データインサイトプラットフォーム
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| ongoing | ankitbhatnagar | ahegyi | ghosh-abhinaba | section analytics | 2025-04-10 |
概要
データインサイトプラットフォーム(Data Insights Platform)は、GitLab 全体で生成された分析データストリームを取り込み、処理し、永続化してクエリするための統合抽象化であり、製品全体のビジネスインサイトを計算する能力を実現します。
集中型データプラットフォームを構築する動機は、プロダクト使用データ統合ワーキンググループ内での作業から生まれています。そこで私たちは、GitLab 全体で生成された分析およびプロダクト使用データの収集に関する現在の複数の方法を、いくつかの主要な目標を持つ単一の統合された抽象化に統合する必要性を確立しました:
- 分析固有の機能の複数の部分を 1 つのまとまりのある製品機能に縫い合わせ、単一の抽象化/システムによってバックアップされるようにします。
- すべての分析データを集中型のスケーラブルな処理・クエリユニットに取り込む能力を構築し、ステークホルダーの使いやすさを損なわないようにします。
動機
製品内での構築
- プラットフォームのコア設計原則は製品内に構築することです。外部依存関係はゼロで、Gitaly などの既存のサービスと同様に GitLab/GDK との深い統合を実現します。
- GitLab インスタンスを実行するすべての環境(
.com、Dedicated、セルフマネージド)でのプラットフォームの可用性を確保します。プラットフォームの設計は、Cells に対してクラスターインスタンスのデプロイも許容する必要があります。
効率化されたユーザーエクスペリエンス
- プラットフォームのユーザーまたは開発者から不必要な複雑さを抽象化します。プラットフォームは、エンドユーザーが分析データを収集して収集後にクエリ/処理する必要があるたびに車輪を再発明する必要なく、宣伝された機能を実行する必要があります。
機能の統合
- 開発者が新しい機能を追加するために必要な作業を最小化しながら、任意のアナリティクス関連のイベント発行システム/機能を同じ論理的抽象化の下に統合します。
プロダクションレディ
- プラットフォームが安全で、スケーラブルで、信頼性があり、将来にわたって保守可能であることを確保します。
将来を見据えた実装
- プラットフォームが依存関係を変更できるように十分にモジュール化されていることを確保します。
- 取り込まれたすべてのデータを、製品のニーズに応じてテクノロジースタック全体の複数のシステムにルーティングできることを確保します。
目標
さまざまなイベント収集メカニズムを統合し、サポートするインフラストラクチャおよび/またはシステムをシンプルにします。ワーキンググループからの以下のアーキテクチャ設計記録(ADR)での決定に沿います:
集中型データプラットフォームの存在は、完全なデータライフサイクルを念頭に置いた以下の主要な成果を実現するのに役立ちます:
- 統一されたデータ収集とストレージ。
- システム間の効率的なデータ移動。
- セキュアなデータアクセスとガバナンス。
- データのビジュアライゼーションと探索。
データの統合とインサイトに関する最新のアップデートでは、これらの詳細が説明されています。
- 広い意味では、プラットフォームは製品内でのイベント駆動型プラットフォームの構築のための道を開くことができるようにする必要があります。
提案
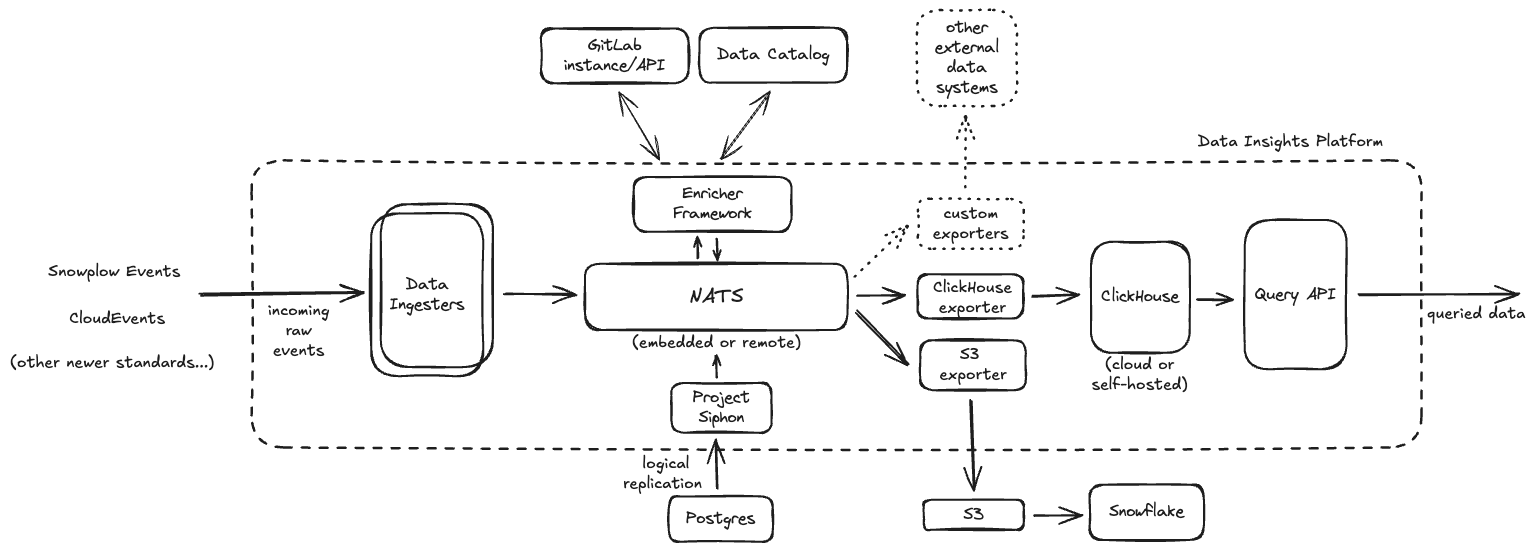
データインサイトプラットフォームは、スケーラブルなデータパイプラインを構造的に形成するために一緒に機能するコンポーネントのセットで構成される論理的抽象化であり、大量の分析データを取り込み、処理し、指定されたデータストアに永続化し、そこから効率的にクエリできるようにします。
以下は各基礎コンポーネントの簡単な説明です。また、各コンポーネントの詳細を確認し、より広い視聴者から貴重なフィードバックを収集するために、これらの一部に対して個別に_アーキテクチャブループリント_を作成しました。
インジェスター(Ingester): サポートされているイベントタイプの単一の取り込みメカニズム。開発環境でのローカル実行と、本番環境でのクラスターとしての実行の両方が可能です。このレイヤーは意図的にステートレスで、大量のデータを取り込むための水平スケーリングが可能です。以下のイベントタイプの取り込みサポートを構築することを目指します:
- Snowplow (現在のイテレーション)
- CloudEvents (次のイテレーション)
- サービス Ping (将来のイテレーション)
Siphon: Postgres から ClickHouse などの他のシステムへデータを論理的に複製するカスタムのインハウス変更データキャプチャ(CDC)実装。
NATS: 処理/エンリッチメント前に受信データをバッファリングする組み込み/分散システム。
エンリッチメントフレームワーク: GitLab API やメタデータ用のデータカタログなどの外部コンポーネントと通信する機能で受信データをエンリッチするカスタムフレームワーク。
- サポートされているエンリッチメントには、取り込まれたデータの機密部分の仮名化やリダクション、PII 検出、クライアントのユーザーエージェント文字列の解析などの操作が含まれます。
エクスポーター: 取り込まれたデータを指定された永続ストアに送るためのカスタム実装。さらなるクエリ/処理のために。
- ClickHouse エクスポーター: ClickHouse はプラットフォームによって取り込まれたすべての分析データを永続化し、
クエリ APIを使用してクエリするための指定の永続データベースです。 - S3/GCS エクスポーター:
S3/GCSにデータを送ることで、Snowflake と Tableau を使用した現在の分析クエリワークフローを支える Snowflake にデータを送ることができます。
- ClickHouse エクスポーター: ClickHouse はプラットフォームによって取り込まれたすべての分析データを永続化し、
ClickHouse: プラットフォーム内で取り込まれたすべての分析データの耐久性のある永続化と高度な OLAP クエリ機能を可能にする外部永続データベース。
クエリ API: ClickHouse 内に永続化されたデータをクライアント/UI がクエリするためのカスタムのセマンティッククエリレイヤー。
特定されたユースケース
以下は製品内に集中型データプラットフォームが存在することで恩恵を受けるユースケースの詳細なセットです。
| チーム/エリア | ユースケース | 予想されるスケール |
|---|---|---|
| エンタープライズデータ/インフラ | Postgres からデータを論理的に複製する。 | 1時間あたり Postgres から約 100GB の新しいデータが取り込まれます。また、Cells アーキテクチャと共にスケールする必要があります。 |
| プラットフォームインサイト | 大量の分析データをリアルタイムで取り込み・処理し、ClickHouse に永続化する。 | プロダクト使用データ:1200 イベント/秒(1日1億件)、約 15GB/時間、インストルメンテーションの増加とともに増加が予想される + 顧客ドメインからのイベントレベルデータ収集を追求する場合は 2.5 倍(1日約 3億件)。 |
| 機械学習 | GitLab データからイベント/特徴を抽出・処理して、スケールで ML モデルのトレーニング/テストデータセットを作成する。 | |
| セキュリティ & コンプライアンス | 監査イベントなど、GitLab データからイベントを抽出してほぼリアルタイムで対応する。 | データベースに保存された監査イベント/日(ストリーミング専用監査イベントを除く)- 1日あたり約 60万件のレコードが作成されます_(イベントパイプラインに移行した場合は増加する可能性が高い)_ 1日あたり生成されるストリーミング専用監査イベント(DB に保存された監査イベントを除く)- 1日あたり約 3,500万件のストリーミング専用イベントが作成されます。 合計見積もりは__1日あたり約 4,000万件のイベント__になります。Kibana ダッシュボード(内部)を参照してください。 |
| プロダクト | データ、イベント、タスクを非同期処理するための汎用イベントプラットフォーム。サービスとしてのウェブフック経由での外部データの取り込みと処理。 | |
| プロダクト | ClickHouse 上でリアルタイムアナリティクス機能を実装する。 | データ量:PostgreSQL データベースで観察されるものと同様またはそれ以下。複製(Siphon)するテーブルの数によって異なります。キューに入れられたイベント数:CDC イベントをパッケージにバッチ処理しているため、大幅に低くなります。 |
| Plan | JIRA 競合戦略 | |
| Optimize | JIRA データの取り込み | |
| Fulfillment | Dedicated ホステッドランナーの消費課金 |
デプロイ
データインサイトプラットフォームをすべての GitLab インストールで利用可能にするため、以下のデプロイメントモデルに対する必要なサポートを構築することを目指します:
| デプロイタイプ | 提案されるトポロジー |
|---|---|
| GDK | インストールのローカルで実行 |
.com | 1つ以上の専用クラスター |
| Cells | Cells トポロジーに応じた 1つ以上のクラスター |
| Dedicated | インスタンスごとに 1つの専用クラスター |
| セルフマネージド | ディストリビューション/インスタンスのサイジングに応じたスタンドアロンクラスター |
ロールアウトロードマップ
| 成果物 | タイムライン | 説明 |
|---|---|---|
| プリステージング/テスト | FY26Q1 | このプロジェクトを使用して GKE にデプロイ済み。 |
.com ステージング | TBD | - |
.com プロダクション | TBD | - |
| Dedicated への段階的ロールアウト | TBD | - |
| セルフマネージドへの段階的ロールアウト | TBD | - |
今後の機会
- 顧客を含む外部との分析データの共有。取り込まれたまたはエンリッチされたデータとそこから得られたインサイトは、SAFE フレームワーク内で許可された範囲ですべてのステークホルダーと共有できます。
- ビジネス継続性に関するインサイトとメトリクスをより迅速に生成する能力。
- 製品の分析部分間の柔軟/疎結合を構築し、将来のビジネスニーズが変わった場合にコンポーネントを切り替え可能にします。
- GitLab 全体の AI イニシアティブを強化するためのスケーラブルなデータ取り込みパイプライン。たとえば、RAG 取り込みパイプラインを支援します。
- GitLab で実行中のソフトウェアシステムから運用インサイトを収集します。既存の提案は提案:GitLab オブザーバビリティコンポーネント - 構造化イベントにあります。
設計と実装
モノリシック実装
- プラットフォームは単一プロジェクト(Go 使用)内で開発する必要があります。
- プラットフォームはスタンドアロンで実行でき、ローカル開発のために GDK とうまく統合できる_単一バイナリ_として開発・パッケージ化される必要があります。
- プラットフォームは分散方式での実行もサポートする必要があります。必要に応じて複数サービスデプロイメントとしてスケールアウトできます。実装では、各サービスが独立したスケーラビリティのために独自のコンピュートプールで独立して実行できるように、フラグを使用して複数のサービスに分解できるようにする必要があります。
NATS + JetStream を集中型データバッファとして使用
- NATS はアプリケーション内に組み込むことも、必要に応じてクラスターとしてスケールアウトすることもできるため、プラットフォームを実行することを決定したすべてのリファレンスアーキテクチャ全体に NATS クラスターをデプロイすることが NATS によって簡単になります。
- NATS がプラットフォームのデータバックボーンを形成することで、以下が容易になります:
- 複数のイベントソースからデータを取り込むことができます
- システム間でデータを送ることなく、集中的かつ動的に処理・エンリッチできます
- 必要に応じて他のデータ関連システムにルーティングできます。
外部依存関係の最小化
- ClickHouse が唯一の直接ストレージ依存関係であることで、GDK 内で完全にローカルですべての分析機能を開発・テストすることが可能になります。
共通標準のサポート
- 統合イベントインストルメンテーションレイヤー経由の構造化/トラッキングイベント用の Snowplow。
- カスタム構造化イベント用の CloudEvents。
今後は、サービス Pingなどの現在使用されている他のフォーマットを取り込むか、上記のサポートされている共通標準のいずれかで再モデリングできるようにする必要があります。
アーキテクチャ
上の図に示すように、プラットフォームは基本的に、データを取り込み、処理し、1つ以上の永続的なデータストアに耐久的に永続化できるスケーラブルなデータパイプラインを形成するために一緒に機能する複数のコンポーネントの構成です。図から、データの取り込みは インジェスター から始まり、設定されたパーティショニングおよび/またはデータ保持ポリシーに従って 1つ以上の NATS ストリーム にプッシュされます。次のステップでは、エンリッチャーフレームワーク が必要に応じてデータをデキューし、設定されたすべてのエンリッチメントを実行して 1つ以上の指定された NATS ストリーム に書き戻します。その後、設定された エクスポーター がエンリッチされたデータを NATS から取り込み、1つ以上のダウンストリームデータストアに送ります。ここでデータの必要なファンアウトが発生します。すべてのエンリッチされたデータを単一のソースから、そのデータが必要とされる可能性があるシステムに移動させます。すべてのデータのクエリはこれらのデータストアおよび/またはシステムから実行できます。
データストリームのプロデューサーとコンシューマーの間に NATS を配置することで、両者を切り離し、独立してスケールできるようにします。データ取り込み時のデータ量が処理および/または耐久的に永続化できる量よりはるかに高くなる場合があるためです。このアーキテクチャはまた、関係するコンポーネントの健全性に影響を与えることなく、パイプライン内のバックプレッシャーの処理にも対応します。すべてのデータ取り込みが高パフォーマンスであることを意図しており、一方でデータのダウンストリーム処理またはエクスポートは、ダウンストリームシステムおよびその運用能力に応じてより規制された方法で非同期に行われます。
セキュリティ
以下のセクションでは、プラットフォームと取り込まれたまたはクエリされたデータのセキュリティを確保する方法を説明します。
認証と認可
- GitLab(モノリス)とプラットフォーム間のすべての内部通信は TLS を使用して暗号化される必要があります。
- プラットフォームのデータ取り込みおよびクエリエンドポイントについては、ほとんどの認証と認可の決定を GitLab(モノリス)自体に委ねることを意図しています。データを取り込む際、すべてのイベントは Rails アプリケーション内の
イベントフォワーダー実装を使用してエンドポイントに転送されます。データをクエリする際、すべてのリクエストもモノリスによって事前承認され、GitLab 内の対応するサービスは(Gitalyと同様に)プラットフォームと通信するための共有トークンを使用します。 - NATS との内部インタラクションは必要に応じて認証と認可が行われます。
- ClickHouse との内部インタラクションも必要に応じて認証と認可が行われます。
暗号化
- NATS 内の保存中のデータはファイルシステム暗号化を使用して暗号化されたままになります。
- ClickHouse に永続的に保存されたデータも暗号化されたままになります。ClickHouse Cloud の場合、適宜透過的データ暗号化(TDE)または顧客管理の暗号化キー(CMEK)から開始できます。
監査とログ記録
- 私たちが管理する環境では、すべてのプラットフォームコンポーネントのログは適宜集中型ログに送られる必要があります。
運用
単一バイナリ実装により、プラットフォームの各コンポーネントを個別にスケールアウトできます。必要に応じて、インジェスター、エンリッチャー、エクスポーターのそれぞれを分離したノードプールでスケールおよび実行できます。- 内部的には、受信データを N 個の distinct な
NATS ストリームにシャードし、エンリッチャー/エクスポータープロセスの複数のインスタンスによって消費されるようにします。
スケーラビリティ
- テストインスタンスでは、以下の設定を実行しました:
"--replicas=5",
"--streams=5",
"--enricher-workers=10",
"--flush-batch-size=1000",
"--flush-interval-seconds=10",
c2d-standard-16 タイプの各ノードを持つ GKE クラスター上で 5 レプリカのステートフルセット(各 2 vCPU、2GB メモリ)を実行する 単一バイナリ に対して、__取り込み時に毎秒約 6000 件の Snowplow イベントを取り込み、エンリッチし、ClickHouse に永続化することができ、ClickHouse への着地は毎秒約 1600 件__でした。
GitLab の現在の Snowplow インフラストラクチャの運用経験から、プラットフォームの最初のイテレーションはピーク時に 1 分あたり最大 100 万件のイベントで 1 日あたり最大 5 億件のイベントをスケールして処理できることを意図しています。インフラストラクチャのフットプリントの観点から、現在のトラフィック量を現在より合理的に少ないリソースで処理することを目指しています。
Siphon も__PostgreSQL が現在のボトルネックとなりながら、毎秒約 5700 件の論理レプリケーションイベントをレプリケートできることが確認されています__。Siphon のパフォーマンステストの詳細はこの Issueで確認できます。これらのテスト中に基盤となる NATS クラスターのフェイルオーバーもテストし、NATS サービスが回復するとすぐに完全なデータセットが正常に回復しました。
単一の_クラスター_は上のアーキテクチャ図で説明されているように、プラットフォームの最上位のデプロイメントユニットです。必要に応じて、スケールおよび/またはクラスターごとのテナント分離に対応するために、1つ以上のプラットフォームクラスターをデプロイできます。たとえば、セルフマネージドまたは Dedicated GitLab インスタンスからデータを取り込む場合、あるインスタンスのトラフィック量が別のインスタンスのリソースに干渉しないよう、異なるプラットフォームクラスターにルーティングできます。
監視
- 内部で開発されたコンポーネントに対しては、十分なインストルメンテーションを追加して Prometheus メトリクスとしてテレメトリを公開する必要があります。
- 私たちが管理する環境では、すべてのプラットフォームコンポーネントのメトリクスを適宜内部監視バックエンド(Mimir)に送り、内部ダッシュボードに追加する必要があります。
c955a93f)