを決定した場合、これは非推奨化または削除が必要になります。
Cube のCube ストアを使用せずにより高度な機能をサポートすることに問題がありました(RED データをそのソリューションに保存することへの懸念がありました)。また、特定の機能や ClickHouse の事前集計などのより高度な機能をサポートしていません。そのため、しばらくの間 Cube から離れることについて多くの議論がありました。
Optimize
Optimize は ClickHouse を使用して、コントリビューション、バリューストリーム、AI インパクトダッシュボードの集計クエリをパフォーマントに保ちます。
コントリビューションに関しては、Postgres からのデータが 3 分ごとに集計されて ClickHouse に追加されます。データ取得時には、ClickHouse データと特定の Postgres データの組み合わせを使用してコントリビューションダッシュボードを表示します。
バリューストリームと AI インパクトはデータに ClickHouse のみを使用します。AI インパクトはコントリビューションとバリューストリームの 3 分ではなく 5 分ごとにデータを更新します。
3 つのダッシュボードすべてで、フロントエンドがモノリスをクエリするために GraphQL を使用し、GraphQL リゾルバーは Optimize チームが保守する clickhouse_client gem パッケージを使用して ClickHouse データベースを直接呼び出しします。
以下の GraphQL タイプが使用されます:
GroupValueStreamAnalyticsFlowMetricsProjectValueStreamAnalyticsFlowMetricsGroupValueStreamDashboardUsageOverviewProjectValueStreamDashboardUsageOverviewGroupValueStreamsProjectValueStreamsGroupContributionsGroupAiMetricsProjectAiMetricsGroupAiUserMetricsProjectAiUserMetricsaiUsageData(グループ)aiUsageData(プロジェクト)
GLQL
GitLab クエリ言語(GLQL)は、Plan ステージ内で顧客が GitLab データとインタラクションするための単一クエリ言語を開発するために始まったイニシアティブです。
GLQL は現在、Markdown ブロック内で使用されることを目的として構築されており、ベース言語として YAML を使用しています。執筆時点では Issues のみをサポートしており、以下での使用のために特別に開発されています:
- Wiki(グループとプロジェクト)
- エピックとエピックコメント
- Issue と Issue コメント
- マージリクエストとマージリクエストコメント
- ワークアイテム(タスク、OKR、新しいルックのエピック)とワークアイテムコメント
GLQL の最初の目標は、顧客がコラボレーションと計画に役立てるための Issue の自動更新リストを生成できるようにすることです。中期的には、Plan ステージはマージリクエスト、エピック、その他のワークアイテムのリスト表示サポートを追加する予定です。
長期的には、GLQL はデータプラットフォームパズルの最後のピースとなり、顧客が Plan 固有のデータだけでなく、すべての GitLab データとインタラクションするための一貫したクエリフォーマットを提供できます。これにはデータプラットフォームからのデータも含まれます。しかし、内部リソースの制限により、これは FY26 では実現できるものではなく、長期的な理想です。
GLQL は Rust を使用して構築されています。コードは WASM フロントエンドモジュールにコンパイルされます。モジュールは GLQL クエリを解析し、結果の GraphQL クエリを生成します。生成された GraphQL クエリは、結果データをリクエストするためにフロントエンドによって通常通り使用されます。
クエリ API の前書き
DIP がどのように機能するかという複雑さを API コンシューマーから取り除く必要があります。したがって、データがどこから来たかを無視し、このデータが存在するということのみを認識する API コンシューマーのための一貫したインターフェイスを提供するクエリ API を作成する必要があります。
廃棄された解決策
いくつかの潜在的な解決策が検討されましたが、実行不可能として廃棄されました:
- 既存の API 実装の再利用
- 既存の実装は外部依存関係に依存しており、DIP の要件に反します。
- プロダクトアナリティクスとオブザーバビリティは提供物として削除されるため、既存の実装は使用されません。
- GLQL との直接統合
- Rust で書かれており(Rust の理由はドキュメント化されています)、Monitor ステージ内での知識が限られており、主に Go ベースの DIP に追加するための追加ステップが必要になります。
- GLQL ロードマップは Plan ステージに焦点を当てており、直接統合するとそのロードマップから外れてしまいます。
もちろん、既存の API を新しい API の開発における学習の機会として利用できます。
選択された解決策
UI/顧客コミュニケーションには既存の GraphQL および REST API インフラを使用し、モノリスと DIP 間の通信には gRPC 上の Protobuf API を使用します。
後で、GLQL 統合でこれらの API を拡張します。GLQL は既存の API との統合を念頭に置いて構築されており、エンドユーザーは GLQL を使用してクエリを構築し、GLQL はリクエストを基礎となる API 呼び出しに変換します。そのため、私たちは独自の API を構築し、GLQL が GA になった後で既存の GLQL インフラに統合することができます。
また、GLQL が GA になった時点で Plan と協力して後で統合するタイミングを見つけることができるため、Plan の既存のロードマップを遅らせることについて心配する必要はありません。
API 構造
GraphQL と REST の 2 つの既存の GitLab API が Rails モデルを通じてモノリスの DIP サービスと通信する必要があります。
モノリスの DIP サービスが DIP 自体と通信し、モノリスが理解できる何かにレスポンスを変換するための新しい Protobuf-over-gRPC API を作成する必要があります。
モノリス内の GraphQL および REST API は DIP に取り組むチームによって設計されません。これらの API は機能を所有するチームが所有します。DIP に取り組むチームは DIP 自体との統合のみを所有してサポートします。
GraphQL フォーマット
GraphQL API は既存の GitLab GraphQL サービスを使用します。したがって、サービス内で新しい GraphQL エンドポイントを開発するための関連するガイドラインをすべて遵守する必要があります。
GraphQL API の構造は機能を構築するチームによって決定されます。DIP はこの API の構造を決定しません。DIP が理解できる何かに GraphQL リクエストを変換し、リクエスターに返すための DIP からのレスポンスを処理するのは機能を構築するチームの責任です。
ドキュメントで、GraphQL リゾルバーが DIP サービスとどのように対話するかについて、期待されるリクエストとレスポンスの観点から文書化する必要があります。
REST フォーマット
REST API は既存の GitLab REST API を使用します。したがって、既存の REST API フレームワーク内で新しい REST エンドポイントを開発するための関連するガイドラインをすべて遵守する必要があります。
REST API の構造は機能を構築するチームによって決定されます。DIP はこの API の構造を決定しません。DIP が理解できる何かに REST リクエストを変換し、リクエスターに返すための DIP からのレスポンスを処理するのは機能を構築するチームの責任です。
ドキュメントで、REST ハンドラーが DIP サービスとどのように対話するかについて、期待されるリクエストとレスポンスの観点から文書化する必要があります。
受け取ることが予想されるクエリの性質上(特定のプロジェクトやユーザーによるフィルタリングなどの広範なフィルタリングオプション、PII データを含む可能性のあるクエリなど)、REST エンドポイントはクエリを REST エンドポイントに送信するために POST を使用しなければなりません。POST を使用することで、URL の長さ制限(約 2,000 文字)を回避し、PII データが GET クエリログに保存されるのを防ぐことができます。
POST クエリには、与えられたパラメーターにサイズ制限を適用しなければなりません。これは、ユーザーが 10 万人のユーザーからすべての MR などの過剰なデータリクエストを試みるのを防ぐためです。
Protobuf フォーマット
Protobuf API はバイナリフォーマットを使用して書かれなければなりません。ProtoJSON を使用しても動作しますが、パフォーマンスが大幅に低下し、より多くのリソースを使用します。
API は Protobuf スタイル標準とベストプラクティスに従わなければなりません。また、すべてのリクエストが Protobuf で規定されている制限を超えないようにしなければなりません。レスポンスがこれらの制限を超えることが予想される場合、ストリーミングに変換してリクエスターにチャンクで送信しなければなりません。
API の変更に対しては、.proto ファイルを Go と Rails の両方用に生成しなければなりません。これらはそれぞれ DIP とモノリスに追加しなければなりません。
バージョニング
GitLab の GraphQL および REST API のバージョニングガイドラインに従わなければなりません。
gRPC では、Go 内のパッケージをバージョン管理しなければなりません。これにより gRPC 呼び出し自体がバージョン管理され、バージョンアップグレードを管理できます。ベストプラクティスの提案については、Microsoft が .NET に焦点を当てた優れたガイドを提供しており、他の言語にも適用できます。
gRPC 内の機能フラグについては、Gitaly と同じ標準に従わなければなりませんが、フラグのプレフィックスは data_insights_* を使用します。
Protobuf はベストプラクティスに従うことで自動的にバージョニングを処理するように設計されています。フィールド番号やフィールド名を再利用してはなりません。将来のバージョンで削除されたフィールドは reserved にしなければなりません。
ページネーション
パフォーマンス上の理由から、非集計クエリはキーセットベースのページネーションに従わなければなりません。このアプローチはページ ID を使用する代わりに次のページへのリンク(またはカーソル)を公開します。次と前のページ(該当する場合)のカーソルがあり、列データを使用して適切なカーソルを生成します。GraphQL ではすでにこれを行っています。
集計クエリとは、データベース内の個々の行をリストするのではなく、一定期間にわたる小さなデータポイントのサブセットを確認するクエリです。つまり、マージされた MR を表のリストとして表示するのではなく、時系列でマージされた MR のビジュアライゼーションを表示する違いです。
集計クエリはタイムスタンプなどの制限要因で制限されなければなりませんが、その性質上ページネーションすることはできません。これらのクエリは集計であることを示すためにタグまたはラベル付けされなければなりません。
ClickHouse は「従来の」プライマリキーを活用しないため、ページネーションリンクを生成する際にクエリ内の次のアイテムグループを定義するためにソートオプションに依存する必要があります。たとえば、ユーザーが最終更新タイムスタンプの降順でソートする場合、生成されたページネーションリンクは前のクエリで最も古い最終更新タイムスタンプからフィルタリングします。クエリがソートオプションを定義していない場合、各エンドポイントのデフォルトを設定しなければなりません。
自動スキーマ生成
できるだけ効率的に API スキーマを最新の状態に保つために、Protobuf API のスキーマ生成とドキュメントの自動化を検討する必要があります。これは新しいバージョンの作成時、デプロイ時、またはすべてのマージ後にでも行えます。その後、関連するドキュメントを更新する必要があります。
クエリの例
これらのクエリは例示目的のみです。実際に書かれるものを反映するものではなく、実装中に最終的に構築するものを制限するものでもありません。
グループコントリビューション
GraphQL クエリ
query getContributionsData($fullPath: ID!, $startDate: ISO8601Date!, $endDate: ISO8601Date!, $nextPageCursor: String = "", $first: Int) {
group(fullPath: $fullPath) {
id
contributions(
from: $startDate
to: $endDate
first: $first
after: $nextPageCursor
) {
nodes {
repoPushed
mergeRequestsCreated
mergeRequestsMerged
mergeRequestsClosed
mergeRequestsApproved
issuesCreated
issuesClosed
totalEvents
user {
id
name
webUrl
}
}
pageInfo {
endCursor
hasNextPage
}
}
}
}
GraphQL 変数
"variables": {
"endDate": "2025-02-13",
"fullPath": "gitlab-org",
"nextPageCursor": "",
"startDate": "2025-02-06"
}
Protobuf 定義
// Editions version of proto3 file
edition = "2023";
package gitlab.group.contributions.v1;
option go_package = "gitlab.com/api/group/contributions/v1";
import "google/protobuf/timestamp.proto";
service GroupContributionsService {
// GetGroupContributions retrieves contribution data for a group within a date range
rpc GetGroupContributions(GetGroupContributionsRequest) returns (GetGroupContributionsResponse) {}
}
// Request message for GetGroupContributions
message GetGroupContributionsRequest {
// Full path of the group (e.g., "gitlab-org")
string full_path = 1;
// Start date for contributions in ISO8601 format (YYYY-MM-DD)
string start_date = 2;
// End date for contributions in ISO8601 format (YYYY-MM-DD)
string end_date = 3;
// Pagination: next page continuation token from previous response
optional string next_token = 4;
// Pagination: previous page continuation token from previous response
optional string previous_token = 5;
// Pagination: number of results to return
optional int32 page_size = 6;
}
// Response message for GetGroupContributions
message GetGroupContributionsResponse {
// Group info
Group group = 1;
// Pagination information
PageInfo page_info = 2;
}
// Group represents a GitLab group
message Group {
// Group ID
string id = 1;
// Contributions within the specified date range
ContributionConnection contributions = 2;
}
// ContributionConnection represents a paginated collection of contributions
message ContributionConnection {
// List of contribution nodes
repeated ContributionNode nodes = 1;
// Pagination information
PageInfo page_info = 2;
}
// ContributionNode represents a single user's contributions
message ContributionNode {
// Number of repository pushes
int32 repo_pushed = 1;
// Number of merge requests created
int32 merge_requests_created = 2;
// Number of merge requests merged
int32 merge_requests_merged = 3;
// Number of merge requests closed
int32 merge_requests_closed = 4;
// Number of merge requests approved
int32 merge_requests_approved = 5;
// Number of issues created
int32 issues_created = 6;
// Number of issues closed
int32 issues_closed = 7;
// Total number of events
int32 total_events = 8;
// User information
User user = 9;
}
// User represents a GitLab user
message User {
// User ID
string id = 1;
// User's name
string name = 2;
// URL to user's profile
string web_url = 3;
}
// PageInfo provides pagination metadata
message PageInfo {
// Token that can be used to fetch the next page
// When empty or missing, there are no more pages after this one
optional string next_token = 1;
// Token that can be used to fetch the previous page
// When empty or missing, there are no pages before this one
optional string previous_token = 2;
}
gRPC リクエスト
# Step 1: Add required gems to your Gemfile
# Gemfile
# gem 'grpc'
# gem 'google-protobuf'
# Step 2: Generate Ruby code from your .proto file using protoc
# You'd run this command in your terminal:
# protoc --ruby_out=lib/protos --grpc_ruby_out=lib/protos -I protos protos/group_contributions.proto
# Step 3: Create a client wrapper class in app/services/group_contributions_client.rb
module Services
class GroupContributionsClient
def initialize(host = 'localhost:50051', bearer_token)
# Use TLS/SSL for secure connection
ssl_creds = GRPC::Core::ChannelCredentials.new
auth_creds = bearer_token_credentials(bearer_token)
credentials = ssl_creds.compose(auth_creds)
@stub = Gitlab::Group::Contributions::V1::GroupContributionsService::Stub.new(
host,
credentials
)
end
def get_group_contributions(full_path, start_date, end_date, next_token = nil, previous_token = nil, page_size = 50)
request = Gitlab::Group::Contributions::V1::GetGroupContributionsRequest.new(
full_path: full_path,
start_date: start_date,
end_date: end_date,
next_token: next_token,
previous_token: previous_token,
page_size: page_size
)
@stub.get_group_contributions(request)
end
private
def bearer_token_credentials(token)
proc_metadata_generator = proc { { 'authorization' => "Bearer #{token}" } }
GRPC::Core::CallCredentials.new(proc_metadata_generator)
end
end
end
# Step 4: Use the client in your controller
class ContributionsController < ApplicationController
def index
client = Services::GroupContributionsClient.new(
ENV['CONTRIBUTIONS_GRPC_HOST'],
ENV['CONTRIBUTIONS_API_TOKEN']
)
# Determine which token to use based on navigation direction
next_token = params[:next_token]
previous_token = params[:previous_token]
@response = client.get_group_contributions(
params[:group_path],
params[:start_date],
params[:end_date],
next_token,
previous_token,
params[:page_size] || 50
)
# Transform gRPC response to a format suitable for your views
@contributions = @response.group.contributions.nodes.map do |node|
{
user: {
id: node.user.id,
name: node.user.name,
url: node.user.web_url
},
metrics: {
repo_pushes: node.repo_pushed,
mr_created: node.merge_requests_created,
mr_merged: node.merge_requests_merged,
mr_closed: node.merge_requests_closed,
mr_approved: node.merge_requests_approved,
issues_created: node.issues_created,
issues_closed: node.issues_closed,
total_events: node.total_events
}
}
end
@pagination = {
next_token: @response.page_info.next_token,
previous_token: @response.page_info.previous_token
}
respond_to do |format|
format.html
format.json { render json: { contributions: @contributions, pagination: @pagination } }
end
end
end
gRPC レスポンス
// SERVER IMPLEMENTATION
package main
import (
"context"
"log"
"net"
pb "gitlab.com/api/group/contributions/v1"
"google.golang.org/grpc"
)
type groupContributionsServer struct {
pb.UnimplementedGroupContributionsServiceServer
}
func (s *groupContributionsServer) GetGroupContributions(ctx context.Context, req *pb.GetGroupContributionsRequest) (*pb.GetGroupContributionsResponse, error) {
// In a real implementation, you would:
// 1. Parse dates
// 2. Fetch data from database
// 3. Format the response
// Mock implementation for example
return &pb.GetGroupContributionsResponse{
Group: &pb.Group{
Id: "gid://gitlab/Group/9970",
Contributions: &pb.ContributionConnection{
Nodes: []*pb.ContributionNode{
{
RepoPushed: 5,
MergeRequestsCreated: 3,
MergeRequestsMerged: 2,
MergeRequestsClosed: 1,
MergeRequestsApproved: 4,
IssuesCreated: 2,
IssuesClosed: 1,
TotalEvents: 18,
User: &pb.User{
Id: "gid://gitlab/User/123456",
Name: "Jane Developer",
WebUrl: "https://gitlab.com/jane_developer",
},
},
// Additional nodes would be added here
},
PageInfo: &pb.PageInfo{
NextToken: "next_token_xyz",
PreviousToken: "", // Empty because this is the first page
},
},
},
PageInfo: &pb.PageInfo{
NextToken: "next_token_xyz",
PreviousToken: "", // Empty because this is the first page
},
}, nil
}
func main() {
lis, err := net.Listen("tcp", ":50051")
if err != nil {
log.Fatalf("failed to listen: %v", err)
}
grpcServer := grpc.NewServer()
pb.RegisterGroupContributionsServiceServer(grpcServer, &groupContributionsServer{})
log.Println("Starting gRPC server on port 50051...")
if err := grpcServer.Serve(lis); err != nil {
log.Fatalf("failed to serve: %v", err)
}
}
// CLIENT IMPLEMENTATION
package main
import (
"context"
"log"
"time"
pb "gitlab.com/api/group/contributions/v1"
"google.golang.org/grpc"
"google.golang.org/grpc/credentials/insecure"
)
func main() {
conn, err := grpc.Dial("localhost:50051", grpc.WithTransportCredentials(insecure.NewCredentials()))
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
client := pb.NewGroupContributionsServiceClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
// Example of a first page request
resp, err := client.GetGroupContributions(ctx, &pb.GetGroupContributionsRequest{
FullPath: "gitlab-org",
StartDate: "2025-02-06",
EndDate: "2025-02-13",
NextToken: "", // Empty for initial request
PreviousToken: "", // Empty for initial request
PageSize: 50
})
if err != nil {
log.Fatalf("could not get group contributions: %v", err)
}
// Process the response, e.g.:
log.Printf("Group ID: %s", resp.Group.Id)
log.Printf("Number of contributors: %d", len(resp.Group.Contributions.Nodes))
// Access pagination info
log.Printf("Next page token: %s", resp.PageInfo.NextToken)
log.Printf("Previous page token: %s", resp.PageInfo.PreviousToken)
log.Printf("Has next page: %v", resp.PageInfo.NextToken != "")
log.Printf("Has previous page: %v", resp.PageInfo.PreviousToken != "")
// Store tokens for navigation
nextPageToken := resp.PageInfo.NextToken
// Example of requesting the next page (if available)
if nextPageToken != "" {
nextPageResp, err := client.GetGroupContributions(ctx, &pb.GetGroupContributionsRequest{
FullPath: "gitlab-org",
StartDate: "2025-02-06",
EndDate: "2025-02-13",
NextToken: nextPageToken, // Use next token from previous response
PreviousToken: "", // Not needed when navigating forward
PageSize: 50
})
if err != nil {
log.Fatalf("could not get next page: %v", err)
}
// Process next page...
log.Printf("Next page - contributors: %d", len(nextPageResp.Group.Contributions.Nodes))
}
// Access individual contributions
for i, node := range resp.Group.Contributions.Nodes {
log.Printf("Contributor #%d: %s", i+1, node.User.Name)
log.Printf(" Total group events: %d", node.TotalEvents)
// And so on...
}
}
プロトバッファパラメーターの例
グループコントリビューション
datetimeBefore- UTC のみ受け付けます。ユーザーのタイムゾーンへの変換はAPIの呼び出し元が行う必要があります
- ISO-8601 でフォーマット
datetimeAfter- UTC のみ受け付けます。ユーザーのタイムゾーンへの変換はAPIの呼び出し元が行う必要があります
- ISO-8601 でフォーマット
fullPath- GitLab グループ/名前空間/プロジェクトへのパス
レスポンスコード
Protobuf API は以下のレスポンスコードを返さなければなりません:
200 OK- 成功レスポンス時400 INVALID_ARGUMENT- クエリが不正な形式の場合401 UNAUTHENTICATED- ユーザーが認証されていない場合403 PERMISSION_DENIED- ユーザーが認証されているが、特定のリソースをクエリする権限がない場合404 NOT_FOUND- リクエストが不明なエンドポイントに送られた場合429 RESOURCE_EXHAUSTED- リクエストが API が処理できる以上のデータを取得しようとしている場合(たとえば、存在するすべての Issue のデータを取得しようとするなど)、またはレート制限が超過した場合500 INTERNAL- サーバーが予期せず失敗した場合
レスポンスボディは DIP のインフラや内部スキーマを公開してはなりません。すべてのレスポンスはメトリクスとログに送られなければなりません。クライアントに返されるエラーレスポンスは、内部の詳細を明かさずにエラーの原因を説明するユーザーフレンドリーなレスポンスでなければなりません。
認証、認可、セキュリティ
DIP へのリクエストはモノリスを通過しなければなりません。DIP は直接エンドポイントを通じてアクセスできません。
モノリスは通常のモノリスプロセスに従って、すべてのデータリクエストの認証と認可を行います。
DIP は内部通信にのみ使用され、すべてのリクエストはモノリスによって事前承認されるため、DIP は Gitaly がすでに行っているのと同様に、gRPC 経由でモノリスと通信するための共有認証トークンを使用します。この共有認証トークンをローテーションする方法が必要です。.com での方法については Gitaly ローテーションランブックを参照してください。
DIP との間のすべてのリクエスト(内部ネットワークリクエストを含む)は、TLS または他の適切な暗号化方法を使用して暗号化される必要があります。クエリ API のデータフロー内に保存されたデータはすべて保存中に暗号化されなければなりません(たとえばキャッシュ)。
パフォーマンス
クエリ時間を短縮し、データ取得全般を最適化するために、ClickHouse の事前集計されたマテリアライズドビュー(MV)をできる限り活用します。このアプローチは、データの複雑な結合を SELECT 時から INSERT 時に移動させます。ClickHouse は JOIN よりも大きなテーブルで良いパフォーマンスを発揮する傾向があります。
ClickHouse のデータマージの非同期性のため、クエリされたデータの正確性を確保するために、クエリには GROUP BY または FINAL を使用する必要があります。
各リソースは、過度なクエリ時間を避けるために適用されなければならない制限をドキュメントで文書化しなければなりません。リソースは、これらの制限が特定のクエリによって超過されないことを検証しなければなりません。クエリがこれらの制限を超えようとする場合、理由を含む 429 RESOURCE_EXHAUSTED エラーを返さなければなりません。たとえば、リソースは最大 30 日間のクエリしかサポートできませんが、クエリが 60 日間をリクエストする場合などです。
レート制限と IP ブロッキング
GraphQL および REST API については、既存の GitLab フレームワークを通じて実行されるため、既存のレート制限と IP ブロッキング機能を活用する必要があります。
レート制限ヘッダー(RateLimit-*)は、クエリが遅くなっているかどうか、または顧客が API リクエストを自動化しているかどうかをフロントエンドが管理/通知するために API リクエストで返さなければなりません。定義されたレート制限を超えるリクエストは 429 RESOURCE_EXHAUSTED ステータスコードを返す必要があります。
gRPC API については、レート制限を定義する代わりに、並行制限を使用することを推奨します。理想的には、これは適応的で、特定のデータソースが過負荷になっているときにリクエストを自動的にバックオフする必要があります。各制限はデータソースごとにカスタマイズ可能である必要があります。各データソースは異なる制限があるためです。
メトリクスとログ
Protobuf API が既存のオブザーバビリティインフラと統合されていることを確認しなければなりません。すべてのログは Kibana に送られなければならず、フロントエンド GitLab 使用エラーとパフォーマンスは Sentry に送られなければなりません。
ログは不必要な個人識別情報、シークレット、またはキーを保存してはなりません。すべての新しいログ呼び出しは、ログにリークしてはならない情報をリークしていないかチェックしなければなりません。
ClickHouse クエリはプレースホルダーを ? で置き換えたリダクトされた形式でログに記録されなければなりません。クエリログには、類似したクエリを簡単に比較・検索するためのクエリのハッシュが含まれなければなりません。
エラーはエラーバジェットに貢献しなければなりません。これにより、時間の経過とともに改善を監視できます。
使用状況を追跡するために内部アナリティクスとどのように緊密に統合できるかを調査しなければなりません。フロントエンド GitLab 使用状況にメトリクスを追加しますが、DIP との統合はフィザビリティを確認するために調査が必要です。またはイベント送信のためのセカンダリ API を設計する必要があるかもしれません(サービス Ping またはイベントトラッキング API?)。
メトリクスは Prometheus に送られなければなりません(以下に限らない):
- API レスポンス時間
- API アップタイム
- リソース使用量
- スロークエリ
- 高コストのクエリ
ページネーション
上記に概説したように、可能な場合はキーセットベースのページネーションを使用しなければなりません。集計クエリについては完全なクエリを返す必要がありますが、集計クエリ用に事前定義された MV を構築し、時間の経過とともにメトリクスを使用してこれを監視することで、パフォーマンスの懸念をある程度軽減できます。
ドキュメント
Protobuf API への接続と使用方法を説明するクイックスタートガイドを作成しなければなりません。このドキュメントは DIP の知識が限られているユーザーを対象としています。ドキュメントにはデータのフローと各部分に責任を持つチームを明確に概説しなければなりません。
スキーマの自動化と連携して、すべての制限とパラメーターとともにスキーマの詳細を docs.gitlab.com に公開する必要があります。
特定のリソースの MV を作成する方法と、クエリ時間とパフォーマンスを向上させるためにこれらを DIP 内でどのように使用するかについてのガイドを作成しなければなりません。
.com/dedicated/cells/セルフマネージドに関する考慮事項
この API のクエリは複数の Cells にまたがることはありません。各クエリはインスタンス(セルフマネージドインスタンスの管理者ユーザーのみ)、組織、名前空間、グループ、またはプロジェクトにスコープされなければなりません。
DIP のコア要件の 1 つは、Gitaly と同様に GitLab インスタンスの一部としてデプロイされることです。そのため、すべての顧客は DIP に完全にアクセスできる必要があります。
c955a93f)