Read-Mostly データ
Read-Mostly データ
このドキュメントでは、データベーススケーラビリティ ワーキンググループで導入された read-mostly パターンについて説明します。Read-Mostly データの特性を議論し、このコンテキストで GitLab 開発者が考慮すべきベストプラクティスを提案します。
Read-Mostly データの特性
名前が示すとおり、read-mostly データとは更新よりも読み取りがはるかに多いデータのことです。更新・挿入・削除による書き込みは、このデータの読み取りと比べて非常にまれな出来事です。
さらに、このコンテキストでの read-mostly データは通常小さなデータセットです。大きなデータセットは「一度書き込んで何度も読む」という特性を持つことも多いですが、ここでは明示的に扱いません。
例: ライセンスデータ
標準的な例を紹介しましょう: GitLab のライセンスデータです。GitLab インスタンスは、GitLab のエンタープライズ機能を使用するためにライセンスが付与されている場合があります。このライセンスデータはインスタンス全体で保持されます。つまり、通常は少数の関連レコードしか存在しません。この情報は非常に小さなテーブル licenses に保持されています。
これを read-mostly データと見なすのは、上記の特性に合致しているためです:
- 書き込みがまれ: ライセンスデータはライセンスを挿入した後、書き込みがほとんどありません。
- 読み取りが頻繁: エンタープライズ機能が使用できるかどうかを確認するために、ライセンスデータは非常に頻繁に読み取られます。
- 小さいサイズ: このデータセットは非常に小さく、GitLab.com では合計リレーションサイズが 50 kB 未満の 5 つのレコードしかありません。
スケール時のアプリケーションとデータベースへの影響
このデータセットは小さく頻繁に読み取られるため、データはほぼ常にデータベースキャッシュやデータベースディスクキャッシュに存在することが期待されます。したがって、read-mostly データの懸念は通常データベース I/O のオーバーヘッドではありません。ディスクからデータを読み取ることはほとんどないためです。しかし、高頻度の読み取りを考慮すると、データベースの CPU 負荷とデータベースのコンテキストスイッチという点でオーバーヘッドが生じる可能性があります。さらに、これらの高頻度クエリはデータベーススタック全体を通過し、データベース接続多重化コンポーネントとロードバランサーに追加のオーバーヘッドを引き起こします。また、アプリケーションはデータを取得するためのクエリの準備と送信、結果のデシリアライズ、収集した情報を表現する新しいオブジェクトの割り当てに時間を費やします—これらすべてが高頻度で行われます。
上記のライセンスデータの例では、ライセンスデータを読み取るクエリはクエリ頻度の点で特定されています。実際、ピーク時にクラスター全体で 1 秒あたり約 6,000 クエリ(qps)が観測されていました。当時のクラスターサイズでは、ピーク時に各レプリカで約 1,000 qps、プライマリで 400 qps 未満が見られました。この差異は読み取りをスケーリングするためのデータベースロードバランシングによるもので、純粋な読み取り専用トランザクションではレプリカが優先されます。
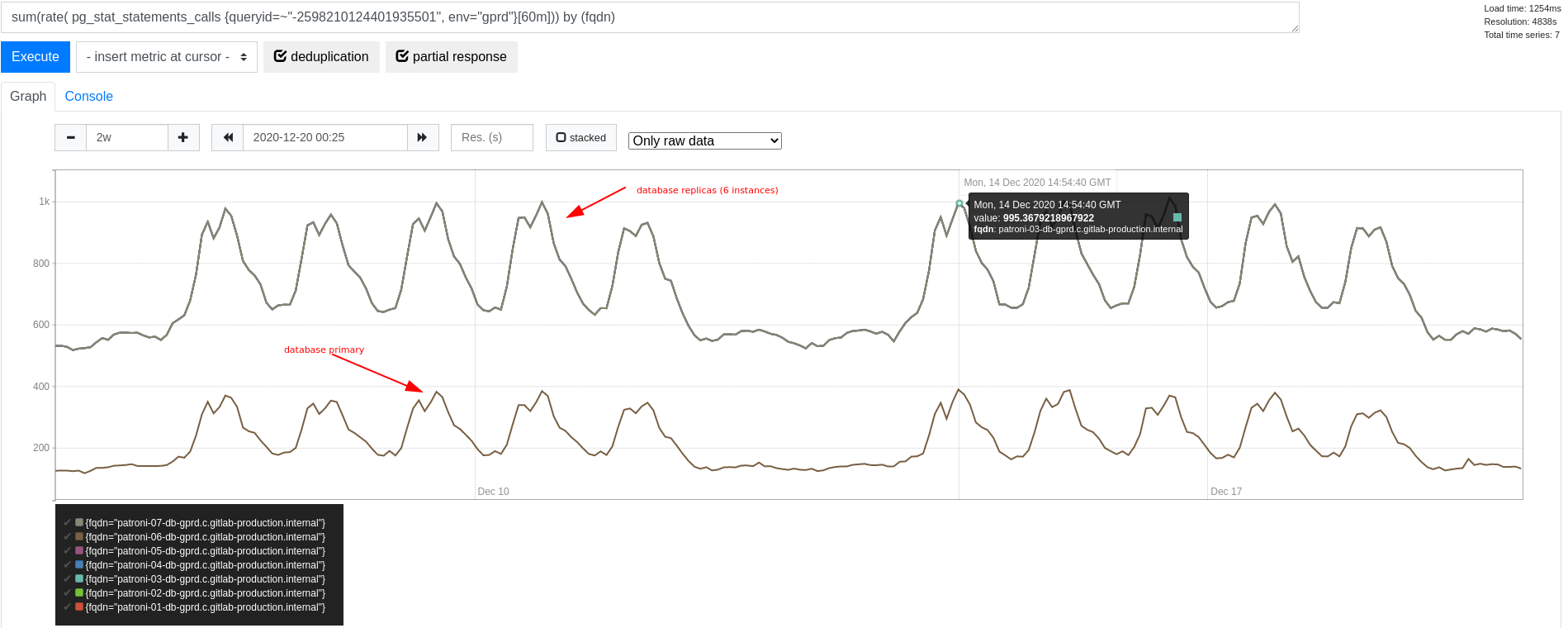
当時のデータベースプライマリ全体のトランザクションスループットは、1 秒あたり 50,000 から 70,000 トランザクション(tps)の間で変動していました。これと比較すると、このクエリ頻度は全体のクエリ頻度のほんの一部に過ぎません。しかし、コンテキストスイッチの観点では依然として相当なオーバーヘッドがあると予想されるため、可能であればこのオーバーヘッドを取り除く価値があります。
Read-Mostly データの識別方法
Read-Mostly データを識別することは、私たちの例のような明確なケースはあるものの、困難な場合があります。
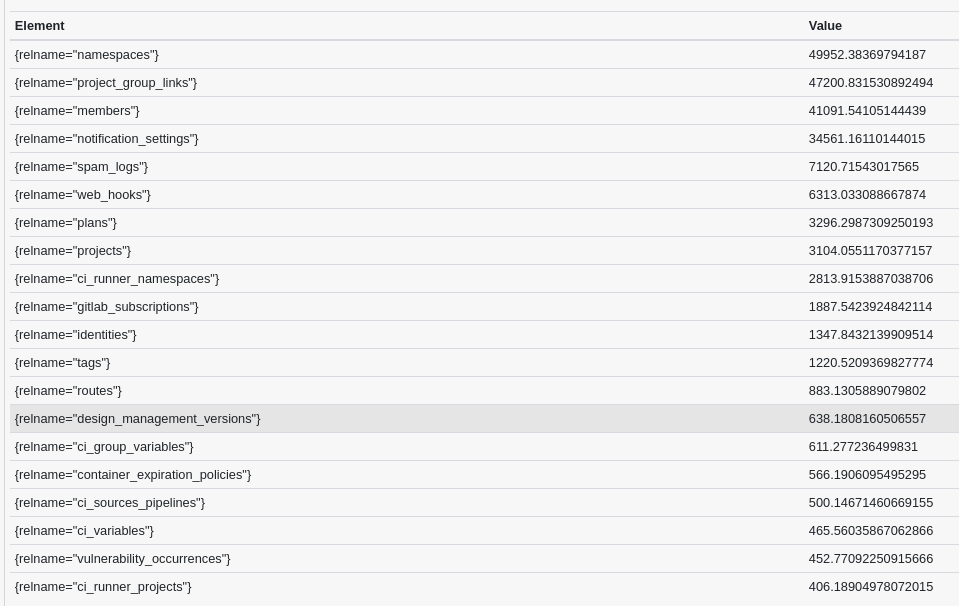
一つのアプローチは例えばプライマリの読み取り/書き込み比率と統計を確認することです。ここでは 60 分間の読み取り/書き込み比率による TOP20 テーブルを確認します(ピークトラフィック時に取得):
bottomk(20,
avg by (relname, fqdn) (
(
rate(pg_stat_user_tables_seq_tup_read{env="gprd"}[1h])
+
rate(pg_stat_user_tables_idx_tup_fetch{env="gprd"}[1h])
) /
(
rate(pg_stat_user_tables_seq_tup_read{env="gprd"}[1h])
+ rate(pg_stat_user_tables_idx_tup_fetch{env="gprd"}[1h])
+ rate(pg_stat_user_tables_n_tup_ins{env="gprd"}[1h])
+ rate(pg_stat_user_tables_n_tup_upd{env="gprd"}[1h])
+ rate(pg_stat_user_tables_n_tup_del{env="gprd"}[1h])
)
) and on (fqdn) (pg_replication_is_replica == 0)
)
これにより、データベースプライマリで書き込みよりも読み取りがはるかに多いテーブルの良い印象が得られます:
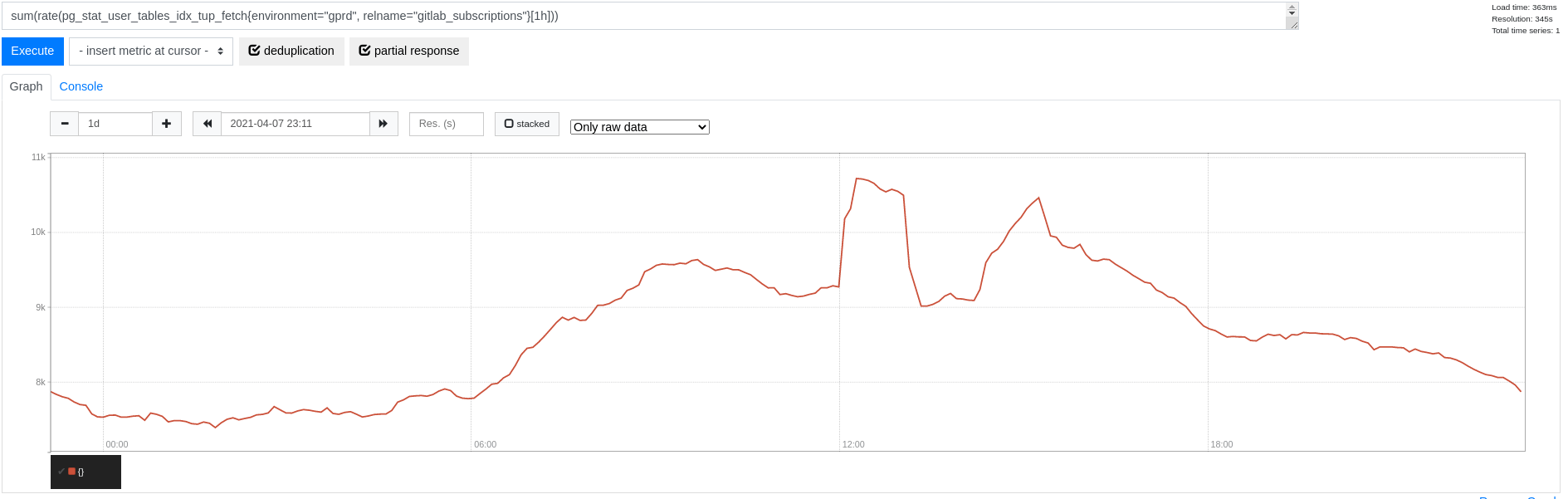
ここから例えば gitlab_subscriptions にズームインすると、インデックス読み取りがピーク時に全体で 1 秒あたり 10k タプルを超えることがわかります(シーケンシャルスキャンはありません):
テーブルへの書き込みは非常にまれです(シーケンシャルスキャンもありません):
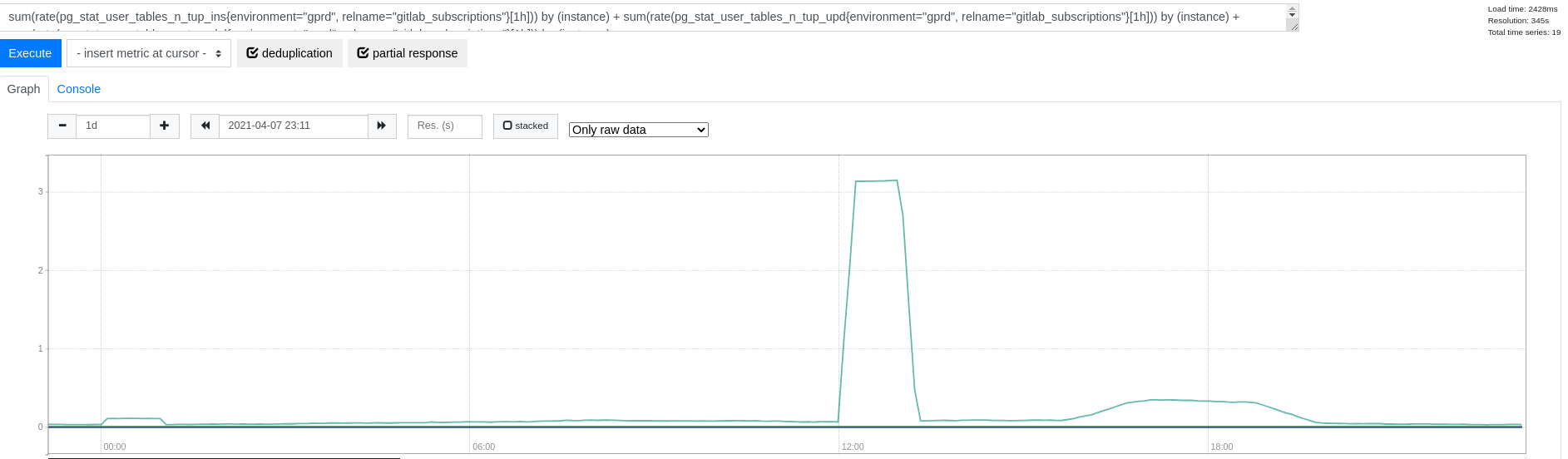
さらに、テーブルのサイズはわずか 400 MB です。そのため、このパターンで考慮すべき別の候補となる可能性があります(#327483 を参照)。
ベストプラクティス
キャッシング
データベースのオーバーヘッドを削減するために、データのキャッシュを実装し、データベース側のクエリ頻度を大幅に削減します。利用可能なキャッシングのスコープはいくつかあります:
RequestStore: リクエストごとのインメモリキャッシュ(request_store gem に基づく)ProcessMemoryCache: プロセスごとのインメモリキャッシュ(ActiveSupport::Cache::MemoryStore)Gitlab::Redis::CacheとRails.cache: Redis での本格的なキャッシュ
上記の例を続けると、リクエストベースでライセンス情報をキャッシュするための RequestStore がありました。しかし、これは依然としてリクエストごとに 1 つのクエリを引き起こしていました。1 秒間プロセス全体のインメモリキャッシュを使用してライセンス情報をキャッシュし始めたとき、クエリ頻度は劇的に低下しました:
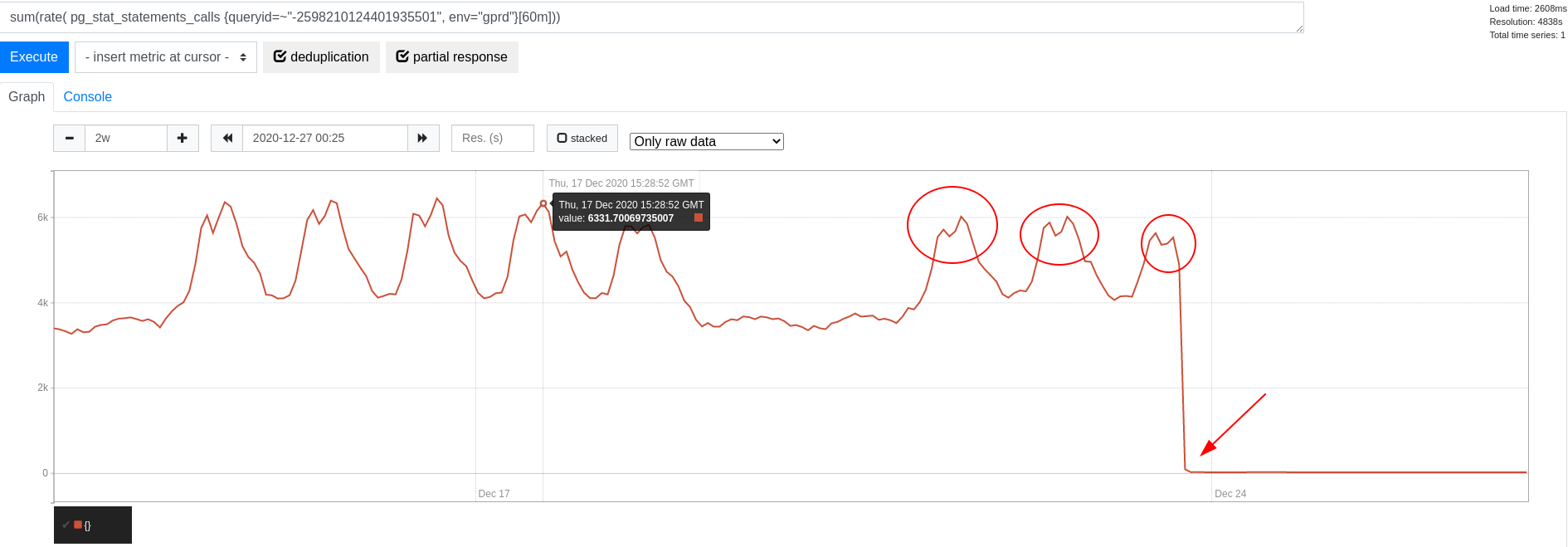
ここでのキャッシングの選択は、対象データの特性に大きく依存します。ほとんど更新されないライセンスデータのような非常に小さなデータセットは、インメモリキャッシングの良い候補です。プロセスごとのキャッシュは、キャッシュの更新レートを受信リクエストレートから切り離すため、ここでは有利です。
注意点として、現在の Redis セットアップは Redis セカンダリを使用せず、キャッシングに単一ノードに依存しています。そのため、負荷の増加による Redis の過負荷を避けるためのバランスを取る必要があります。比較すると、Postgres レプリカからデータを読み取ることは複数の読み取り専用レプリカに分散できます。クエリがデータベースに行く場合より高コストであっても、負荷はより多くのノードに分散されます。
レプリカからデータを読み取る
キャッシングの有無にかかわらず、可能な限りデータベースレプリカからデータを読み取ることも確認しなければなりません。これは多数のデータベースレプリカにわたって読み取りをスケールアップし、データベースプライマリから不必要な作業負荷を取り除くための取り組みを支援します。
GitLab の読み取り向けデータベースロードバランシングは、最初の書き込み後または明示的なトランザクションを開いた後はプライマリに固定されます。Read-mostly データのコンテキストでは、トランザクションスコープの外でこのデータを読み取り、書き込みを行う前に行うよう努めます。このデータが更新されることはほとんどないため(したがって若干古いデータを読み取ることを気にする必要がない場合が多い)、これは多くの場合可能です。しかし、前の書き込みやトランザクションのためにこのクエリをレプリカに送信できないことは明白でない場合があります。したがって、read-mostly データに遭遇した際は、より広いコンテキストを確認し、このデータがレプリカから読み取れることを確認するのが良い実践です。
まとめとフォローアップ
Read-Mostly データを定義し、その特性を上で説明しました。次に GitLab のライセンスデータの例、GitLab.com への影響、リクエストストアからプロセスごとのメモリキャッシュへのキャッシングレベルの向上の効果を確認しました。これにより、このデータのクエリ頻度が大幅に低下しました。Read-Mostly データのキャッシングの重要性と、このデータを可能な限りデータベースレプリカから読み取ることを確認することの重要性を説明しました。
今日利用可能なさまざまなキャッシング戦略があるにもかかわらず、一貫して便利に使用するための共通フレームワークがないことを認識しました。これは、このキャッシングを簡素化するためのキャッシングフレームワークを定義するための潜在的なフォローアップとして指摘されています。
また、単一ノード Redis キャッシュからの制限も認識しています。memcached が潜在的な代替として指摘されており、Rails は任意の数の memcached サーバーにわたるシャーディングのための組み込みサポートを持っています。
c955a93f)