Read-Mostly データ
Read-Mostly データのブループリント
| プロパティ | 値 |
|---|---|
| 作成日 | 2021 年 3 月 15 日 |
| 終了日 | 2022 年 7 月 18 日 |
| Slack | #wg_database-scalability(社内からのみアクセス可) |
| Google Doc | Working Group Agenda(社内からのみアクセス可) |
| Issue ボード | Sharding:Build Board |
このワーキンググループのチャーターは、データベースバックエンドストレージをスケーリングするための一連のブループリント・設計・初期実装を生み出すことです。これらの終了基準は、以下の高レベルの目標を達成するための道筋を示します:
これらは、さまざまなユースケースのアクセス・分離・同期・ライフサイクル管理の考慮事項を伴います(下記のスケーリングパターンを参照)。
| # | 開始日 | 完了日 | 基準 |
|---|---|---|---|
| 1 | 2021-03-25 | 2021-06-02 | データベーススケーリングパターンのブループリント(read-mostly、time-decay、sharding) |
| 2 | 2021-04-21 | 2021-06-03 | 水平シャーディングの評価と概念実証 |
| 3 | 2021-04-26 | 2021-06-10 | 分解(垂直シャーディング)の評価と概念実証 |
| 4 | 2021-06-11 | 2022-07-02 | gitlab.com への分解 CI データベースのロールアウト |
| 5 | 2022-07-05 | 2022-07-18 | ワーキンググループのクロージングタスク、コミュニケーション、クリーンアップ |
2022-07-02 に最終終了基準である gitlab.com データベースのメインと CI への分解を無事完了しました。
数週間の監視の後、サイトは安定しており、ヘッドルームの大幅な改善とサチュレーションの低下が見られます。分解による改善の追跡とレポートは、Issue CI Decomposition Performance Summary で継続して行います。
このワーキンググループはクローズしますが、GitLab のデータベースとアプリケーション全体のスケーラビリティ向上に向けた取り組みは終わっていません。このグループでの作業を引き継ぐ今後の優先事項には以下が含まれます:
| 推奨用語 | 意味 | 使用しない用語 | 例 |
|---|---|---|---|
| Case | スケーリングパターンのインスタンス | ci_builds、web_hooks_logs | |
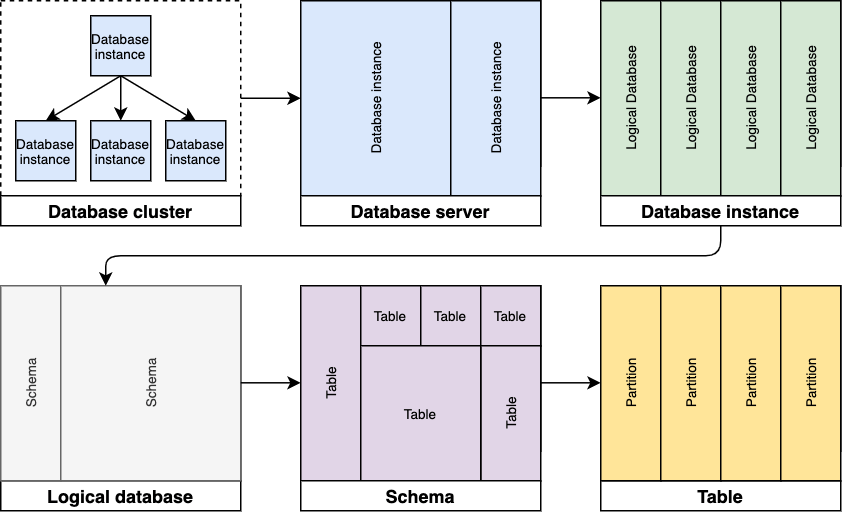
| Cluster | データベースクラスターとは、データをレプリケートする相互接続されたデータベースインスタンスの集合 | Patroni が管理する GitLab.com の PostgreSQL クラスター。メインの論理データベースをホストし、プライマリデータベースインスタンスとその読み取り専用レプリカで構成される。 | |
| Decomposition | 機能所有のデータベーステーブルが複数のデータベースサーバー上の多くの論理データベースに存在する。アプリケーションはさまざまな操作(ID 生成、再バランスなど)を管理する | Y 軸、垂直シャーディング | 別の論理データベースに格納されたすべての CI テーブル。設計図解 |
| Instance | データベースインスタンスは、データベースサーバーで動作する関連プロセスで構成される。各インスタンスは独自のデータベースプロセスセットを実行する | 物理データベース | |
| Logical database | 論理データベースはスキーマやテーブルなどのデータベースオブジェクトを論理的にグループ化する。データベースインスタンス内で利用可能で、他の論理データベースとは独立している | Database | GitLab の Rails データベース |
| Node | このワーキンググループの文脈ではデータベースサーバーと同義 | 物理データベース | |
| Replication | バイアスなしのデータレプリケーション | X 軸、クローニング | 現在のデータベースクラスターで行っていること |
| Scaling Pattern | データ分類に基づく汎用ソリューションで、複数のケースのスケーリングを可能にする | スプリットパターン | Read-Mostly、Time-Decay、Entity/Service |
| Schema | データベーススキーマは、テーブル・ビュー・インデックス・データ型・関数・ストアドプロシージャ・オペレーターなどの名前付きデータベースオブジェクトを含む名前空間 | ||
| Server | データベースサーバーは、1 つ以上のデータベースインスタンスを実行するオペレーティングシステムが動作する物理または仮想システム | 物理データベース | |
| Sharding | 顧客またはリクエスター単位のバイアス、またはアフィニティへのバイアスなしでリソース内でデータを分離する。シャーディングキー(例: トップレベルネームスペース)によるシャーディングで、データは複数のデータベースサーバー上の多くの論理データベースに分離される。アプリケーションはさまざまな操作(ID 生成、再バランスなど)を管理する | Z 軸、水平シャーディング | 各トップレベルネームスペースが独自の論理データベースに存在する。設計図解 |
| Table | データベーステーブルは、共通のデータ構造(各位置で同じ数の属性、同じ順序、同じ名前と型)を持つタプルの集合(出典) | ||
| Table Partitioning | パーティションテーブルのデータの一部を含むテーブル(水平スライス)(出典) | Partition | |
| Track | 1 つのスケーリングパターンに取り組む WG 内のサブグループ |
現在のアーキテクチャは、設計上ほぼ独占的に単一データベースに依存し、ストレージ・一貫性・クエリ結果のコレーションという点でデータの唯一の絶対的な管理者となっています。厳密に言えば、データベースバックエンドの負荷需要を処理するためにいくつかの物理的なレプリカにわたって実装された単一の論理データベースを使用しています(差分をオブジェクトストレージに保存するという単一の例外を除いて)。しかし、データベース負荷の定期的な分析は、プライマリ RW データベースサーバーが垂直スケーラビリティの限界に近づく高いピークを経験していることを示しており、このアプローチは持続不可能であることが明らかになっています。
私たちは昨年シャーディングを検討し、データベース層に限定しました。市場には利用可能なソリューションがありますが、財務面とプロダクト適合性の両面で私たちの要件を満たさなかったと結論付けました。それらは、製品の一部として出荷することが困難(もしくは不可能)なソリューションを強いられるものでした。
私たちは今、この問題に対する新しいイテレーションを開始しています。スコープをデータベース層からアプリケーション自体へと拡大します。私たちのニーズと要件を満たすためには、データベースに限定していては解決できないと認識しているためです。現実にするためにはアプリケーションへの慎重な変更を考慮しなければなりません。
データ管理の責任のほとんどをデータベースに委譲することで、PostgreSQL の優れた能力に依存してアプリケーションの需要に対処することが可能になりました。いくつかのスケーラビリティの制限に直面しましたが(infradev を通じて対処)、データベースはほとんどの場合、大量のハードウェアの助けを借りて持ちこたえてきました。これは特定の問題に対する具体的な修正を提供し、開発速度を確保しましたが、データベースが成長するにつれて長期的な問題を見逃してきました。スポット修正は GitLab.com の成長を維持するのに十分ではありません。これは今や ci_builds のような重大な技術的負債の Issue に反映されており、現在のスキーマと使用法はスケーリングを困難にしています。したがって、長期的で包括的なソリューションを提供するためにより戦略的な見解を持ち、本格的な規律としてのデータ管理を採用する必要があります。
規律としてのデータ管理は、即時のアプリケーションニーズを満たすための特定のスキーマ定義を超えて考えることを意味します。スキーマがスケール(パフォーマンスと使いやすさの両面)でどのように振る舞うか、特定のスキーマ定義に過剰な負荷をかけてリファクタリングが必要かどうか、成長と制限、各テーブルとそれに対して実行されるクエリに対する適切なオブザーバビリティ、スケーラビリティの制限(例: PK の成長)の予測についての長期的な理解を達成しなければなりません。
規律とスケーラビリティが重複するデータベースの領域があります。一般的に、規律を先に取り組み、スケーラビリティは後で取り組む必要があります。
データベースバックエンドのスケーリングを検討するにあたり、2 つの主要なトレードオフが意思決定を支配します:
さらに、データ移行戦略を発展・成熟させる必要があります。時間が経つにつれ、バックグラウンドで行われる場合でも移行の実施が困難になります。一部の移行はアプリケーション内のライブなアプリ内移行(例: テーブルを新しいスキーマに移行する場合、機会があるごとに行う必要があるかもしれません: レコードが読み取られたとき、新しいテーブルでルックアップが行われ、失敗した場合は古いテーブルでルックアップが行われ、結果はユーザーに返されると同時に新しいテーブルに移行されます)の一部になる必要があります。
私たちは意味・機能・使用法によってデータを分離することで機能分解を採用しなければならない段階にありますが、アプリケーションがデータベースバックエンドを単一のエンティティとして見続けられる方法で行う必要があります。これには、スタックに新しいデータベースエンジンを導入することを最小化しながら、データ管理の責任の一部を引き受けることが伴います。
私たちは単一アプリケーションの利点を認識し、できる限りスタックの深いところまで単一データストアのビューを維持したいと考えています。開発者にとって高度な柔軟性と低い抵抗を維持することが不可欠で、それが管理者とユーザーにとって一貫した体験に繋がります。そのために、アプリケーションの残りの部分がバックエンドデータストアにアクセスするために活用できるデータアクセス層を構築・導入する必要があります(これは GitLab にとって新しい概念ではありません。Gitaly の成功がそれを明確に示しています)。
データベースバックエンドのスケーリングを検討するにあたり、データ管理機能の唯一の実行者としてデータベースへのグローバルな依存はもはや不可能です。本質的に、責任の範囲は今やローカライズされており、アプリケーションはこれらの責任の一部を受け入れなければなりません。これらはアドホックな方法で実装することはできず、一方ではデータストレージを支援するさまざまなバックエンドを理解し、フロントエンドでは複雑なクエリを処理し、データベースの水平スケーリングで生じるレイテンシに対処するために必要なキャッシング機能を提供しながら、バックエンドの詳細をアプリケーションの残りの部分から隠すデータアクセス層に集中化すべきです。
データベースバックエンドが暫定的に提案されたスケーリングパターンを通じて分解されるにつれ、データアクセス層を実装する必要性が明らかになります。私たちはもはやデータベースがすべてのデータ合成の役割を果たすことに依存することはできません。アプリケーション自体(またはそれに代わるサービス)がこれらの責任を引き受けなければなりません。
データベーススケーラビリティに対して体系的かつ全体的にアプローチすることを確保する必要があります。データベースのスケーリングに対する断片的なアプローチを許可すべきではありません。そのため、問題を分解してさまざまなテーブルに適用できるソリューションを提供する少数のパターンを決定することを提案します。これにより、ソリューション空間を小さく、管理可能で、ある程度の柔軟性を持つものに保ちます。これらのパターンに適用可能なソリューションを理解したら、アプリケーションの残りの部分への混乱を最小化しながら、そのイテレーション開発を可能にするデータアクセス層について全体的に考えることができます。
頻繁に読み取られるが書き込みはほとんどなく、複雑なクエリにほとんど参加しない小さなデータの集まりがあります(例: license テーブル)。これらは高頻度の読み取りに適したより適切なバックエンドにオフロードすべきです(耐久性があると考える唯一のバックエンドはデータベースなので、最低限キャッシングの目的で)。クエリは単純でデータ量は少ないですが、これらのクエリはデータベースで大量のコンテキストスイッチを引き起こします。
詳細についてはブループリントを参照してください。
一部のデータセットは強い時間減衰効果の影響を受け、最近のデータが古いデータよりもはるかに頻繁にアクセスされるか、より価値があります。この効果は通常プロダクトおよびアプリケーションのセマンティクスに結びついており、このパターンを活用できる可能性があります。
以下のようなパターンを検討すべきです:
これらのパターンは組み合わせて使用することもできます。例えば、時間に基づいてパーティションを分割し、X ヶ月より古いパーティションを削除するといった方法です。
詳細についてはブループリントを参照してください。
一般的なデータベーススケーラビリティの手法の 1 つに、具体的なエンティティ(例: ユーザー)を別のデータストアに分解することがあります。このアプローチは通常マイクロサービスと関連しており、エンティティをサービスの背後にカプセル化することが有用な場合もありますが、特にアプリケーションのコンテキスト内では厳格な要件ではありません(前述のとおり、私たちはすでに Gitaly でこれを行っています)。
このアプローチは、データベースランタイムが外部依存関係を追跡できないため、一貫性の懸念をアプリケーションにシフトします。この戦略は、列データの一部を「メイン」データベースに整理して残し、残りのメタデータを別のバックエンドにオフロードできる場合に特に効果的です。
データベーススケーラビリティで最も広く使用されている手法の 1 つがシャーディングです。シャーディングは論理的なデータ一貫性とクエリ解決の要求をアプリケーションにシフトさせるため、設計の選択においてCAP 定理の重要性を大幅に高め、実装が最も困難な手法の 1 つでもあります。今日の CAP 効果は無視できるほどです: レプリケーションの遅延はありますが、非常に小さいため無視できます。これらは解決が困難な問題ではありませんが、解決可能です。
CAP 定理の関連性を掘り下げるにあたり、シャーディングの文脈以外でも考慮すべきです。これは @andrewn がデータベースの垂直スケーラビリティについて議論した最近の会話で具体化したポイントです。この文脈では、完全なトランザクション同期性の必要性を評価し、可能な限り非同期モードに移行することを検討すべきです。
特定の命名規則を確立することが重要です。現在、シャーディングに関する議論が多くありますが、それはこの方程式の一部であり、すべてではありません。したがって、データベーススケーラビリティ、Y 軸スプリット等について適切に話し合うよう心がけましょう。
| ワーキンググループの役割 | 担当者 | 役職 |
|---|---|---|
| エグゼクティブステークホルダー | Eric Johnson | Chief Technology Officer |
| ファンクショナルリード | Kamil Trzciński | Distinguished Engineer, Ops and Enablement (Development) |
| ファンクショナルリード | Jose Finotto | Staff Database Reliability Engineer (Infrastructure) |
| ファシリテーター/DRI | Nick Nguyen | Sr. Engineering Manager, Datastore |
| DRI - Ops セクション | Sam Goldstein | Director of Engineering, Ops |
| DRI - インフラストラクチャ | Steve Loyd | VP of Infrastructure |
| メンバー | Gerardo “Gerir” Lopez-Fernandez | Engineering Fellow, Infrastructure |
| ファンクショナルリード | Fabian Zimmer | Group Product Manager, Enablement |
| メンバー | Stan Hu | Engineering Fellow |
| メンバー | Andreas Brandl | Staff Backend Engineer, Database |
| メンバー/CICD データモデル DRI | Grzegorz Bizon | Staff Backend Engineer (Time-decay data ci_builds ) |
| メンバー | Christopher Lefelhocz | Cleaner |
| メンバー | Chun Du | Director of Engineering, Enablement |
| メンバー | Adam Hegyi | Senior Backend Engineer, Manage |
| メンバー | Tanya Pazitny | Quality Engineering Manager, Enablement & Secure |
| メンバー | Nick Westbury | Senior Software Engineer in Test, Geo |
| メンバー | Nailia Iskhakova | Senior Software Engineer in Test, Distribution |
| メンバー | Grant Young | Staff Software Engineer in Test, Memory |
c955a93f)